最佳案例 | 游戏知几 AI 助手的云原生容器化之路
作者
张路,运营开发专家工程师,现负责游戏知几 AI 助手后台架构设计和优化工作。
游戏知几
随着业务不断的拓展,游戏知几AI智能问答机器人业务已经覆盖了自研游戏、二方、海外的多款游戏。游戏知几研发团队主动拥抱云原生,推动后台业务全量上云,服务累计核心1w+。
通过云上的容器化部署、自动扩缩容、健康检查、可观测性等手段,提高了知几项目的持续交付能力和稳定性,形成了一套适合游戏知几自身的上云实践方案。本文将会介绍游戏知几项目中遇到的痛点以及探索出的一套可靠的上云实践方案。
知几项目背景
游戏知几是一款游戏智能AI产品和运营解决方案,它基于自然语言处理、知识图谱、深度学习等前沿技术,为游戏玩家提供一站式服务,包括游戏内外实时智能问答、游戏语音陪伴、自助流水查询、游戏内外数据互通、主动关怀防流失、产品合规保护等多种能力,目前已经接入包括王者荣耀、和平精英、PUBG mobile、天刀手游等六星游戏在内的80+款游戏,为海内外数以亿计的游戏用户提供服务,获得众多游戏项目和广大用户的持续好评。
同时游戏知几还提供了简便易用、性能良好的客户端 SDK 和功能完备的运营平台系统,支持模块化接入,显著降低了用户运营中的人力成本,提升了玩家的交互体验。

随着知几业务的不断发展,知几的部署架构也在不断的演进,逐步从最初的 IDC 部署架构迁移到当前的云原生部署架构,实现了业务服务的全面上云。
上云前的知几
docker 部署方案
知几在最初采用 docker 部署的方案来部署服务,服务的 CI/CD 通过夸克平台实现,平台将编译打包好的服务推送到 docker 机进行部署。为了实现机器的水平扩容,运维同学会将 docker 环境整体打包成基准镜像,包括 IDC 的机器环境所依赖的环境,比如 CL5 agent,gse agent 等。当需要扩容时,将基准环境发布到扩容机器上进行扩容操作。
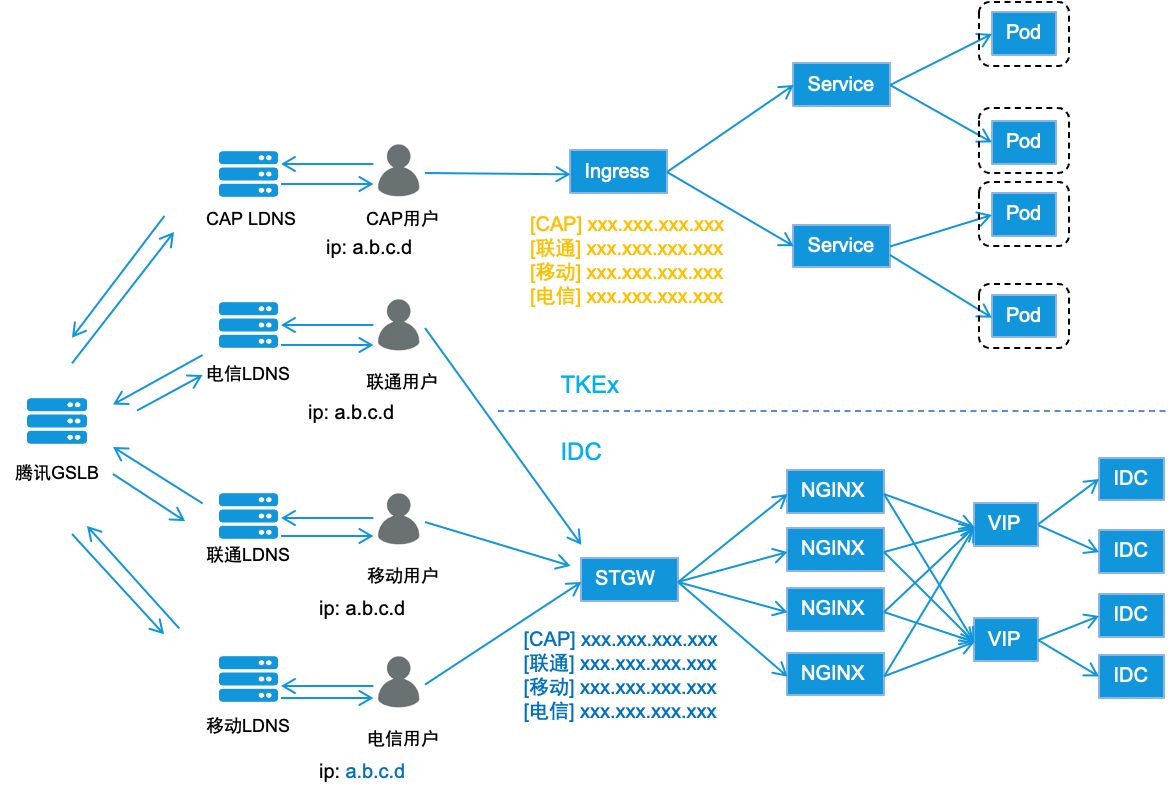
知几整体的部署架构如下图所示:
- 外部请求统一通过 stgw 接入,rs 到后台服务的 vip 上,通常会区分移动、联通、电信和小流量运营商;
