2015 ICCV论文《Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition》
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7410698&tag=1
说明:本博客仅介绍了两点:
1)问题是如何提出的
2)提出的方法思想
关于数学细节、网络训练细节、实验细节请大家自己阅读论文
DTAN:Deep Temporal Appearance Network
DTGN:Deep Temporal Geometry Network
DTAGN:Deep Temporal Appearance-Geometry Network
论文创新点
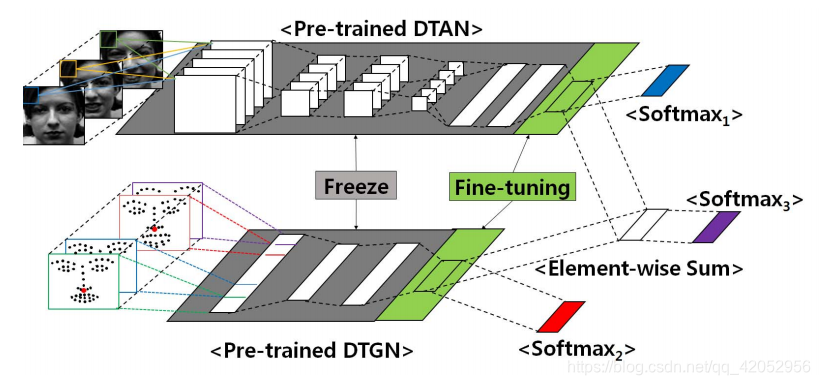
论文提出的表情识别网络(DTAGN)包括两种不同的子网络,第一个子网络(DTAN)从图像序列中提取时间人脸外观特征,而另一个子网络(DTGN)从时间面部关键点提取时间几何特征。为了提高FER的性能,采用一种新的整合方法将两种模型结合起来。
问题的提出
众所周知,深度学习算法能够自动从原始数据(如图像数据)中提取有用的特征。然而,当它们直接应用于FER数据集(比如CK+,MMI和Oulu-CASIA)时是有局限的,主要原因这些数据集太小,所以一个有很多参数的深度网络在训练时很容易过拟合(一般来说,数据收集代价很高的)。此外,如果训练数据是高维的,过拟合就会更加严重(?)。
在论文中,作者感兴趣的是使用有限数量的(通常是几百个)图像序列数据和深度网络来识别面部表情。为了克服数据量小的问题,他们构造了两个相互补充的小型深度网络。其中一个(DTAN)利用原始图像序列进行训练,更关注面部表情随时间的外观变化;另一个(DTGN)利用人脸关键点坐标进行训练,学习人脸关键点的随时间时间轨迹(或者说是面部部位的运动)。此外,我们还提出了一种新的网络集成方法,称为联合微调,它比简单的加权求和方法有更好的性能。
因此,论文的主要贡献可以概括如下:
1)为了从图像序列和路标点轨迹两种序列数据中提取有用的关于时间的特征,提出了两种深度网络模型;
2)我们观察到,这两个网络分别自动检测运动的面部部分和动作点;
3)我们提出了一种将这两种具有不同特征的网络融合在一起的联合微调方法,在识别率方面实现了性能的提高。
总体结构

联合微调方法(训练整合的网络)

- 表情识别论文阅读——Island Loss for Learning Discriminative Features in Facial Expression Recognition
- 【论文笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文笔记 Ensemble of Deep Convolutional Neural Networks for Learning to Detect Retinal Vessels in Fundus
- RCNN学习笔记(1):《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》论文笔记
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文笔记|Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- an empirical study of learning rates in deep neural networks for speech recognition 总结
- 【论文阅读笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 论文笔记 《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition--SPP-net论文笔记
- 【深度学习论文笔记:Recognition】:Deep Neural Networks for Object Detection
- 深度学习论文笔记-Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 深度学习论文笔记:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Techniques for preventing overfitting in training Deep Neural Networks
- 论文阅读--PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection
- 【论文阅读笔记】CVPR2015-Long-term Recurrent Convolutional Networks for Visual Recognition and Description
- RCNN(二)SPP-NET:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- [论文阅读]Relay Backpropagation for Effective Learning of Deep Convolutional Neural Networks
- 【CV论文阅读】Two stream convolutional Networks for action recognition in Vedios