[论文][表情识别]Suppressing Uncertainties for Large-Scale Facial Expression Recognition
Suppressing Uncertainties for Large-Scale Facial Expression Recognition
论文基本情况
- 发表时间及刊物/会议: 2020 CVPR
- 发表单位:ShenZhen Key Lab of Computer Vision and Pattern Recognition, SIAT-SenseTime Joint、中国科学院大学、新加坡南洋理工
问题背景
大规模表情识别中可能会出现部分标注不准确的图片,错误标签会带来以下三种危害: (1)模型容易在错误标注上过拟合 (2)错误的标注不利于模型学习表情特征 (3)错误的标注容易导致早期阶段训练不收敛
论文创新点
通过Self- Cure Network(SCN) 来解决数据集标注不准确的问题, 具体分析如下: (1)SCN结构中的注意力机制给予标注不准确的图片更低的权重, 并通过Rank Regularization loss将所有图片分为高注意力组和低注意力组两组。 (2)SCN中relabel机制尝试给予“标注不正确”(模型认为不正确)的图片“正确”(模型认为正确)的标签。
网络结构
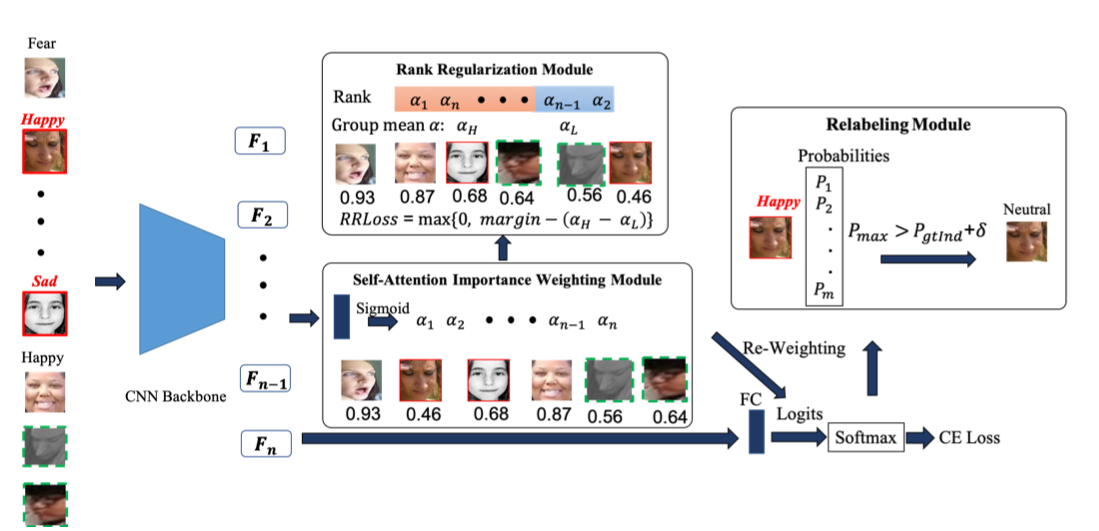
网络结构主要分为以下三个部分: (1) self-attention importance weighting (2)ranking regularization (3)relabeling
self-attention importance weighting
- SCN使用ResNet18作为backbone,并将ResNet18在最后全连接层之前提取到的特征送入 self-attention importance weighting模块。公式(1)中的$x_i$表示第$i$张图片在全连接层之前的特征,$\sigma,W$分别表示sigmoid激活函数和注意力机制中全连接层的参数 。$\alpha_i$表示得到的注意力权重。
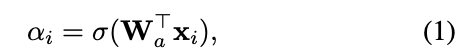 个人认为,$W$和$x_i$相乘后,值越大,代表所提取到的特征越显著,“uncertainty”越小,而将特征再通过sigmoid激活函数,将所有的特征值归为0~1之间,便于更好的比较不同特征的重要性。
个人认为,$W$和$x_i$相乘后,值越大,代表所提取到的特征越显著,“uncertainty”越小,而将特征再通过sigmoid激活函数,将所有的特征值归为0~1之间,便于更好的比较不同特征的重要性。 - 在 self-attention importance weighting结构中,SCN使用公式(1)所得注意力权重作为各个特征重要性的参考,以此作为权重衡量各个loss的重要性。因此,该网络的损失函数如下:
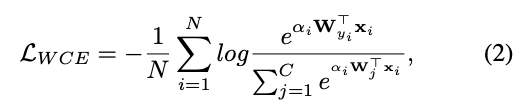 (关于这种loss函数的使用,可参考如下论文:
[1] Wei Hu, Yangyu Huang, Fan Zhang, and Ruirui Li. Noise- tolerant paradigm for training face recognition cnns. In CVPR, pages 11887–11896, 2019
[2] Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. Sphereface: Deep hypersphere embedding for face recognition. In CVPR, pages 212–220, 2017. )
(关于这种loss函数的使用,可参考如下论文:
[1] Wei Hu, Yangyu Huang, Fan Zhang, and Ruirui Li. Noise- tolerant paradigm for training face recognition cnns. In CVPR, pages 11887–11896, 2019
[2] Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. Sphereface: Deep hypersphere embedding for face recognition. In CVPR, pages 212–220, 2017. )
ranking regularization
此模块主要是根据self-attention importance weighting结构中得到的注意力权重按照高低次序排序,并根据比例(此比例为超参数)将全部图片分为高注意力和低注意力两组,我们希望,高注意力组和低注意力组的注意力权重差别超过一定阈值(此阈值为超参数),因此设计了rank regularization loss(RR Loss),类似hinge loss的思想。
