论文解读| Very Deep Convolutional Networks for Large-Scale Image Recognition
这个不做翻译了,网上太多了。如果想看,看看这篇博文,对论文进行了翻译。有时间我都抄来,嘿嘿。
https://blog.csdn.net/abc_138/article/details/80568450
https://blog.csdn.net/abc_138/article/details/80568450
vgg的用途
vgg的作用,分类图片,定位跟踪目标。其论文主要阐述了不同模型的深度对于分类图片准确度的影响。对于神经网路的研究主要分为几个方面,模型深度,参数复杂度,模型结构,运行速度。而这里强调的是模型深度。
vgg论文浅谈
谈谈对比试验
下图为结构对比。说明下含义,
1.以列为一个模型A到E;
2.conv3-64的含义是,卷积,卷积核为3*3,64,卷积层参数表示为“conv〈感受野大小〉-通道数〉”。为了简洁起见,不显示ReLU激活功能。还有conv1-*,stride都为1,padding为same;
3.LRN表示局部响应规范化,这种规范化并不能提高在ILSVRC数据集上的性能,但增加了内存消耗和计算时间。;
4.每层的激活函数为Relu;
5.5个2x2 max pool层,stride为2,目的是降低图片size。
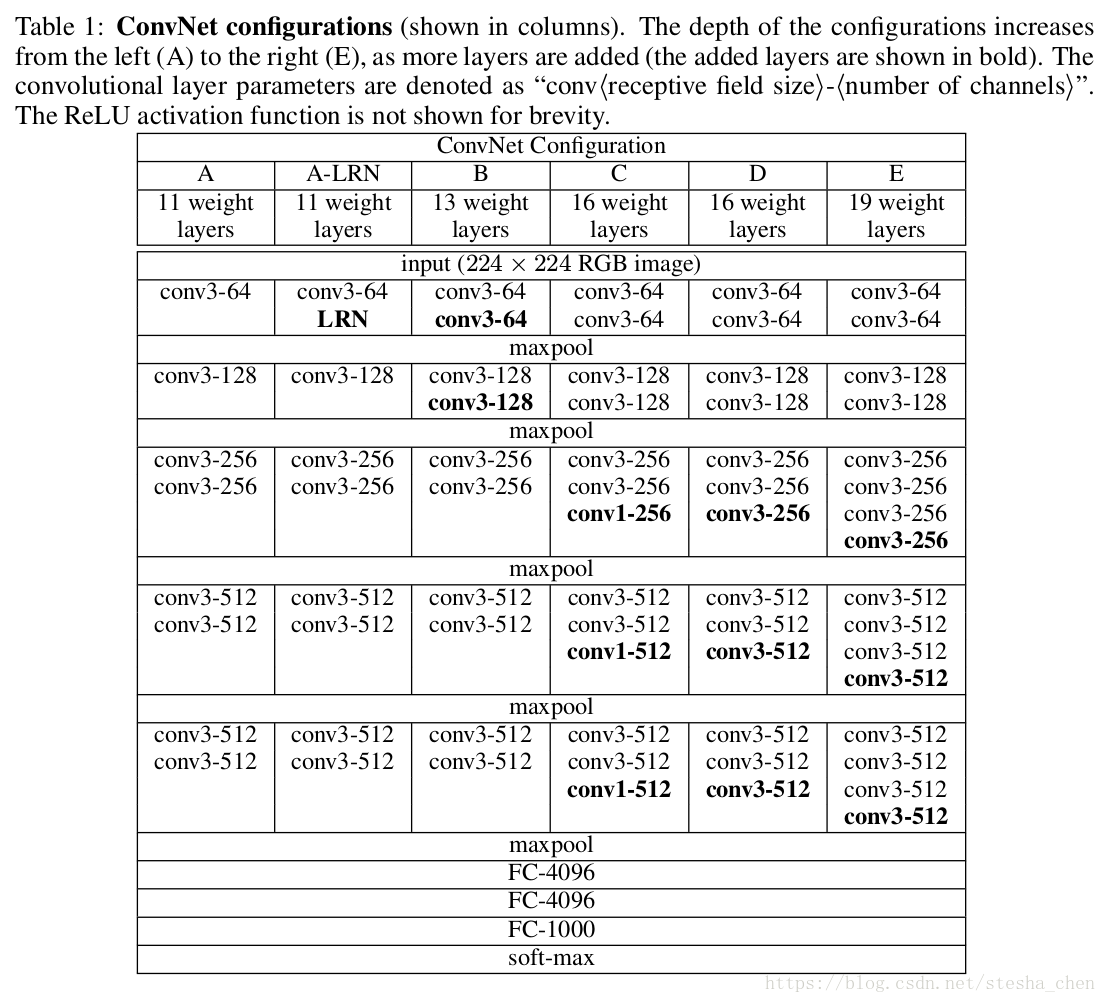
其中表现最好的两个网络为D,E,也就是vgg16,vgg19。他们被应用用到很多环境中,比如neural-style网络。
下面这个表,每个模型的配置的参数数量,单位为兆,M。尽管深度很大,我们的网络中权重数量并不大于具有更大卷积层宽度和感受野的较浅网络中的权重数量

下图以VGG-19为例显示网络结构
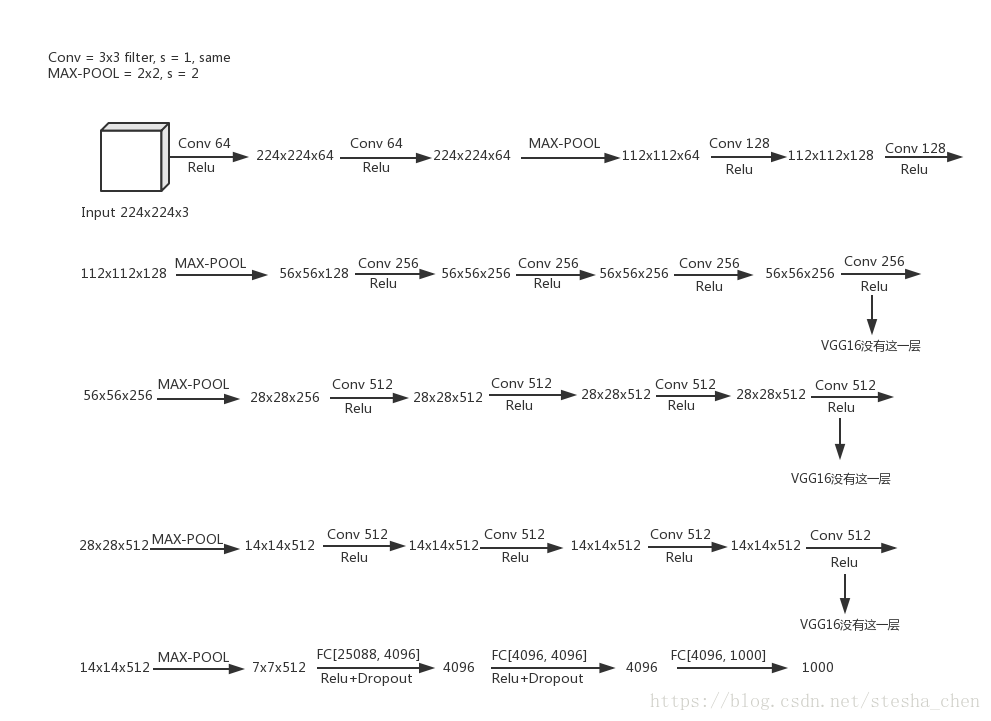
文中提到了用3x3卷积核来替代5x5和7x7卷积核的原因。因为两个3x3的卷积核可以达到5x5的卷积核的效果,三个3x3的卷积核能够达到7x7的卷积核的效果,但是参数数量会大大减少。举个例子:如果输入一张5x5x3的图片,经过两次3x3的卷积运算可以得到1x1x1的结果,跟经过一次5x5的卷积运算效果一样。但是前者参数量只有后者的18/25倍。如果用三个3x3的卷积核参数量只有用7x7的卷积核的27/49倍。论文中提到的是7x7的参数量比用3x3的多了81%(49/27-1). 而且我们用两个或者三个3x3的卷积核就增加几次非线性激励,对结果是有益处的。这个为后面的研究员对模型压缩起到了很重的启示。
训练
训练的基本超参数和数据处理:
batchsize为256,momentum为0.9
- 正则化方法采用weight decay(L2罚函数乘子设为0.0005)和最后两层FC进行dropout(keep_prob=0.5)
- learning rate设置为0.01,当在验证集上的精度停止提高时学习率除以10进行速率降低
- 训练数据随机剪裁,水平翻转,随机RGB颜色转移
学习率降低了3次,并且在370K次迭代(74次训练)之后停止学习
参数初始化的小技巧:
对最简单的网络结构A用随机参数初始化后进行预先训练。当训练更深的网络时,用结构A训练出来的参数来初始化前四个卷基层和后三个FC层,中间其他曾参数还是随机初始化。随机初始化是均值为0,方差为0.01的正态分布中生成初始化权重值。bias还是初始化为0.也可以用固定的值作为学习率。
训练图片处理:
把原始图像缩放到最小边S不小于224,然后在整幅图像上提取224*224片段来进行训练。还有一步预处理,求图片的均值,做差。
评估方法
方法1:在不同的尺度下,训练多个分类器:分别设置S=256,和S=384,然后进行裁切来训练两个模型,使用两种模型来评估。
方法2:在[256, 512]中随机选取一个S,然后在进行裁切来训练模型,相当于尺寸抖动的数据增强
总结
优点:
网络结构简单,容易部署
提出了网络深度对精确度的正面影响,奠定了基础,以后的论文很多都在考虑如何让网络更深,比如Resnet-50, Resnet-101等