- vip 下挂载的机器IP、端口通过tgw平台配置,请求通过一定的负载均衡策略发送到IDC机器的后台服务上;
- 服务的 CI/CD 通过夸克平台操作,完成服务的编译、打包、发布等操作,也支持操作回滚,进程监控等;
- 监控告警、日志系统接入的是mo监控平台和骏鹰。

服务遇到的问题
知几项目会对接 IEG 下的众多游戏,伴随着游戏接入的增多,流量也变得越来越大,知几项目的流量状况有以下特点:
平时流量平稳,节假日流量随游戏流量增大,通常达到3倍以上;
主动关怀类的消息推送,运营活动会通过知几直接触达给玩家,带来可观的突发流量,极端情况10倍以上;
因此,知几对服务的稳定性、可观测性以及服务治理的能力有很高的要求,需保证项目在流量突发的情况下能够正常运行,故障时能及时发现。
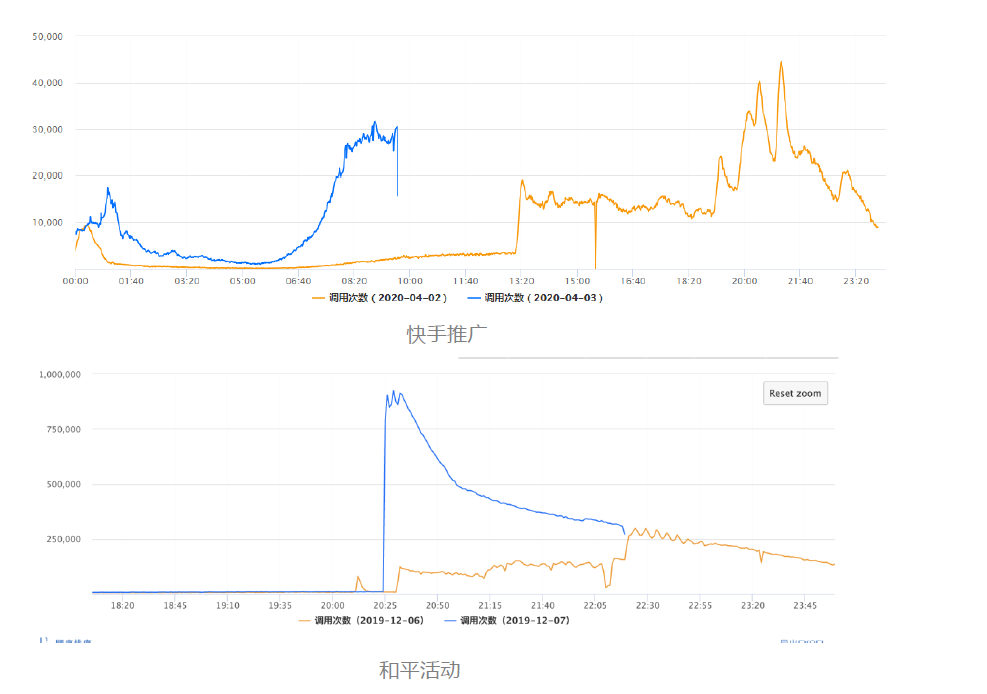
在 docker 部署的架构下,很难做到快速的自动扩缩容,主要问题有以下几个方面:
扩容前的机器申请、环境准备很耗时,突发流量的情况下这个准备时间难以接受,提前准备好机器平时又会造成资源的浪费;
运维制作的基准镜像通常不是最新的版本,需要发布最新版本才能扩容;
依赖的权限(mysql 等)需要申请;
平台操作繁琐,容易出错;
需要人工完成运营活动后机器的缩容操作。
这些问题都会造成服务在扩容时的不及时,从而带来服务稳定性的隐患,同时也带来了业务同学的运维负担。除此之外,每年一次的机器裁撤也很痛苦,涉及机器确认、服务迁移、环境梳理等方方面面的操作。
因此,我们希望通过上云迁移,利用云原生的 HPA 能力来解决服务稳定性、裁撤等问题。
上云迁移
知几云原生方案
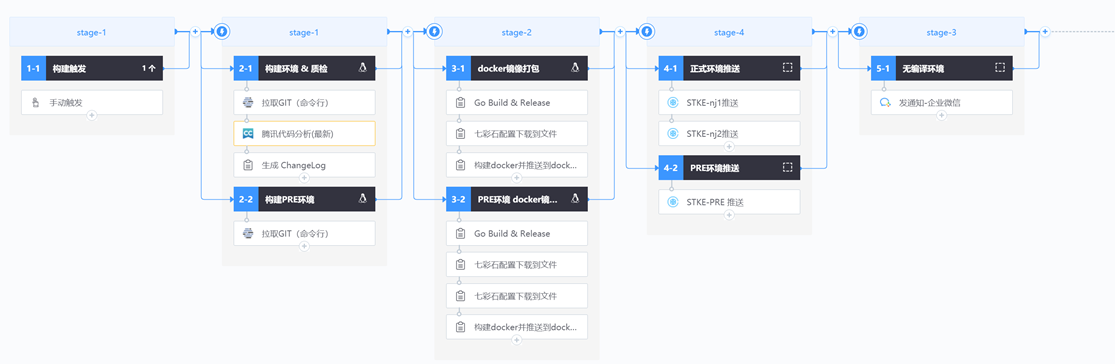
针对以上问题,当前知几实践了一套基于云原生的多机房部署方案。具体方案如下:
引入 tapisix 统一网关,借助限流等网关插件管理南北流量,stgw 接入 tapisix 网关的 ingress;
服务分南京一区和南京二区进行部署,各区服务通过 ingress 暴露外网流量,tapisix网关混连接入一区、二区服务的 ingress;
新增上海灾备集群,极端情况下可快速接入;
