表情识别综述2018-Deep Facial Expression Recognition: A Survey
表情识别综述2018-Deep Facial Expression Recognition: A Survey(一)
该论文从4各方面(应用领域、表情数据库、识别流程和表情识别的算法)讲述了基于深度学习的表情识别在近几年的发展情况。
该论文根据表情数据库中图像的类型,把基于深度学习的表情识别算法分成了基于静态和基于动态序列的表情识别算法。本次我先跟大家介绍基于静态图像的表情识别算法。
1.应用领域
智能商场、智能交通、商品推荐系统、公共安全领域、人机交互、医疗领域和刑事犯罪领域。
2.表情数据库
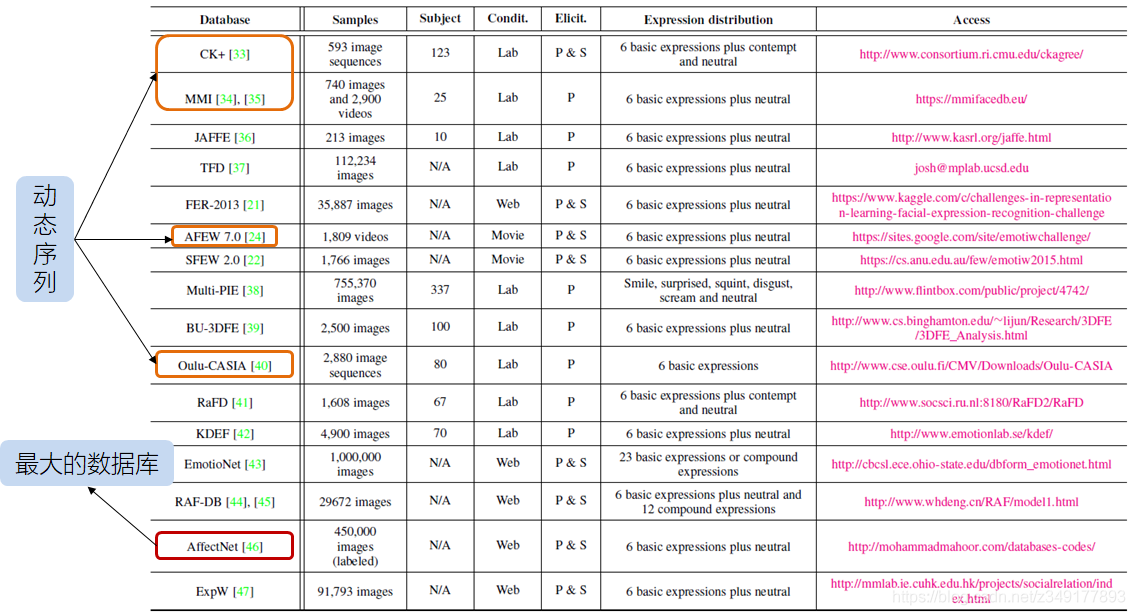
3.识别流程

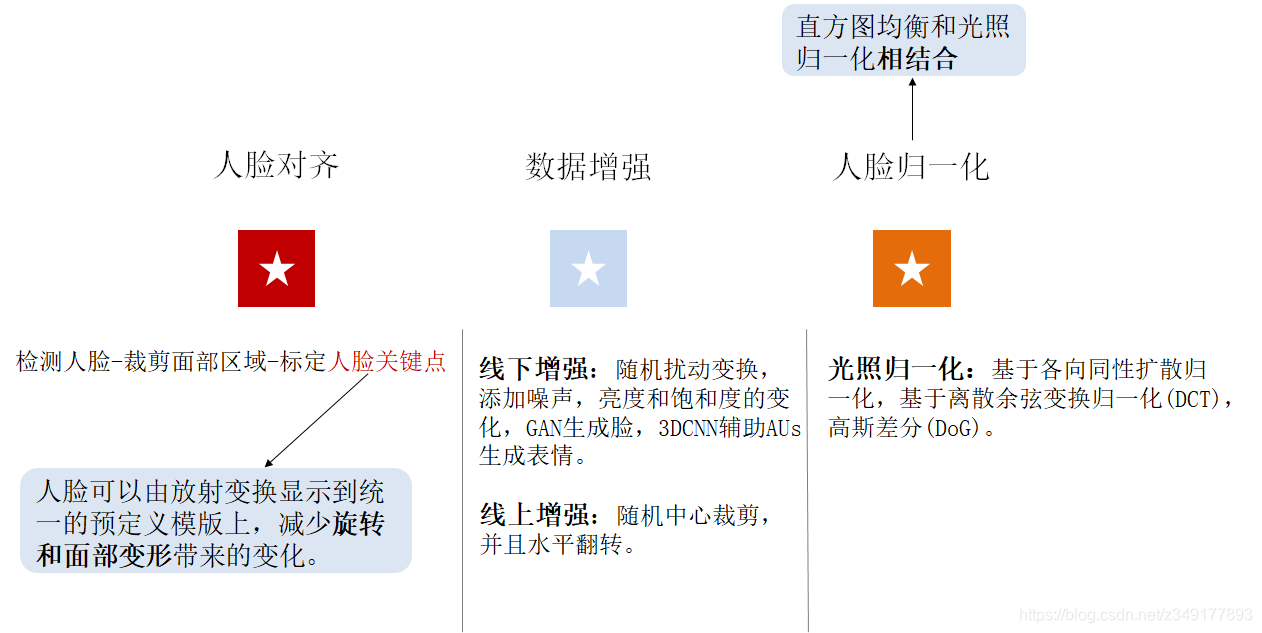
其中关于预处理的主要部分如下图所示:
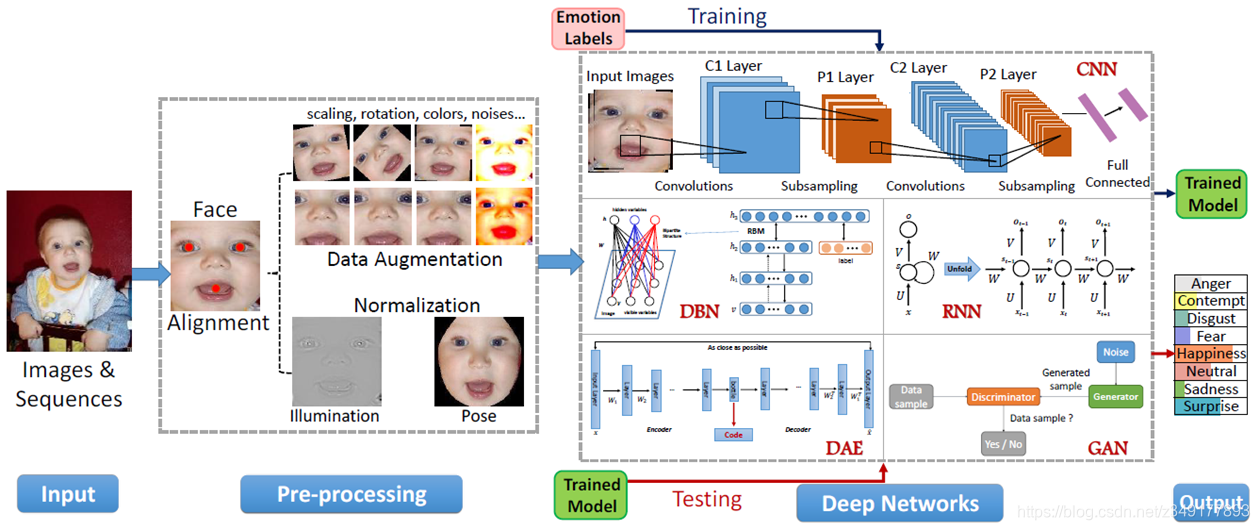
整个表情识别的框架如下图所示:
4.基于静态图像的FER
1)预训练和微调
基于存在的问题: 训练数据不足,易过拟合。