提出了使用更小的filter 3x3进行重叠比7x7的filter更有判别力,而且参数减少81%
缺点:
需要训练的特征数量巨大,包含多达约 1.38 亿个参数。
如果继续增加深度,可能无法提升精度了
Tensorflow网络实现,
下面代码我是抄的,在tensorlfow.contrib.slim的doc中有一个vgg16的例子,可以参考。
代码参考tensorflow源码中的实现进行分析,tensorflow vgg code
这部分的代码实现是在slim模块中。slim模块是google2016年推出的,主要用来做代码瘦身,里面提供了很多很方便的接口能够一句代码代替以前很多句代码的实现。而且里面还有一些主流网络结构的实现,可以直接调用来使用网络。比如如果想使用vgg网络来进行实验只需要下面两句代码:
[code]with slim.arg_scope(vgg.vgg_arg_scope()): outputs, end_points = vgg.vgg_16(inputs)
关于slim接口的更多内容以后可以专门写一篇详细的介绍。通过读google对各种流行网络结构的代码实现我觉得是一个非常好的了解网络的方式,代码实现中会有比论文中更多的细节,而且有些论文确实可能在一些细节上有会错误。
vgg.py中实现了论文中的A,D,E三个网络,分别在函数vgg_a,vgg_16和vgg_19中实现。下面以vgg_19为例来分析代码,但是在看vgg_19代码之前需要先了解一下vgg_arg_scope函数。
[code]def vgg_arg_scope(weight_decay=0.0005): with slim.arg_scope([slim.conv2d, slim.fully_connected], activation_fn=tf.nn.relu, weights_regularizer=slim.l2_regularizer(weight_decay), biases_initializer=tf.zeros_initializer()): with slim.arg_scope([slim.conv2d], padding='SAME') as arg_sc: return arg_sc
这个函数主要是利用slim.arg_scope对slim.conv2d和slim.fully_connected进行一些默认值设定。激活函数默认为relu,正则化是l2_regularizer,bias的初始化函数以及默认padding是same。使用arg_scope的好处是如果后面使用slim.conv2d或者fully_connected的时候设置了不一样的值也是可以生效的,如果不设置就用现在设置的默认值。
[code] with tf.variable_scope(scope, 'vgg_19', [inputs]) as sc: end_points_collection = sc.original_name_scope + '_end_points' # Collect outputs for conv2d, fully_connected and max_pool2d. with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d], 268c3 outputs_collections=end_points_collection):
在vgg_19函数开始前,又通过arg_scope对conv2d,fully_connected,max_pool2d设置了outputs_collections的默认值。这个是将conv2d,fully_connected,max_pool2d返回的值放入end_points_collection这个collection中,以后可以通过tf.get_collection(end_points_collection)来获取所有的返回值。类似于tensorflow会把所有可训练的variables放入'trainable_variables'这个名字的collection中,后面可以通过tf.get_collection('trainable_variables')来获取所有的可训练的参数。