CI/CD 方面通过蓝盾流水线实现,打包服务镜像推送到镜像仓库,在STKE上进行部署。

基于上述的部署方案,利用云原生的自动扩缩容能力可以方便的解决上述问题:
STKE 提供的定时 HPA 和动态扩缩容能力,可以很好的解决节假日、运营活动的流量突增带来的服务稳定性问题,且流量平稳后的自动缩容可以有效的节约资源;
STKE 提供自动鉴权流程,可以解决依赖权限申请的问题,通常鉴权流程的耗时在分钟级;
引入 tapsix 统一网关,接入分区流量,可以对流量进行快速切换,当一个区的服务有问题时,可以通过 tapsix 的路由快速切换到另外一个区;
迁移方案
知几服务的上云迁移设计外网和内网的众多服务,外网服务迁移的过程可通过运营商逐步对流量进行灰度:
首先在 stke 集群新部署服务进行测试,提供移动、联通、电信 和CAP 四类公网 CLB;
先灰度 CAP 小运营商流量,服务稳定后再通过 gslb 逐步灰度其他运营商;
回滚则通过 gslb 快速切换回 IDC 服务的VIP;
内网服务的迁移则通过 STKE 支持的北极星、CL5 serivce 自动将 pod ip 注入到老服务的负载均衡当中,首先通过一个 pod 进行灰度,再逐步增加 pod 完成放量,最后摘除 IDC 的机器即可。通过这种方式,我们在三个月内完成了所有外网服务和后台服务的全量上云,并保证了迁移的平稳进行。
上云实践
标准化部署实践
业务上云基础的点就是考虑怎么做标准化的容器部署和弹性服务。知几服务主要有三类,业务服务通常是 Go 服务,算法服务为 C++ 服务,需要考虑模型加载的问题,平台服务主要为 PHP 服务。在容器的标准化上,我们采用的是单容器模式,这样做的好处是每个 container 间互不影响,进程是作为容器的一号进程存在,一旦有问题 k8s 会自动把服务拉起,另外也便于资源的复用。富容器的模式是把所有的进程都放在一个容器内,这样看似方便,能实现业务的无缝平滑的快速上云,但无论从未来的维护效率、安全还是健康检查、服务弹性上看都有问题,是中间态,违反了容器单一功能原则,也不符合云原生的理念。
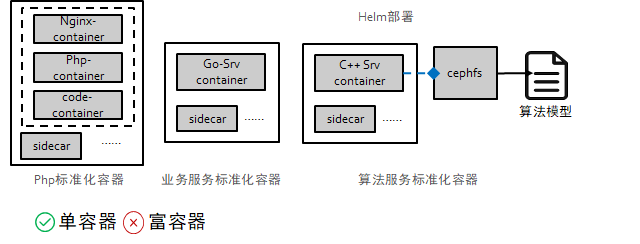
