表情识别——Covariance Pooling for Facial Expression Recognition
表情识别——Covariance Pooling for Facial Expression Recognition
版权声明:本文为博主原创文章,未经博主允许不得转载https://blog.csdn.net/heruili/article/details/88322472
Covariance Pooling for Facial Expression Recognition
CVPRW.2018
摘要:将面部表情分类到不同的类别需要捕捉面部关键点的区域扭曲。我们相信像协方差这样的二阶统计数据能够更好地捕捉区域面部特征的这种扭曲。在这项工作中,我们探讨使用多重网络结构的协方差池来改善面部表情识别的好处。特别地,我们首先将这种流形网络与传统的卷积网络结合起来,以端到端深度学习的方式在单个图像特征映射中使用空间池。通过这样做,我们能够实现58.14%的识别精度验证 Static Facial Expressions in the Wild (SFEW 2.0)和87.0%的 Real-World Affective Faces (RAF)数据库1揪的这些结果是我们知道最好的结果。此外,我们利用协方差池来捕捉每帧特征的时间演化,用于基于视频的人脸表情识别。我们的报告结果通过将所设计的协方差池流形网络叠加在卷积网络层上,证明了时序上图像集特征池的优势
Introduction
面部表情在传达我们的思想状态中起着重要的作用。人类和计算机算法都能从对面部表情进行分类中获益。
自动面部表情识别的可能应用包括更好地转录视频、电影或广告推荐、远程医疗中的疼痛检测等。
传统的卷积神经网络(CNNs)使用卷积层、最大或平均池和全连通层,只捕获一阶统计量[25]。二阶统计量(如协方差)被认为是比一阶统计量(如平均或最大[20])更好的区域描述符。

如上图所示,面部表情识别更直接地与面部特征点的变形有关,而不是与特定特征点的存在与否有关。我们认为,二阶统计量比一阶统计量更适合捕捉这种扭曲。为了深入学习二阶信息,我们引入卷积层后的协方差池。为了进一步降维,我们从流形网络[11](manifold network)中借用概念,并与传统的CNNs一起进行端到端训练。需要指出的是,这并不是第一次将二阶池引入传统的CNNs。在[13]中,协方差池最初用于从CNNs的输出池化协方差矩阵。[25]提出了一种在CNNs环境下计算二阶统计量的方法。然而,这两项工作并没有使用降维层或非线性校正层进行二阶统计。在这篇论文中,我们提出了在人脸表情识别的背景下探索它们的强烈动机。
协方差池除了能够更好地捕获区域面部特征的畸变外,还可以用于捕获每帧特征的时间演化。协方差矩阵用于总结每帧特征之前[17]。在这项工作中,我们尝试使用流形网络来池化每帧的特性。
总之,本文的贡献是两方面的
1、视频和图像在人脸表情识别上下文中的二阶统计量的端到端池化
2、基于图像的人脸表情识别的研究进展取得了State-of-art result
Facial Expression Recognition from Images
近年来,基于图像的人脸表情识别方法大多采用各种标准结构,如VGG网络、Inception网络、残差网络、inception残差网络等[3][7][21]。其中很多作品在fer2013上进行了人脸识别的预培训
数据集或类似的数据集,或者使用完全连接层的输出作为特征来训练分类器,或者对整个网络进行微调。使用多个CNNs的集成和预测分数的融合也得到了广泛的应用,并取得了成功。例如,在Emotiw2015子挑战赛基于图像的面部表情识别中,优胜者和亚军[15][26]都采用了CNNs集合的方式获得了最好的报道分数。在那里,对fer2013数据集进行了预培训。最近,在[3]中,作者报告了验证精度为54.82%,这是针对单个网络的最新结果。采用VGG-VD-16实现了该方法的准确性。作者对VGGFaces和FER-2013进行了预训练。
上述网络均采用传统的神经网络层。可以认为这些体系结构只捕获一阶统计信息。另一方面,协方差池捕获二阶统计量。最早使用协方差池进行特征提取的工作之一就是将其作为区域描述符[6][20]。在[25]中,作者提出了各种基于VGG网络的协方差池结构。在[11]中,作者提出了一种用于黎曼流形学习的深度学习结构,该结构可用于协方差池。
Facial Expression Recognition and Covariance Pooling
面部表情定位于面部区域,而野外图像包含大量的无关信息。因此,首先进行人脸检测,然后根据人脸地标位置进行对齐。接下来,我们将标准化的面孔输入一个深度CNN。池的
从CNN的特征图空间上,我们提出使用covaraince池,然后利用流形网络[11]深入学习这些二阶统计量。我们提出的基于图像的人脸表情识别模型的流程如图2所示。

