[论文][人脸识别]High-Accuracy RGB-D Face Recognition via Segmentation-Aware Face Depth Estimation and Mask-Guided Attention Network
##背景: 研究背景:基于 RGB-D 的人脸识别基本上以 2D 人脸识别方法为主,将与 RGB 对齐的深度图作为一个通道送入 CNN 网络,RGB-D 一个优势是增加了人脸的空间形状信息。能够更好的应对大姿态变化和光照变化问题。针对 RGB-D 图像的人脸识别论文基本思想是在特征层融合或是在像素层融合深度信息。
Motivation:但3D数据昂贵,数量远少于2D数据,因此直接使用现有的3D数据易造成过拟合 ##目标: 通过2D人脸数据构建鲁棒的3D人脸识别模型。
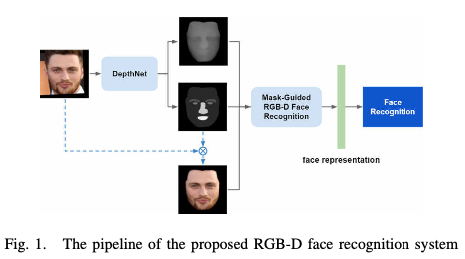
##网络结构 网络模型包含两个模块,分别为DepthNet和mask-guided RGB-D face recognition model 具体步骤如下:
- 对于一张2D的输入图像,用FAN进行人脸对齐
- 使用DepthNet产生2D图像对应的深度图和语义分割mask
- 根据语义分割的结果(语义分割可以区分背景和人脸)将2D图像中的背景像素值设为0,由此避免背景对人脸识别产生影响。
- 将第2步产生的mask,深度图以及第3步产生的2D人脸图像通过mask-guided RGB-D face recognition模型,得到识别结果。(对于真实的3D人脸图像,只需用真实的深度图替换此步骤中产生的深度图即可进行人脸识别)
###DepthNet
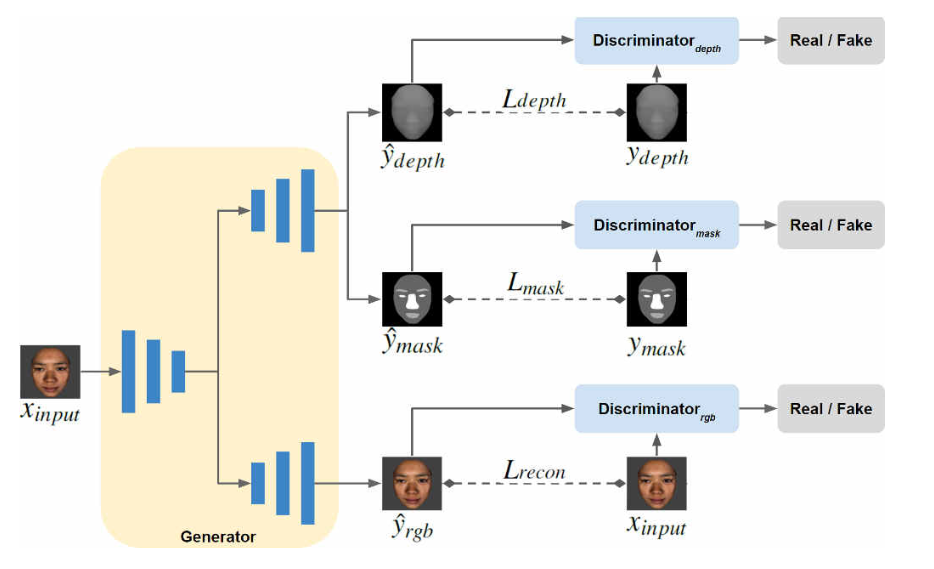
 此网络架构包含一个UNet的架构的生成器(generator)和三个鉴别器(discriminator),其中,生成器(generator)包含三个子网络,分别是face encoder(用于提前脸部特征向量),face decoder(用于生成图像),auxiliary decoder(用于 生成mask和深度估计图)。
对于face decoder,重建损失Lrecon使用L1损失来衡量,为:
此网络架构包含一个UNet的架构的生成器(generator)和三个鉴别器(discriminator),其中,生成器(generator)包含三个子网络,分别是face encoder(用于提前脸部特征向量),face decoder(用于生成图像),auxiliary decoder(用于 生成mask和深度估计图)。
对于face decoder,重建损失Lrecon使用L1损失来衡量,为:
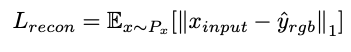 其中Xinput为输入的真实图像,Yrgb指生成图像。
其中Xinput为输入的真实图像,Yrgb指生成图像。
对于auxiliary decodecoder, Ldepth同样使用L1损失(MSE均方误差损失),semantic segmentation mask使用交叉熵损失
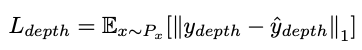
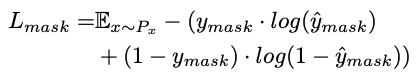 同时,我们训练三个鉴别器:Drgb,Dd,Dm 使用近似GAN的损失函数
同时,我们训练三个鉴别器:Drgb,Dd,Dm 使用近似GAN的损失函数
