机器学习三人行(系列十)----机器学习降压神器(附代码)


系列九我们从算法组合的角度一起实战学习了一下组合算法方面的知识,详情戳下链接:
机器学习三人行(系列九)----千变万化的组合算法(附代码)
但是,我们也知道算法组合会造成整体算法时间成本的增加,所以今天我们从降维的角度来看下,如何给算法降低时间成本。
在这一期中,我们将主要讨论一下几方面内容:
维度灾难
降维的主要途径
PCA(主成分分析)
Kernel PCA
LLE(局部线性嵌入)
文末附相关代码关键字,可在公众号中回复关键字下载查看。
一. 维度灾难
许多机器学习问题涉及特征多达数千乃至数百万个。正如我们将看到的,这不仅让训练变得非常缓慢,而且还会使得找到一个好的解决方案变得更加困难。这个问题通常被称为维度灾难。
幸运的是,在现实世界的问题中,通常可能会减少特征的数量,从而将棘手的问题变成易于处理的问题。例如,考虑MNIST图像(在系列四中介绍):图像边界上的像素几乎总是白色的,所以你可以从训练集中完全丢弃这些像素而不会丢失太多信息。 而且,两个相邻像素通常是高度相关的:如果将它们合并成一个像素(例如,通过取两个像素强度的平均值),则不会丢失太多信息。
除了加速训练之外,降维对于数据可视化(或DataViz)也非常有用。将维度数量减少到两个(或三个)使得可以在图表上绘制高维训练集,并且通常通过视觉上检测诸如集群的图案来获得一些重要的见解。
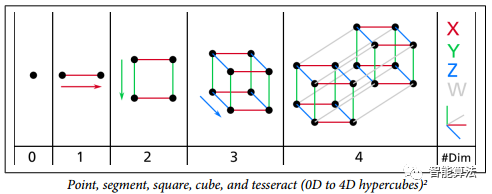
我们习惯于三维生活,当我们试图想象一个高维空间时,我们的直觉失败了。即使是一个基本的4D超立方体,在我们的脑海中也难以想象,如下图,更不用说在1000维空间弯曲的200维椭球。
事实证明,许多事物在高维空间中表现得非常不同。例如,如果你选择一个单位平方(1×1平方)的随机点,它将只有大约0.4%的机会位于小于0.001的边界(换句话说,随机点将沿任何维度“极端”这是非常不可能的)。但是在一个10000维单位超立方体(1×1×1立方体,有1万个1)中,这个概率大于99.999999%。高维超立方体中的大部分点都非常靠近边界。
这更难区分:如果你在一个单位平方中随机抽取两个点,这两个点之间的距离平均约为0.52。如果在单位三维立方体中选取两个随机点,则平均距离将大致为0.66。但是在一个100万维的超立方体中随机抽取两点呢?那么平均距离将是大约408.25(大约1,000,000 / 6)!
这非常违反直觉:当两个点位于相同的单位超立方体内时,两点如何分离?这个事实意味着高维数据集有可能非常稀疏:大多数训练实例可能彼此远离。当然,这也意味着一个新实例可能离任何训练实例都很远,这使得预测的可信度表现得比在低维度数据中要来的差。简而言之,训练集的维度越多,过度拟合的风险就越大。
理论上讲,维度灾难的一个解决方案可能是增加训练集的大小以达到足够密度的训练实例。不幸的是,在实践中,达到给定密度所需的训练实例的数量随着维度的数量呈指数增长。如果只有100个特征(比MNIST问题少得多),那么为了使训练实例的平均值在0.1以内,需要比可观察宇宙中的原子更多的训练实例,假设它们在所有维度上均匀分布。
二. 降维的主要途径