PHP 的服务将 nginx,pfp-fpm,业务代码都打成了独立的 container,代码通过文件共享的形式共享给 php-fpm 的 container 实现。
Go 服务较简单,采用常规的应用 container + sidecar 的标准化容器。
算法服务主要是模型,模型文件挂载到 cephfs 上,共享给 C++ 服务的容器使用。
知几在服务部署的过程中,积累了一些实践经验,通过云原生的对资源利用的优势,提升资源的利用率,降低运营成本。针对不同场景最小实例的配置如下:
测试环境、预发布环境流量较少,统一0.1核0.25G,1实例。
生产环境,业务后台服务采用1核2G,2实例。
生产环境,算法后台服务采用8核16G(个别如在线推理服务会采用32核以上的机器)。
通过降低单 pod 的 CPU,MEM request,满足日常运营需求,流量高峰期则通过 stke 的 HPA 能力来满足业务的需要,使日常 CPU 利用率能达到40%。由于 HPA 会导致业务容器的扩缩容,如果流量在服务未完成启动时接入或者流量还在访问时接销毁 pod,会导致流量的损失,因此需要开启就绪检测和 prestop 配置。
这里需要注意的是,就绪检查的启动延时设置不易过短,这样系统会认为 pod 启动失败而不断重启,导致服务无法正常启动。


此外,stke提供的其他特性可以很好的满足知几的业务需求:
提供鉴权流程,可以在 pod 拉起时,动态的申请 mysql 等依赖的权限,规避繁琐的权限申请流程。
configmap 可解决配置服务配置更新的问题。
可对内核进行调优,业务可根据服务、流量的特点针对性的对内核参数进行优化,如 net.core.somaxconn, net.ipv4.tcp_tw_reuse 等等。
当前知几在线上部署了超过 1w 核,支撑知几 Sdk,第五人等多个应用服务,整体的利用率在40%左右。
HPA
STKE 提供的 HPA 能力能够很好的满足知几对扩缩容的需求,知几同时使用了定时 HPA 和动态 HAP 满足不同的场景:
- 针对突发流量, 知几采用 CPU request 和内存 request 作为触发扩容的条件