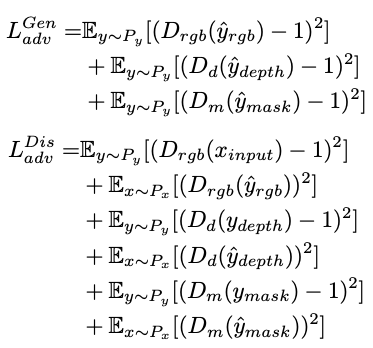
训练生成器:D(y)越接近1,说明y越接近真值,希望损失函数值越小,即D(y)越接近1
训练鉴别器:希望D(Xinput)接近1,D(y)越接近0
DepthNet总体损失为:
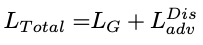
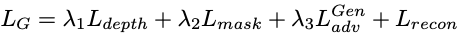 其中前两项的系数大小为100,第三项系数为1
其中前两项的系数大小为100,第三项系数为1
###Mask-Guided RGB-D Face Recognition :
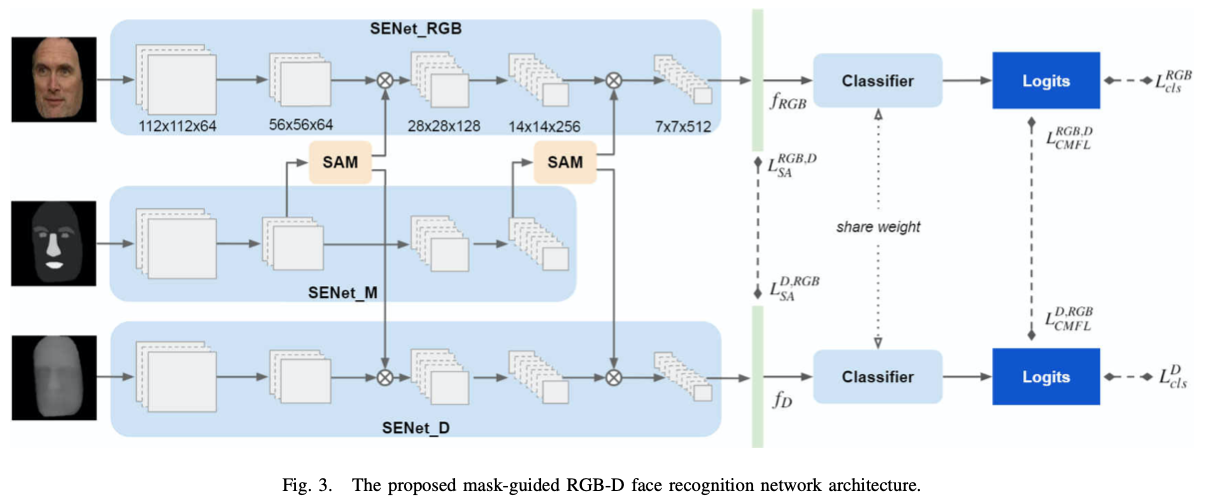 Mask-Guided RGB-D Face Recognition架构包含了三个分支,分别为:RGB recognition branch, a depth map recognition branch, 和 auxiliary segmentation mask branch。整个网络使用SENet作为backbone,并且加入了空间注意力模块SAM。
在训练阶段,RGB recognition branch提取面部表示特征,depth map recognition branch提取深度特征,auxiliary segmentation mask branch从segmentation mask中提取到了不同层级的特征图,再通过SAM辅助RGB and D branches的训练(两个SAM模块对于RGB和D分支共享参数),使得其关注最重要的部分。
对于单个分支,使用交叉熵损失衡量分类误差,同时使用cross-modal focal loss
Mask-Guided RGB-D Face Recognition架构包含了三个分支,分别为:RGB recognition branch, a depth map recognition branch, 和 auxiliary segmentation mask branch。整个网络使用SENet作为backbone,并且加入了空间注意力模块SAM。
在训练阶段,RGB recognition branch提取面部表示特征,depth map recognition branch提取深度特征,auxiliary segmentation mask branch从segmentation mask中提取到了不同层级的特征图,再通过SAM辅助RGB and D branches的训练(两个SAM模块对于RGB和D分支共享参数),使得其关注最重要的部分。
对于单个分支,使用交叉熵损失衡量分类误差,同时使用cross-modal focal loss
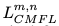 来学习模型的健壮表示:
来学习模型的健壮表示:
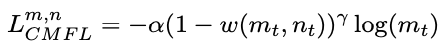
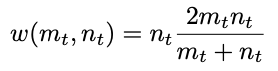
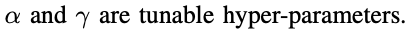 m_t 和 n_t 分别表示branch m和branch n的分类概率,当branch n 分类的置信度提高时,损失函数值会减小
m_t 和 n_t 分别表示branch m和branch n的分类概率,当branch n 分类的置信度提高时,损失函数值会减小