作为基于图像的面部表情识别的案例,在野外的视频包含了大量无关的信息。首先,所有的帧都是从视频中提取出来的。然后在每个帧上执行人脸检测和对齐。根据特征提取算法的不同,要么从归一化人脸中提取图像特征,要么将归一化人脸进行拼接,并对拼接后的帧进行三维卷积。直观地说,随着时间的方差可以捕捉到有用的面部运动模式,我们建议将帧与时间相结合。为了深入了解时空二阶信息,我们还采用了流型网络[11]对协方差矩阵的维数减少和非线性。图3给出了基于视频的面部表情识别模型的概述。
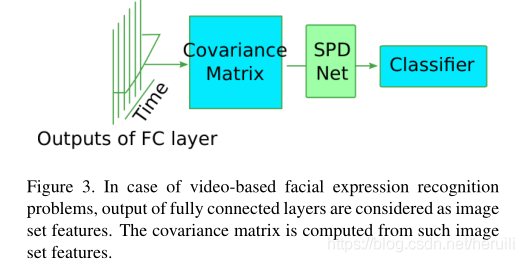
因此,这两种模型的核心技术是空间/时间协方差池和用于深入学习二阶特征的流形网络。下面我们将介绍两个关键技术
Covariance Pooling
如前所述,由全连接层、最大或平均池化层和卷积层组成的传统cnn只捕获一阶信息[25]。ReLU引入了非线性,但只在单个像素级引入。由特征计算的协方差矩阵被认为比一阶统计量[20]更能捕捉区域特征。、
在给定一组特征的情况下,协方差矩阵可以用来简洁地概括该集合中的二阶信息
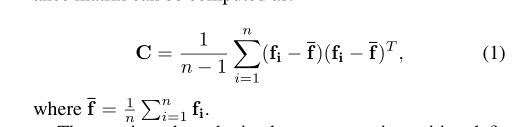
所得到的矩阵是对称正定的(SPD),仅当{f1, f2,…,f n}大于d,为了利用SPD流形网络[11]的几何结构保持层,需要协方差矩阵为SPD。然而,即使矩阵只是正半定的,也可以通过向协方差矩阵的对角线元素添加多个trace来正则化:

Covariance Matrix for Spatial Pooling:
为了将协方差池应用于基于图像的人脸表情识别问题,如图2所示,可以将最终卷积层的输出进行摊平,并用于计算协方差矩阵
令X∈R w×h×d为经过几个卷积层后得到的输出,其中w,h,d
分别表示输出中的宽度、高度和通道数。X可以被展平为元素X '∈R n×d,其中n = w×h。,f n∈R d为X '的列,我们可以像Eqn 1那样通过计算协方差来捕捉信道间的变化,并利用Eqn 2对计算矩阵进行正则化。
SPD Manifold Network (SPDNet) Layers
由此得到的协方差矩阵一般位于SPD矩阵的黎曼 Riemannian manifold 流形上。直接压扁和应用全连通层直接导致几何信息的丢失。标准方法采用对数运算对黎曼流形结构进行平化,使其能够应用欧氏空间[6][20]的标准损失函数。由此得到的协方差矩阵往往较大,需要在不损失几何结构的前提下降维。在[11]中,作者引入了特殊的层来减小SPD( symmetric positive definite,对称正定)矩阵的维数,使其展平,并应用标准损失函数。
在本节中,我们简要讨论了[11]中引入的学习黎曼流形的层
Baseline Model and Architectures for Image-based Problem
1、Comparison of Standard Architectures