- 节假日和周五、六晚未成年人游戏上线,知几采用周定时 HPA 提前扩容
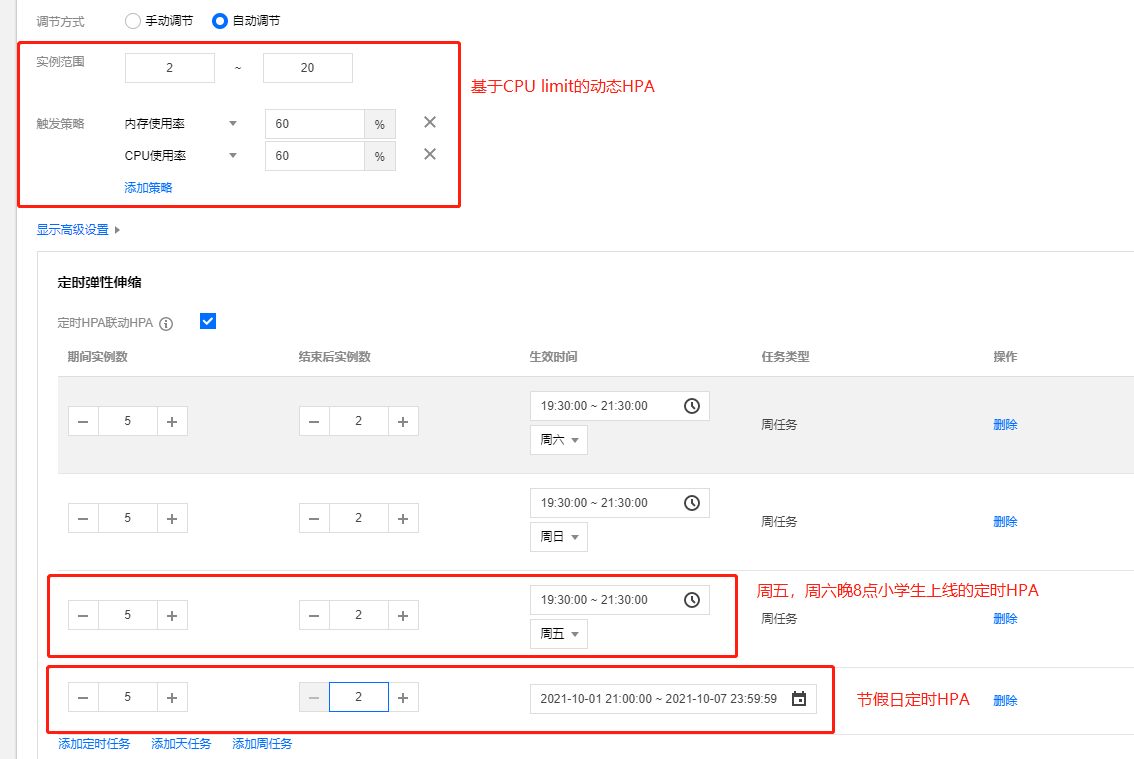
这样很大程度上减少了开发、运维同学面对运营活动和突发流量时的心智负担,提高了服务稳定性。特别是定时 HPA,可以很方便的满足知几在未成年人保护方面对扩缩容的要求,系统可以在特定时间段完成系统容量的扩容和缩容,在保证系统平稳应对流量的同时也不会造成对资源的浪费。迁移上云后,知几通过这种方式保证了周末时段和线上多场运营活动的平稳进行。
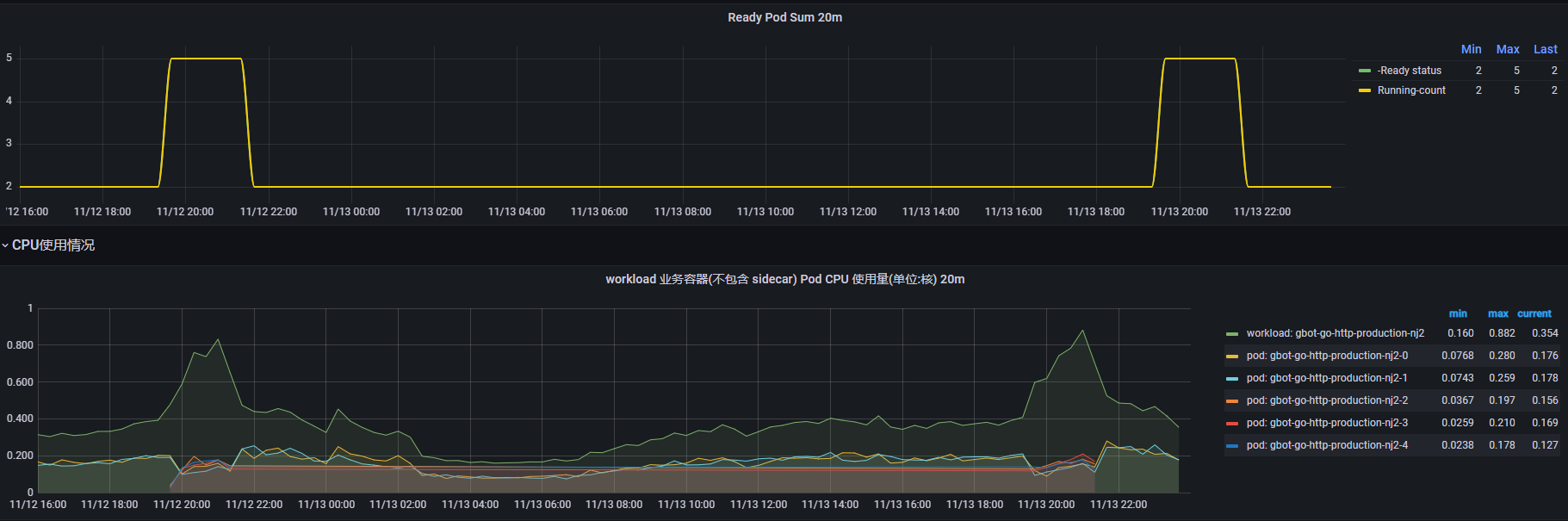
可观测性
系统的可观测性能够让开发同学根据系统输出快速监控、定位问题。可观测性可以从 Metrics、Log、Trace 三个方面来看。
- Metrics,知几服务大部分对接的是 Monitor 系统,通过自定义 metircs 上报实现模调信息、服务状态、业务等指标的监控,知几封装了 Monitor 的标准库实现指标模板的标准化和上报。Monitor 上报需要通过 http 请求获取上报的 ip 再将数据通过 tcp 形式发送到 Monitor 侧,这种形式的上报对业务并不友好,Monitor 当前也已不再接入新的业务,目前知几正逐步将 Metrics 迁移到智研监控系统,trpc 提供插件接入智研监控能力。
- Log,早期知几上云时采用的 filebeat 采集日志,现在 stke 提供了统一的日志数据解决方案 CLS ,可以方便的进行日志采集、存储、检索,运维成本较低,体验较好。
- Trace,知几接入天机阁来对请求做 traceing,记录系统的请求链路等上下文信息。通过 traceId 对请求进行标记染色很大程度上提升了问题定位的效率。在此基础上,知几同时也在尝试 dapr 这类新的分布式应用开发组件,dapr 提供的可观测性的无感知接入,相比天机阁等侵入式的接入方式,成本更低。

总结
知几整个上云迁移的过程随着公司云原生体系的基础设施的完善在不断的完善和优化,公司在相关领域的共建使得业务在实施过程中有了更多的选择。希望知几的实践能给更多的业务团队带来价值。未来在云原生的深入实践方面,团队还会在云原生标准化方向上(mecha 理念)做出更多的尝试。
