表情识别LDTP算法(Local Directional Ternary Pattern for Facial Expression Recognition TIP 2017)
表情识别LDTP算法(Local Directional Ternary Pattern for Facial Expression Recognition TIP 2017)
1.表情识别流程
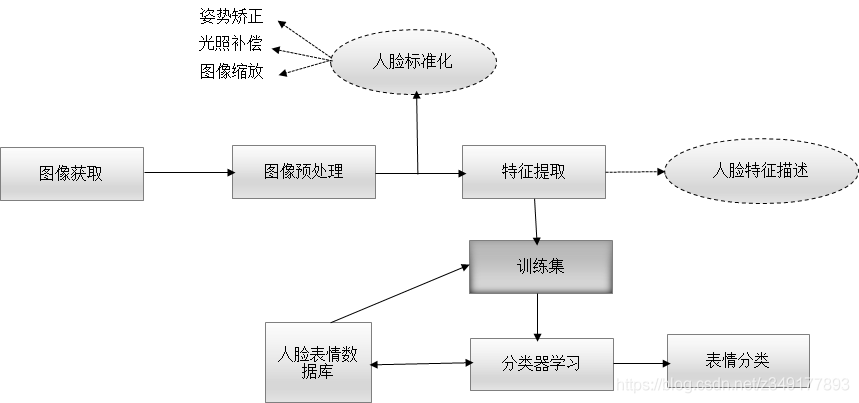
2.研究背景
根据提取对象的不同,可以分为静态方法和动态方法。
1)静态图像的特征提取(用于无变化的静止图片):
基于几何特征(AAM,ASM等):主要是通过对主要面部组件的位置关系进行编码,例如眼睛,鼻子,嘴巴等,可以得到五官的大小、位置及五官之间的相互比例等空间几何信息,可通过这些信息进行人脸表情识别。然而,这种识别的性能依赖于面部组件的确切位置,而这些位置很难根据面部表情的外观变化来察觉。
基于外貌特征(Gabor滤波器,2DPCA,LBP,LDP,LDN等):该方法就可以直接避免上述问题,通过对整个面部图像或局部人脸区域使用图像滤波器滤波,进而检测到人脸外观变化时面部组件的确切位置,以用来提取与表情相关的特征。
2)动态图像序列的特征提取(动态的图像序列 ):
动态的图像序列反映了人脸表情的一个动态变化过程,主要的特征提取方法有光流法,特征点跟踪法,模型跟踪法,弹性图匹配法等。
3.基于存在的问题
提取基于边缘的局部特征的直方图表示的方法证明在面部表情识别中是成功的,因为与情绪相关的面部特征具有突出的梯度值,但是,这些具有直方图表示的基于边缘的局部方法仍然存在问题。
在面部图像的平滑区域中提取基于边缘的局部特征使得对噪声极为敏感并且对分类结果产生负面影响。 面部特征的空间信息在表情识别中起着重要作用,但直方图表示法不能提供充足的空间信息。
而该论文所提出的面部描述子能够克服上述问题,从而更好的实现表情的分类。
4.创新点1—LDTP的编码方案
该论文是将原始图像与Robinson掩码进行卷积运算,将绝对值大第一和第二大的值所对应的掩码序号作为编码后像素值的一部分(八位二进制数中的第1、2位和第5、6位(从右往左数));然后根据所包含像素的比例来确定一个阈值,根据上一步骤得到的第一大和第二大值与这个阈值作比较,进而由下面这个公式来确定编码后像素值的另一部分(八位二进制数中的第3、4位和第7、8位(从右往左数))。
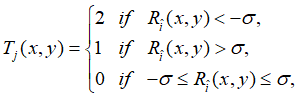
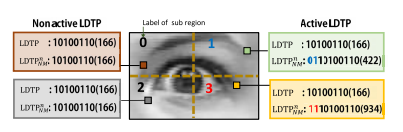
5.创新点2—LDTP的面部描述
在一般的基于直方图的描述中,空间信息是从放置在面部中的二维规则网格中提取出来的。 然而,这种策略效率低,因为它同样重视面部所有特征的空间信息。但事实上,与情绪相关特征的空间信息远比其他特征重要。而LDTP编码会经常出现在与情绪相关的面部特征上,并为它们分配更多的空间信息。故给这些与特征相关的像素重新编码,并称它们为活跃的LDTP码。
1)先标记特征点(这里调用了dlib库来标记点,论文中是用AAM算法,选取眼睛鼻子嘴巴眉毛的特征点(42个))

以选取的特征点为中心,选取大小为1717的块,鼻子比较特殊,选取3333的块。
2)添加位置信息
从这些块中选取出现最为频繁的LDTP码,根据如下公式来选取活跃码,然后给这些码重新编码,也就是给它们添加位置信息。

由于处于活动状态的LDTP码的空间信息对面部表情识别的影响更大,故我们将局部区域划分为子区域,每个子区域都有一个唯一的标签。 通过组合位置标签向活动LDTP编码中添加更多的空间信息。如下图所示:
5.分类
论文中用的是一对一的SVM分类器,采取自动寻参、交叉验证的方式。

- 表情识别——Covariance Pooling for Facial Expression Recognition
- 表情识别论文阅读——Island Loss for Learning Discriminative Features in Facial Expression Recognition
- 表情识别综述2018-Deep Facial Expression Recognition: A Survey
- Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks 视频人脸表情识别论文学习笔记
- 论文笔记 Deep Facial Expression Recognition: A Survey深度面部表情识别调查
- Face Expression Recognition with a 2-Channel Convolutional Neural Network(基于双通道卷积神经网络的表情识别部分翻译)
- (1) Facial expression recognition based on Local Binary Patterns: A comprehensive study
- Paper-[arXiv 1710.03144]Island Loss for Learning Discriminative Features in Facial Expression
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning 书,章节1.1,多项式曲线拟合(Polynomial Curve Fitting)
- 计算机视觉和模式识别中的稀疏表示(Sparse Representation for Computer Vision and Pattern Recognition)
- 人脸识别(三):2017 Additive Margin Softmax for Face Verification
- 图像识别的深度残差学习Deep Residual Learning for Image Recognition
- 场景识别“Learning Deep Features for Scene Recognition using Places Database”
- SphereFace: Deep Hypersphere Embedding for Face Recognition(人脸识别论文笔记)
- 【CS231n_2017】1-Introduction to CNN for Visual Recognition
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning 书,章节1.1,多项式曲线拟合(Polynomial Curve Fitting)
- 用于对象识别的最好的多级结构是什么?(What is the Best Multi-Stage Architecture for Object Recognition)
- 今天开始学模式识别与机器学习Pattern Recognition and Machine Learning 书,章节1.1,多项式曲线拟合(Polynomial Curve Fitting)
- [译]CS231n 卷积神经网络对于图像识别的应用--(一)(CS231n Convolutional Neural Networks for Visual Recognition)
- 人脸表情识别文章 A Micro-GA Embedded PSO Feature Selection Approach to Intelligent Facial Emotion Recognitio