同时,我们使用语义对齐Lsa来共享两个特征向量,使得两个模型的输出结果尽可能相似,p用来确保信息只会从更准确的一方流向较不准确的地方(当m分支的分类交叉熵损失比n分支大时,该损失函数值也大,此时,该损失通过余弦相似度希望m模型与n模型尽可能相似,即信息流向更准确的一方,反之,若m分支分类交叉熵损失比n分支小时,该损失函数值为0,即m此时不受弱模型n的影响):
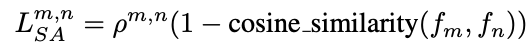
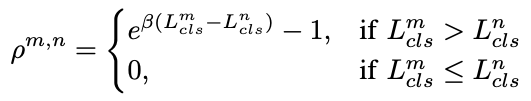
###总损失
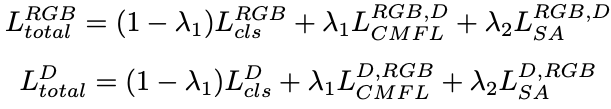 ##实验
使用BU-3DFE 3D database来训练DepthNet model,之后,再通过训练好的DepthNet model来增强VGGFace2 2D数据集(用预测所得深度作为真实深度,训练mask-guided RGB-D face recognition model)
##实验
使用BU-3DFE 3D database来训练DepthNet model,之后,再通过训练好的DepthNet model来增强VGGFace2 2D数据集(用预测所得深度作为真实深度,训练mask-guided RGB-D face recognition model)
训练数据准备:使用BU- 3DFE 3D face database作为训练数据,使用旋转作为图像增强方式,同时修改BiSeNet来产生语义分割mask(作为伪标签帮助后续训练)。
3D训练数据集:BU-3DFE 3D database,Texas FR3D database,Bosphorus database,FRGCv2 database,BUAA Lock3DFace database
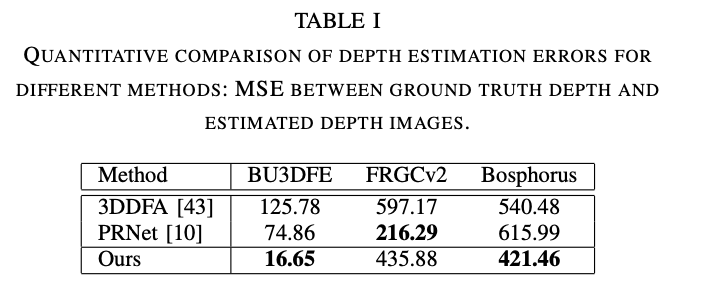 Table1:使用MSE衡量DepthNet的深度估计效果及对比
Table1:使用MSE衡量DepthNet的深度估计效果及对比
可视化结果:
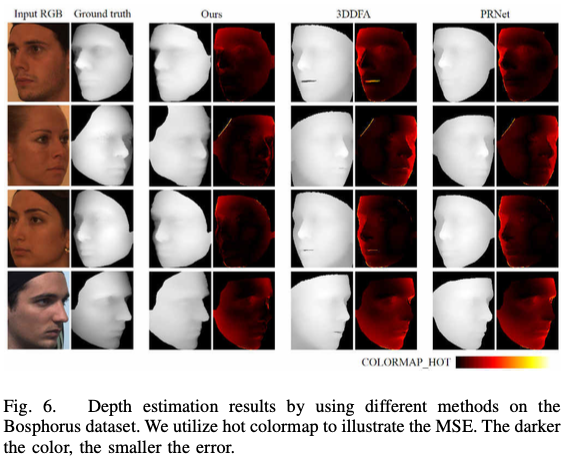
实验写作思路: 实验结果次优,则选择用可视化结果+理论分析说明模型的特点
For FRGCv2 dataset, although the estima- tion results by our model are not the best among the three methods, our DepthNet model can generate a more accurate depth image around the face contour than the other two methods, as shown in Fig. 5.For FRGCv2 dataset, although the estima- tion results by our model are not the best among the three methods, our DepthNet model can generate a more accurate depth image around the face contour than the other two methods, as shown in Fig. 5. This is because our model in- cludes semantic segmentation together with depth estimation.