解决方法: 许多研究使用额外的任务导向的数据从零开始预训练自定义的网络,或者在已经预训练好的网络模型(AlexNet , VGG, VGG-face 和 GoogleNet)上进行微调。额外的任务导向的数据就是说大型的人脸识别(FR)数据库或其他一些较大的表情识别(FER)数据库。
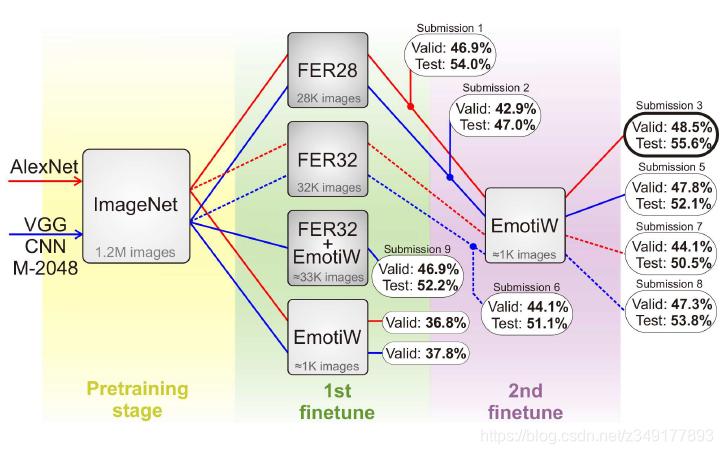
举例算法: 2015年提出的一个算法:第一阶段在预训练模型上使用 FER2013 进行微调,第二阶段利用目标数据库的训练数据进行微调,使模型更切合目标数据库。如下图所示:
2)多样化的网络输入
基于存在的问题: 网络输入的是整张原始图片,这样会失去一些有效的特征(均匀或规则的纹理)信息。
解决方法: 用非深度学习的方法来提取特征,然后再输入到网络模型中。
举例算法: 2015年提出的一个算法如下图所示:

3)辅助块或层的增加
算法1:
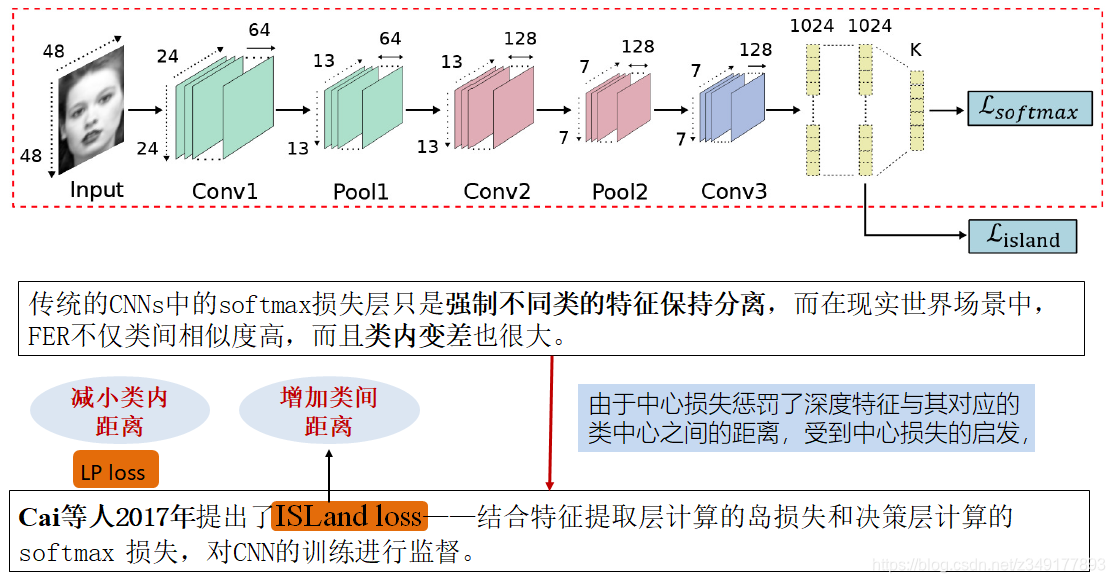
算法2:
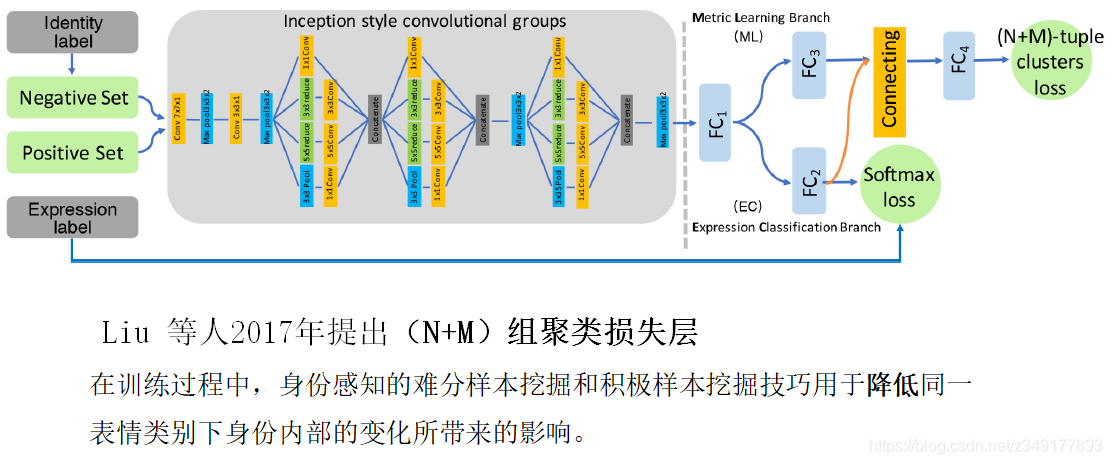
算法3:
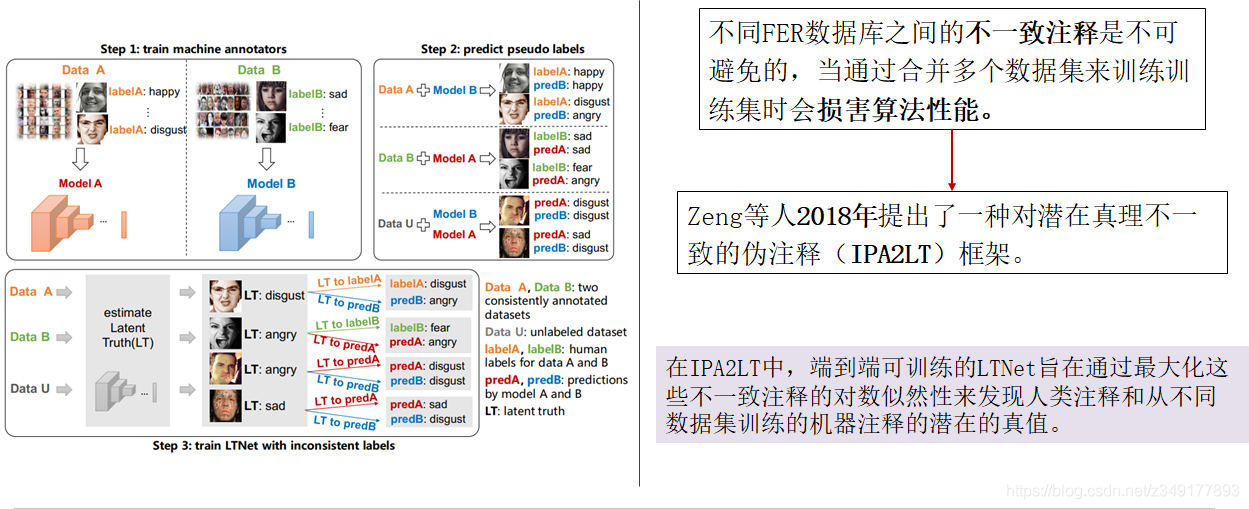
4)网络集成-特征层
将不同网络学习得到的特征连接起来,组成一个新的特征矢量,来表示图像。
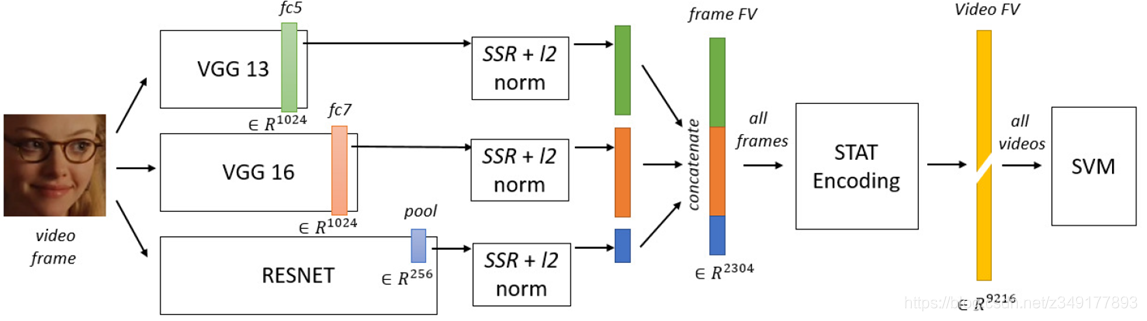
Bargal 等人2016年提出将三种不同特征(VGG13 fc5 层输出,VGG16 fc7 层输出和 Resnet 池化层输出)在归一化后连接在一起,生成一个单特征矢量(FV),然后用其描述输入帧。如下图所示:
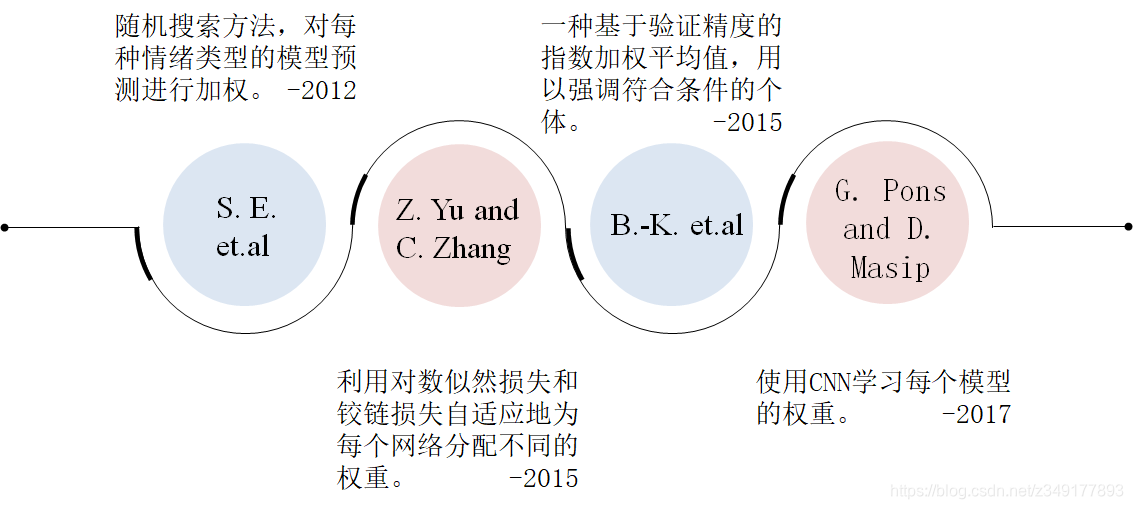
4)网络集成-决策层
有三种方法:简单平均(使用来自每个具有相同权重的个体的后验类概率来确定平均得分最高的类)、加权平均(使用每个权重不同的个体的后验类概率确定加权平均得分最高的类别)和多数投票(使用每个个体产生的预测标签确定投票最多的类)。
主要算法介绍如下图所示:
5)多任务网络
基于存在的问题: 现有的FER网络:单个任务,学习对表情敏感的特征,不考虑其他潜在因素(光照或姿态等)之间的相互作用。
解决方法: 引入了多任务学习,将知识从其他相关任务中迁移出来,消除有害因素。
举例算法: 2017年提出的一个算法如下图所示:
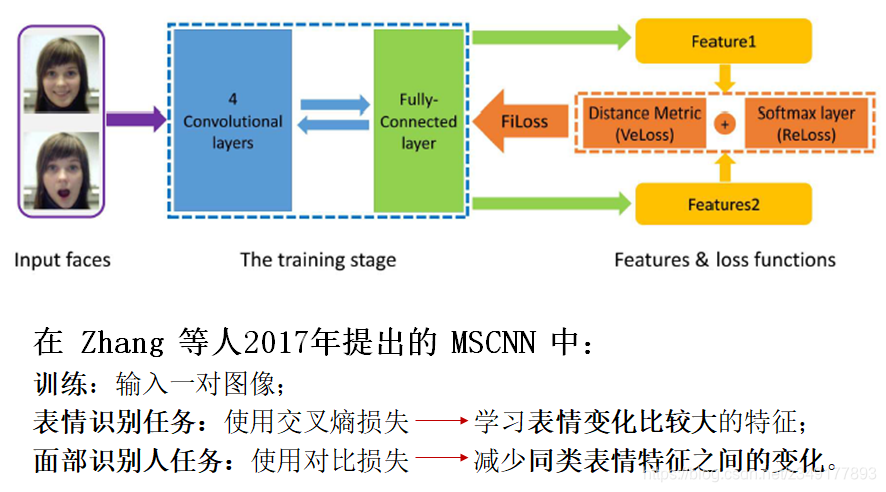
6)级联网络