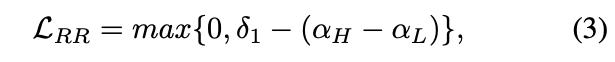
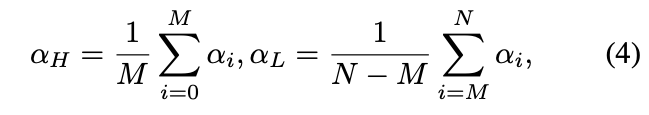 其中,N表示所有图片的张数,M是高注意力组图片张数。
总损失函数为$L_$和$L_$的加权和。
其中,N表示所有图片的张数,M是高注意力组图片张数。
总损失函数为$L_$和$L_$的加权和。
relabeling
SCN网络对低注意力组中的部分图片进行重新标注,使得数据集标注更准确。
纠正标签的机制如下所示,网络预测的结果经过softmax后为一个概率分布,取概率最大的类别作为预测标签。如下公式中,$P_$表示网络预测结果最大的概率,对应的类别为$l_$,$P_$表示真实标签$l_$对应的概率,当网络预测结果最大的概率超过真实标签对应的概率一定值时(此阈值为超参数),SCN认为此时真实标签是有误的,因此,在后续训练中,使用网络预测结果最大的概率对应的标签作为真实标签。相当于修正了数据集。
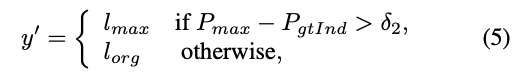 ##实验结果
##实验结果
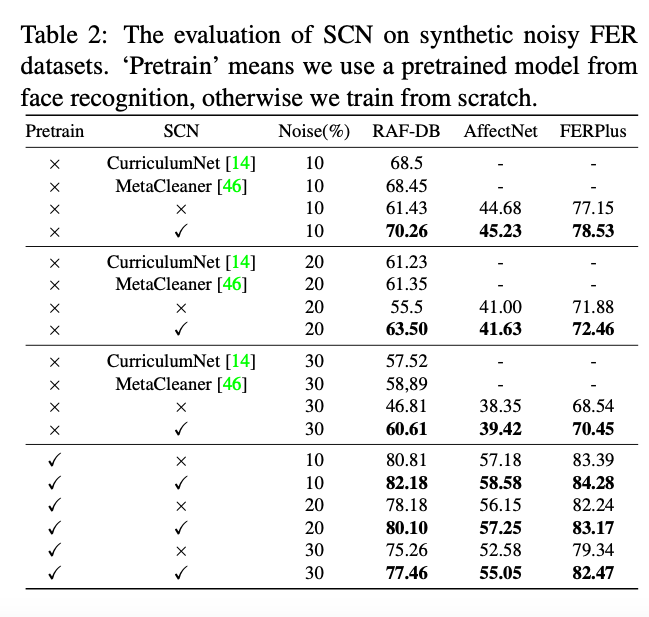
- SCN在添加了随机噪声的后的图片上的结果
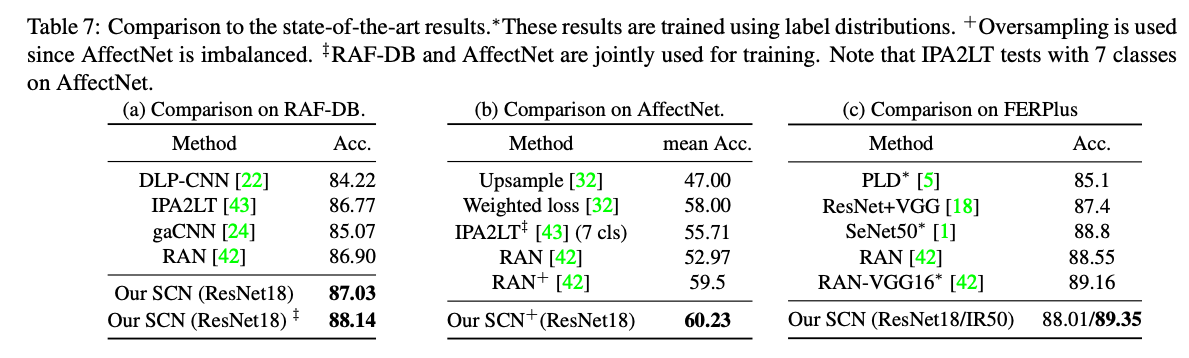
- SCN在原始数据集上的实验结果

- 表情识别论文阅读——Island Loss for Learning Discriminative Features in Facial Expression Recognition
- [论文][表情识别]Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition
- 论文笔记 Deep Facial Expression Recognition: A Survey深度面部表情识别调查
- Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks 视频人脸表情识别论文学习笔记
- 表情识别——Covariance Pooling for Facial Expression Recognition
- 表情识别LDTP算法(Local Directional Ternary Pattern for Facial Expression Recognition TIP 2017)
- 表情识别综述2018-Deep Facial Expression Recognition: A Survey
- [论文解读]VGGNet:Very Deep Convolution Networks for Large-Scale Image Recognition
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 论文学习
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION论文翻译
- 【Paper Note】Very Deep Convolutional Networks for Large-Scale Image Recognition——VGG(论文理解)
- 图像识别3-VGGNet-very deep convolutional Network for large-scale image recognition
- 论文笔记 | VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE -SCALE IMAGE RECOGNITION
- Very Deep Convolutional Networks for Large-Scale Image Recognition—VGG论文翻译—中文版
- 2016 ECCV论文 《Peak-Piloted Deep Network for Facial Expression Recognition》
- 深度学习论文随记(二)---VGGNet模型解读-2014年(Very Deep Convolutional Networks for Large-Scale Image Recognition)
- 【Paper Note】Very Deep Convolutional Network For Large-Scale Image Recognition 论文翻译(VGG)
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION论文翻译
- 论文解读| Very Deep Convolutional Networks for Large-Scale Image Recognition
- 2015 ICCV论文《Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition》