目标检测算法YOLO-V1算法详解

❝前面我们一起学了
❞SSD算法的相关知识,如下:
SSD目标检测算法必须知道的几个关键点
目标检测算法SSD结构详解
今天我们学习另一系列目标检测算法YOLO(You Only Look Once),公众号【智能算法】回复“论文YOLOV1”即可下载该论文。Yolo系列算法属于One-Stage算法,是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。现在YOLO已经发展到v5版本,不过新版本也是在原有版本基础上不断改进演化的,所以本文先分析YOLO v1版本。一起看看是如何实现的?本期主要包含以下内容:
- YOLO-V1结构剖析
- 为什么是7x7x30的输出?
- 候选框怎么生成?
- 不一样的置信度
- YOLOV1预测流程
YOLO-V1结构剖析
YOLO-V1的核心思想:就是利用整张图作为网络的输入,将目标检测作为回归问题解决,直接在输出层回归预选框的位置及其所属的类别。YOLO和RCNN最大的区别就是去掉了RPN网络,去掉候选区这个步骤以后,YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。单看网络结构的话,和普通的CNN对象分类网络几乎没有本质的区别,最大的差异是最后输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,我们来看下YOLO-V1论文中给出的的结构,如下图:
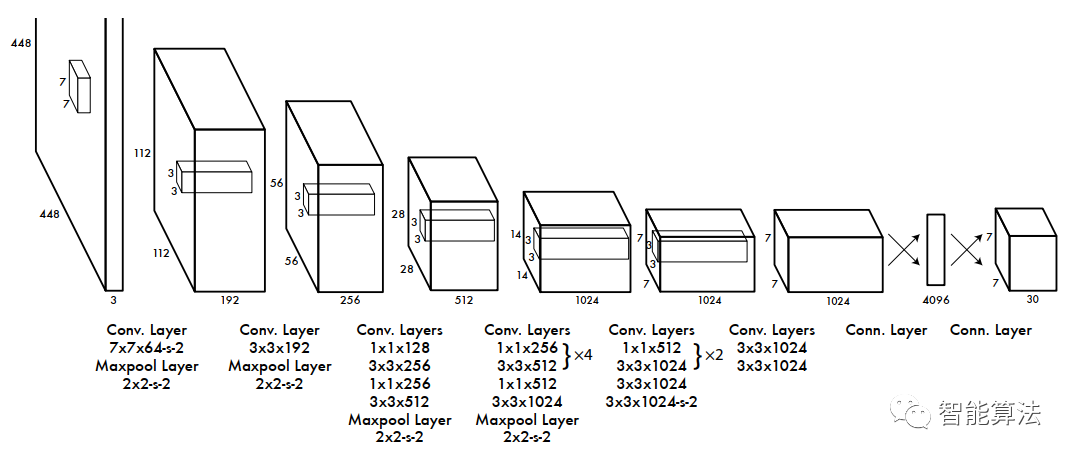 该网络架构借鉴了
该网络架构借鉴了GoogLeNet的思想,改造了其中的InceptionV1网络,只是这里并没有使用原始的inception模块,而是用一个1x1的卷积接联一个3x3的卷积来代替,具体的inception模块和GoogLeNet可参考之前的文章:
CNN经典网络之GoogLeNet
从上图中可以看到,YOLO-V1网络的主要步骤如下:
-
输入图片是
448x448x3,经过一个7x7x64,stride为2的卷积层和一个2x2,stride为2的最大化池化层后得到112x112x192尺寸的特征图。 -
经过一个
3x3x192的卷积层和一个2x2,stride为2的最大化池化层后得到56x56x256尺寸的特征图。这里留一个讨论题,这两步的尺寸变化有没有问题?欢迎大家评论区讨论。 -
经过一个
1x1x128,3x3x256,1x1x256,3x3x512的卷积层和2x2,stride为2的最大化池化层后得到28x28x512的特征图。 -
经过四组
1x1x256,3x3x512的卷积层后再经过1x1x512,3x3x1024的卷积层和一个2x2-s-2的池化层后得到14x14x1024的特征图。 -
经过两组
1x1x512,3x3x1024的卷积层后再经过一个3x3x1024和stride为2的3x3x1024的卷积层后得到7x7x1024的特征图。 -
经过两个
3x3x1024的卷积层后得到7x7x1024的特征图。 -
经过节点为
4096的全连接层后最终得到7x7x30(其实是一个一维向量的三维化)的检测结果。
整个算法的大致流程就是这样,接下来我们看下为什么最终会得到7x7x30的结果?
为什么是7x7x30的输出?
YOLO-V1将一副448x448的原图分割成了7x7=49个网格,每个网格要预测两个bounding box的坐标(x,y,w,h)和box内是否包含物体的置信度confidence(每个bounding box有一个confidence),以及该网格包含的物体属于20类别中每一类的概率(YOLO的训练数据为voc2012,它是一个20分类的数据集)。所以一个网格对应一个(4x2+2+20)=30维度的向量。如下图:
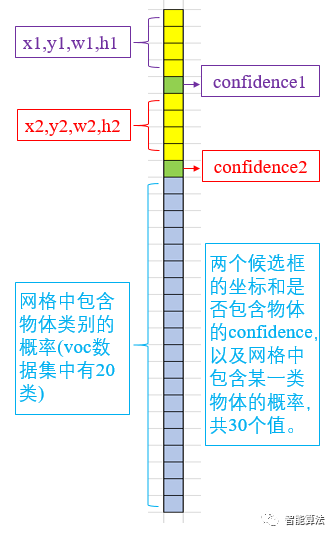
知道了网络的结构,上面提到的候选框怎么生成呢?
候选框怎么生成?
上面提到7x7的每个网格都要预测两个bounding box的坐标和置信度,如下图,以红色网格为例,生成两个大小形状不同的蓝色box,box的位置坐标为(x,y,w,h),其中x和y表示box中心点与该格子边界的相对值,也就是说x和y的大小被限制在[0,1]之间,假如候选框的中心刚好与网格的中心重合,那么x=0.5,y=0.5。w和h表示预测box的宽度和高度相对于整幅图片的宽度和高度的比例,比如图中的框住狗的蓝色网格的宽度w大致为1/3,高度h大致为1/2。这样(x,y,w,h)就都被限制在[0,1]之间,与训练数据集上标定的物体的真实坐标(Gx,Gy,Gw,Gh)进行对比训练,每个网格负责预测中心点落在该格子的物体的概率。
 YOLO-V1候选框生成
YOLO-V1候选框生成
每个box预测的置信度只是为了表达box内有无物体的概率(类似于Faster R-CNN中RPN层的softmax预测anchor是前景还是背景的概率),并不预测box内物体属于哪一类。那么这个置信度有什么用呢?
不一样的置信度
这里面的置信度跟前面学的置信度有一些些不同。以前我们理解的置信度只是一个简单的得分,一个对该物体预测的概率值。YOLO中的置信度公式如下:
其中前一项表示有无人工标记的物体落入网格内,如果有,则为1,否则为0.第二项表示bounding box和真实标记的box之间的IOU,值越大则表示box越接近真实位置。confidence是针对bounding box的,每个网格有两个bounding box,所以每个网格会有两个confidence与之对应。
预测流程
知道了网络框架,候选框的生成,以及置信度的定义,我们看下YOLO-V1预测工作流程是怎么样的?
-
对输入图片进行网格划分,每个格子生成两个
bounding boxes. -
每个网格预测的
class信息和bounding boxes预测的confidence信息相乘,得到每个bounding box预测具体物体的概率和位置重叠的概率PrIOU
其中
为每个网格预测的class信息,为confidence。3. 最后对于每个类别,对PrIOU进行排序,去除小于阈值的PrIOU,然后做非极大值抑制。

至此,我们学习了目标检测算法YOLO-V1算法的结构框架和工作流程,明白了YOLO-V1模型的基本知识,下期我们深入一步学下该模型的损失函数以及优缺点。
♥分享在看也是一种支持♥
本文分享自微信公众号 - 智能算法(AI_Algorithm)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

- 目标检测算法YOLO-V2详解
- 目标检测算法(R-CNN,SPPNet,Fast-R-CNN,Faster-R-CNN,YOLO,SSD)
- YOLO——基于回归的目标检测算法
- 目标检测算法学习----YOLOv1
- 目标检测:YOLOv2算法详解
- 目标检测算法之一 YOLO初步讲解
- 【深度学习】目标检测算法总结(R-CNN、Fast R-CNN、Faster R-CNN、FPN、YOLO、SSD、RetinaNet)
- 【深度学习】目标检测算法 YOLO 最耐心细致的讲解
- 【目标检测】SSD算法--损失函数的详解(tensorflow实现)
- 目标检测算法的另一分支(one stage检测算法):YOLO、SSD、YOLOv2/YOLO 9000、YOLOv3
- 【深度学习】目标检测算法总结(R-CNN、Fast R-CNN、Faster R-CNN、FPN、YOLO、SSD、RetinaNet)...
- 在iOS上实现YOLO目标检测算法
- 目标检测之YOLO算法
- (六)目标检测算法之YOLO
- Yolo-lite:实时的适用于移动设备的目标检测算法(比ssd和mobilenet更快)
- 【目标检测】SSD算法—-模型结构的详解及Python源码分析
- 目标检测Tensorflow:Yolo v3代码详解 (2)
- 【目标检测】RCNN 算法详解(中)
- 基于深度学习的目标检测算法:YOLO
- 一文详解 YOLO 2 与 YOLO 9000 目标检测系统