在级联网络中,处理不同任务的各种模块按顺序组合,形成更深的网络,其中前一模块的输出作为后一模块的输入。相关研究提出用不同结构的新组合来学习层级特征,通过这些特征可以逐层滤除与表情无关的变化因素。
7)生成对抗网络
基于解决的问题:头部姿态,身份偏差,数据单一。
5.小结
表情识别存在的问题:
1)缺乏丰富多样的数据,易过拟合;
2)存在很多与表情无关的因素。

- 论文笔记 Deep Facial Expression Recognition: A Survey深度面部表情识别调查
- Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks 视频人脸表情识别论文学习笔记
- 表情识别——Covariance Pooling for Facial Expression Recognition
- 表情识别论文阅读——Island Loss for Learning Discriminative Features in Facial Expression Recognition
- Face Expression Recognition with a 2-Channel Convolutional Neural Network(基于双通道卷积神经网络的表情识别部分翻译)
- Paper-[acmi 2015]Image based Static Facial Expression Recognition with Multiple Deep Network Learning
- Facial Expression Recognition via a Boosted Deep Belief Network(泛读)
- 人脸表情识别综述
- (1) Facial expression recognition based on Local Binary Patterns: A comprehensive study
- 人脸表情识别综述
- Facial Expression Recognition Using KCCA
- 细粒度图像识别文章 Picking Deep Filter Responses for Fine-grained Image Recognition 阅读笔记
- 车牌检测识别--Towards End-to-End Car License Plates Detection and Recognition with Deep Neural Networks
- 人脸识别 - A Discriminative Feature Learning Approach for Deep Face Recognition
- 视频动作识别--Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
- 论文学习-深度学习目标检测2014至201901综述-Deep Learning for Generic Object Detection A Survey
- 车牌识别“Towards End-to-End Car License Plates Detection and Recognition with Deep Neural Networks”
- 图像识别3-VGGNet-very deep convolutional Network for large-scale image recognition
- 人脸识别(一)A Discriminative Feature Learning Approach for Deep Face Recognition
- VGG-大规模图像识别的深度卷积网络 Very Deep Convolutional Networks for Large-Scale Image Recognition