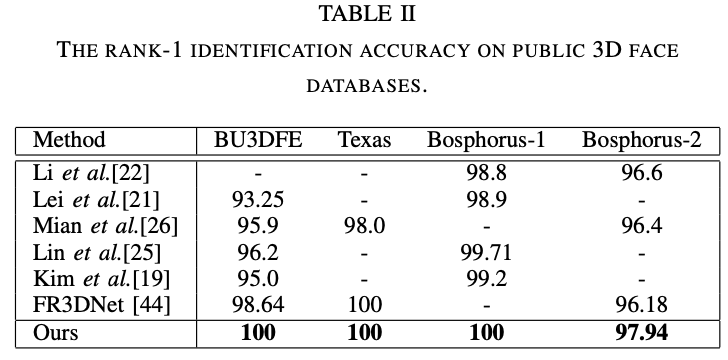
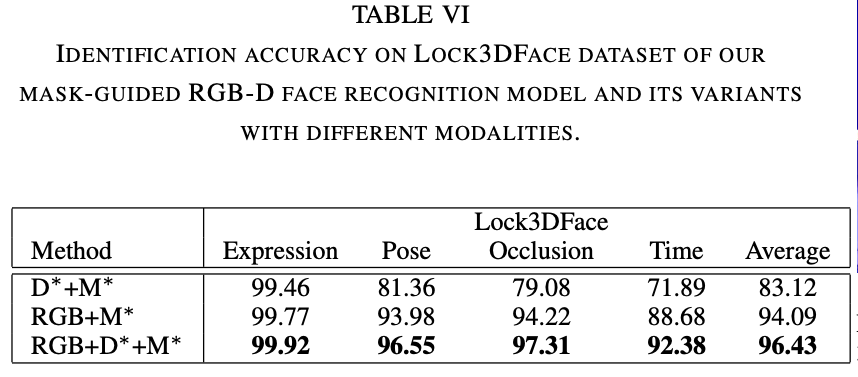
Table 3 说明此模型可以适用于不同类型的图片,包括:RGB图,深度图,RGB-D三种类型的图片,本方法会用Mask辅助人脸识别
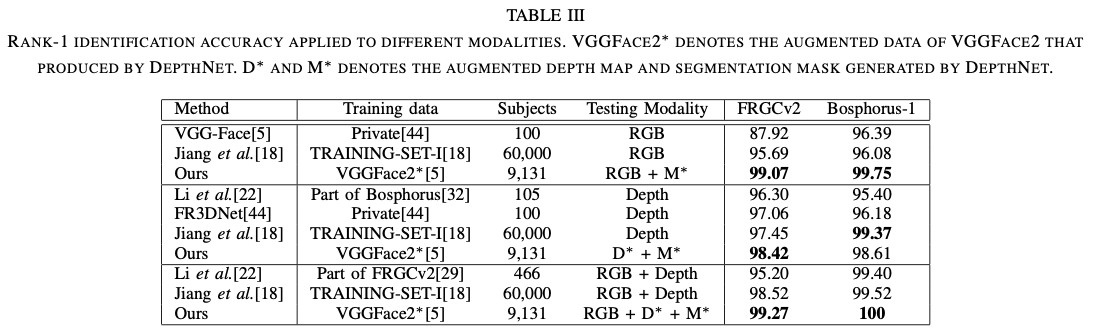
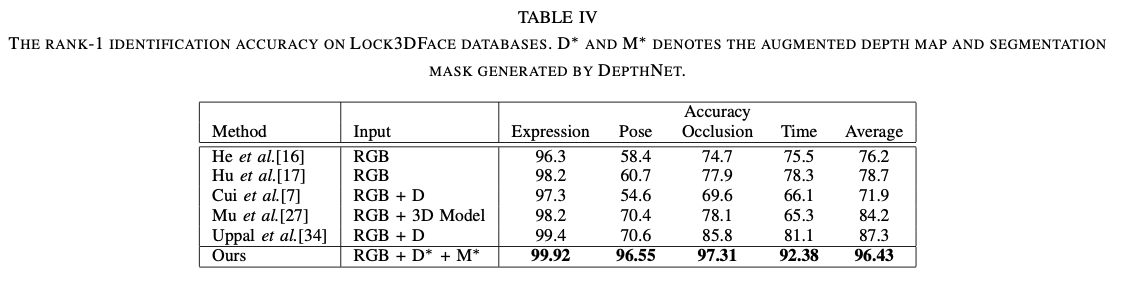
Table4: 可以看出我们的模型对于大姿态和遮挡的图片效果较好
消融实验:Segmentation Mask的作用
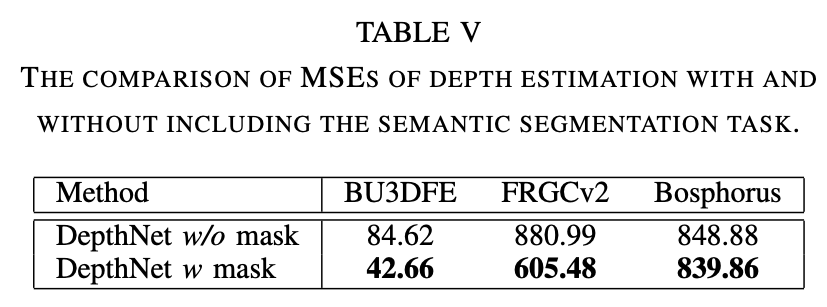
Mask在辅助DepthNet估计深度方面的作用(使用MSE来衡量深度估计的准确程度),
可视化结果:(猜测是在Mask的帮助下)我们的模型将注意力集中在informative 的部分,如眼睛,眉毛,鼻子等关键部位

消融实验:DepthNet的作用

- Segmentation笔记4-Boundary-Aware Network for Fast and High-Accuracy Portrait Segmentation
- 论文理解之增加换脸效果 FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping
- 人脸识别方向论文笔记(2)-- Latent Factor Guided Convolutonal Neural Networks for Age-Invariant Face Recognition
- 人脸识别方向论文笔记(3)-- Sparsifying Neural Network Connections for Face Recognition
- 论文阅读 Multi-Scale Structure-Aware Network for Human Pose Estimation
- 人脸和手势识别数据集 FGnet - IST-2000-26434 Face and Gesture Recognition Working group
- 人脸识别方向论文笔记(1)-- A Light CNN for Deep Face Representation With Noisy Labels
- 解读:WIDER Face and Pedestrian Challenge人脸检测部分论文+代码集合
- 人脸检测--FaceBoxes: A CPU Real-time Face Detector with High Accuracy
- 【论文笔记】FaceNet--Google的人脸识别
- 人脸识别“Neural Aggregation Network for Video Face Recognition”
- [论文][表情识别]Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition
- 论文笔记:Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answeri
- 人脸识别 - Pose-Aware Face Recognition in the Wild
- Face2Face: Real-time Face Capture and Reenactment of RGB Videos 论文翻译
- Mask-guided Contrastive Attention Model for Person Re-Identification 论文学习
- 人脸验证与人脸识别(Face verification and Face identification / recognition)
- SphereFace: Deep Hypersphere Embedding for Face Recognition(人脸识别论文笔记)
- 论文翻译:StereoNet: Guided Hierarchical Refinement for Real-Time Edge-Aware Depth Prediction
- 二值人脸对齐--Binarized Convolutional Landmark Localizers for Human Pose Estimation and Face Alignment