在表1中,我们给出了各种标准网络体系结构的训练或调整精度的比较。对于基线模型,我们采用[16]中提出的网络体系结构。与基线模型相比,[16]中VGG网络和AlexNet在RAF数据库中报告的分数较少。所以网络在这里不再训练。值得指出的是,在那里,作者报告每类平均精度,但我们只报告总精度在这里。在这里,我们使用中心损失[22]在所有情况下训练网络,而不是局部保留损失[16],因为我们不处理复合情绪。在所有情况下,数据集都是使用标准技术,如随机裁剪、随机旋转和随机翻转来扩充的。对于SFEW 2.0,在所有情况下,在所有情况下,都使用从第二层到最后一层全连通层的输出作为图像特征,并分别训练支持向量机(svm)。请注意标签上的模型都是我们自己训练的。inception - resnetv1[19]既从零开始训练,也在MS-Celeb-1M数据集子集上预先训练的模型上进行了微调。从表中可以看出,对人脸识别数据集训练的inception- resnetv1进行微调比从零开始训练效果更好。相对较小的网络性能优于incepepe - resnet模型并不令人惊讶,因为在更深层次的模型中需要学习更多的参数。为了进一步的实验和引入协方差池,我们使用了来自[16]的基线模型
2、Incorporation of SPD Manifold Network
如上所述,我们引入协方差池,并在最后一个卷积层之后引入来自SPD manifold network网络(SPDNet)的层。在引入协方差池的同时,我们对体系结构的各种模型进行了实验。表2总结了所考虑的各种模型的细节。

Results on Image-based Problem
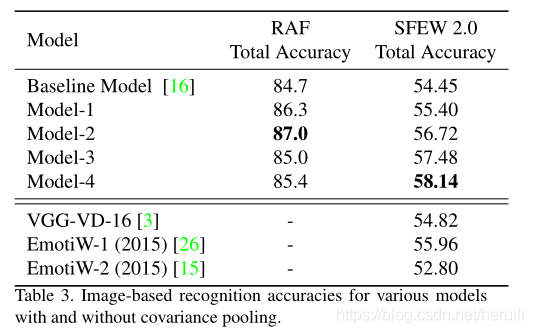
在最终卷积层之后和完全连接层之前使用协方差池。表2中描述的各种模型及其精度见表3。如前所述,对于RAF数据库,网络以端到端方式进行培训。然而,对于SFEW 2.0数据集,我们使用倒数第二个完全连接层的输出(根据所考虑的模型,该层的维数从128到2000不等)。值得指出的是,对于SFEW 2.0,我们的单一模型在[26]和[15]中表现优于卷积神经网络的集成。可以认为,用于预培训的数据集在我们的案例和[26][15]中是不同的。然而,该指标较基线水平提高了近3.7%在SFEW 2.0 dataset证明使用SPDNet进行面部表情识别是合理的。
Conclusion:
在这项工作中,我们利用SPDNet来解决人脸表情识别问题。如上图所示,SPDNet应用于卷积特征的协方差可以更有效地对面部表情进行分类。研究表明,二阶网络能够较好地捕捉人脸特征
扭曲。同样,将图像特征向量计算得到的协方差矩阵作为SPDNet的输入,用于基于视频的人脸表情识别问题。
我们能够在SFEW2.0和RAF数据集上获得基于图像的面部表情识别问题的state-of-the-art结果。在基于视频的人脸表情识别中,基于图像特征的SPDNet训练能够获得与最先进的结果相媲美的结果。

- 表情识别论文阅读——Island Loss for Learning Discriminative Features in Facial Expression Recognition
- 论文笔记 Deep Facial Expression Recognition: A Survey深度面部表情识别调查
- Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks 视频人脸表情识别论文学习笔记
- Face Expression Recognition with a 2-Channel Convolutional Neural Network(基于双通道卷积神经网络的表情识别部分翻译)
- 场景识别“Learning Deep Features for Scene Recognition using Places Database”
- 【深度学习】论文导读:图像识别中的深度残差网络(Deep Residual Learning for Image Recognition)
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
- 图像识别3-VGGNet-very deep convolutional Network for large-scale image recognition
- 【笔记】SPP-Net : Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- [译]CS231n 卷积神经网络对于图像识别的应用--(一)(CS231n Convolutional Neural Networks for Visual Recognition)
- [SPP-NET]Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- 【论文笔记】Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Paper-[acmi 2015]Image based Static Facial Expression Recognition with Multiple Deep Network Learning
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Facial Expression Recognition
- 人脸识别 - A Discriminative Feature Learning Approach for Deep Face Recognition
- 用于对象识别的最好的多级结构是什么?(What is the Best Multi-Stage Architecture for Object Recognition)
- 人脸表情识别文章 A Micro-GA Embedded PSO Feature Selection Approach to Intelligent Facial Emotion Recognitio
- 人脸识别--SphereFace: Deep Hypersphere Embedding for Face Recognition
- (SPP-net)Spatial Pyramid Pooling in deep convolutional networks for visual recognition