[code] net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') net = slim.max_pool2d(net, [2, 2], scope='pool1') net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') net = slim.max_pool2d(net, [2, 2], scope='pool2') net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool3') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4') net = slim.max_pool2d(net, [2, 2], scope='pool4') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5') net = slim.max_pool2d(net, [2, 2], scope='pool5')
接着短短10行代码就实现了16层的conv加上5层的pool,是因为slim.repeat可以非常精炼的实现重复的conv计算。slim(x, n, fn, ...)表示fn重复调用n次。
[code] net = slim.conv2d(net, 4096, [7, 7], padding=fc_conv_padding, scope='fc6') net = slim.dropout(net, dropout_keep_prob, is_training=is_training, scope='dropout6') net = slim.conv2d(net, 4096, [1, 1], scope='fc7') ... net = slim.dropout(net, dropout_keep_prob, is_training=is_training, scope='dropout7') net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, normalizer_fn=None, scope='fc8')
接着的代码代表这最后的三层FC和前两层FC的dropout。这里用conv来代替FC,也是现在比较主流的做法。
VGG fine-tuning
如果我们只是想使用已经训练出来的vgg网络来预测自己的数据集,就只需要对最后基层进行fine-tune即可。关于这部分我在github上有一个简单的实现,vgg fine-tuning
[code]
def loadModel(self, sess, isFineTuring=False):
wData = np.load(self.modelpath, encoding='bytes').item()
for name in wData:
with tf.variable_scope(name, reuse=True):
for p in wData[name]:
if len(p.shape) == 1:
# bias
if name.startswith('conv'):
sess.run(tf.get_variable(name+'/bias', trainable=False).assign(p))
elif (not name.startswith('fc8')) or (not isFineTuring):
sess.run(tf.get_variable('b', trainable=False).assign(p))
else:
# weights
if name.startswith('conv'):
sess.run(tf.get_variable(name+'/kernel', trainable=False).assign(p))
elif (not name.startswith('fc8')) or (not isFineTuring):