关于我们
更多关于云原生的案例和知识,可关注同名【腾讯云原生】公众号~
福利:
①公众号后台回复【手册】,可获得《腾讯云原生路线图手册》&《腾讯云原生最佳实践》~
②公众号后台回复【系列】,可获得《15个系列100+篇超实用云原生原创干货合集》,包含Kubernetes 降本增效、K8s 性能优化实践、最佳实践等系列。
③公众号后台回复【白皮书】,可获得《腾讯云容器安全白皮书》&《降本之源-云原生成本管理白皮书v1.0》
④公众号后台回复【光速入门】,可获得腾讯云专家5万字精华教程,光速入门Prometheus和Grafana。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!


- 成本降低40%、资源利用率提高20%的 AI 应用产品云原生容器化之路
- 【AI Top30+案例评选】AI聚变,寻找2018年度最佳人工智能应用案例
- 案例 | 腾讯广告 AMS 的容器化之路
- 最佳实战:用Cocos2d-x3.x和C++11编写2048游戏以及游戏AI(全民2048 Android版上线啦)
- java学习之路——类与对象案例之打字游戏
- 【尚观】Android游戏与应用开发最佳学习之路_转载来学习Android
- 资源利用率提高67%,腾讯实时风控平台云原生容器化之路
- AI玩伴上线,或将成为你游戏之路上的“神队友”?
- 十大云原生最佳用户案例实践,你最喜欢哪篇
- 【尚观】Android游戏与应用开发最佳学习之路_转载来学习Android
- 【C++游戏】2048的实现和简单AI
- 京东云的云原生理念及 Serverless 最佳实践
- OOA&D实践之路——真实案例解析OO理论与实践(二、第一项任务:特性列表)
- 通向云端之路 谈NVIDIA云游戏概念发展
- 服装ERP案例:美特斯.邦威的ERP之路
- 二胎上位之路:html5报表和原生报表的笑尿撕逼
- AI入门——阐述游戏AI设计的两个禁忌及解决方法(转)
- html5游戏开发的五个最佳实践
- 游戏AI之模糊逻辑(4)
- 使用OGEngine开发游戏案例展示