sess.run(tf.get_variable('w', trainable=False).assign(p))
在loadModel中将训练成熟的weights解析出来,赋值给我们自己的参数。如果只是需要预测就将所有参数都赋值,进行预测就好了,如果需要fine-tuning,可以将最后几层不进行赋值,然后用自己的数据进行trainning,就可以比较快的得到符合自己数据的weights。原始weights的下载地址可以从中vgg weights找到。
总结
入门级网络;应用在很多场景。

- 深度学习论文随记(二)---VGGNet模型解读-2014年(Very Deep Convolutional Networks for Large-Scale Image Recognition)
- 【Paper Note】Very Deep Convolutional Networks for Large-Scale Image Recognition——VGG(论文理解)
- 论文笔记 | VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE -SCALE IMAGE RECOGNITION
- VGG-16、VGG-19(论文阅读《Very Deep Convolutional NetWorks for Large-Scale Image Recognition》)
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 论文学习
- 《Very Deep Convolutional Networks for Large-Scale Image Recognition》论文阅读
- Very Deep Convolutional Networks for Large-Scale Image Recognition—VGG论文翻译—中文版
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION 这篇论文
- [论文解读]VGGNet:Very Deep Convolution Networks for Large-Scale Image Recognition
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
- 深度学习研究理解10:Very Deep Convolutional Networks for Large-Scale Image Recognition
- Very Deep Convolutional Networks for Large-Scale Image Recognition
- Very Deep Convolutional Networks for Large-Scale Image Recognition
- VGG论文《Very Deep Convolutional Networks For Large Scale Image Recognition》总结
- 深度学习研究理解10:Very Deep Convolutional Networks for Large-Scale Image Recognition
- Very Deep Convolutional Networks for Large-Scale Image Recognition(VGG模型)
- Very Deep Convolutional NetWorks for Large-Scale Image Recognition
- VGG - Very Deep Convolutional Networks for Large-Scale Image Recognition
- 2014-VGG-《Very deep convolutional networks for large-scale image recognition》翻译
- (占坑专用)VGG: Very Deep Convolutional Networks for Large-Scale Image Recognition