在深入研究具体的降维算法之前,我们来看看降维的两种主要途径:投影和流形学习。
2.1 投影
在大多数现实世界的问题中,训练实例并不是在所有维度上均匀分布。许多特征几乎是常量,而其他特征则高度相关(如前面讨论MNIST)。结果,所有训练实例实际上位于(或接近)高维空间的低维子空间内。这听起来很抽象,所以我们来看一个例子。在下图中,我们可以看到由圆圈表示的三维数据集。
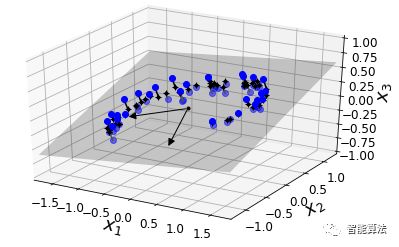
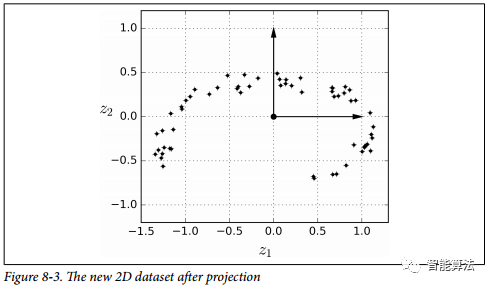
请注意,所有训练实例都靠近一个平面:这是高维(3D)空间的较低维(2D)子空间。现在,如果我们将每个训练实例垂直投影到这个子空间上(如连接实例到平面的短线所表示的那样),我们就得到如下图所示的新的2D数据集。当当!我们刚刚将数据集的维度从3D减少到了2D。请注意,轴对应于新的特征z1和z2(平面上投影的坐标)。
然而,投影并不总是降维的最佳方法。在许多情况下,子空间可能会扭曲和转动,如下图所示的著名的瑞士滚动玩具数据集。
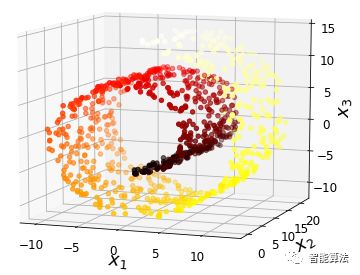
简单地投射到一个平面上(例如,通过丢弃特征x3)将会把瑞士卷的不同层挤压在一起,如下图的左边所示。但是,您真正需要的是展开瑞士卷,以获得下图右侧的2D数据集。
2.2 流形学习
瑞士卷是二维流形的一个例子。简而言之,二维流形是一种二维形状,可以在更高维空间中弯曲和扭曲。更一般地,d维流形是局部类似于d维超平面的n维空间(其中d <n)的一部分。在瑞士卷中,d = 2和n = 3:它在局部上类似于2D平面,但是在第三维上滚动。
许多降维算法通过对训练实例所在的流形进行建模来工作; 这叫做流形学习。它依赖于流形假设,也被称为流形假设,它认为大多数现实世界的高维数据集靠近一个低得多的低维流形。这种假设通常是经验性观察到的。
再次考虑MNIST数据集:所有的手写数字图像都有一些相似之处。它们由连线组成,边界是白色的,或多或少居中,等等。如果你随机生成图像,只有一小部分看起来像手写数字。换句话说,如果您尝试创建数字图像,可用的自由度远远低于您可以生成任何想要的图像的自由度。这些约束倾向于将数据集压缩到较低的维度。
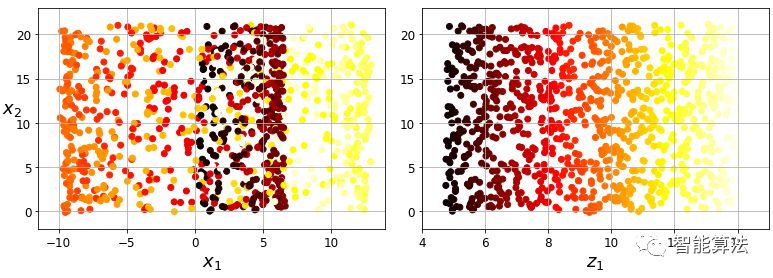
流形假设通常伴随另一个隐含的假设:如果在流形的较低维空间中表示,手头的任务(例如分类或回归)将更简单。例如,在下图的第一行中,瑞士卷被分成两类:在三维空间(在左边),决策边界相当复杂,但是在2D展开的流形空间(在右边 ),决策边界是一条简单的直线。
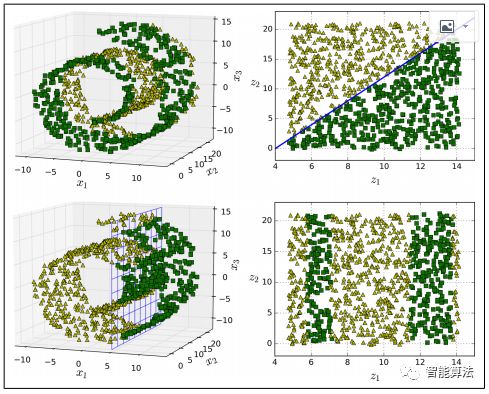
但是,这个假设并不总是成立。例如,在上图右侧,判定边界位于x1 = 5。这个判定边界在原始三维空间(一个垂直平面)看起来非常简单,但是在展开的流形中它看起来更复杂 四个独立的线段的集合)。
简而言之,如果在训练模型之前降低训练集的维数,那么肯定会加快训练速度,但并不总是会导致更好或更简单的解决方案。这一切都取决于数据集。
到这里我们基本能够很好地理解维度灾难是什么,以及维度减少算法如何与之抗衡,特别是当多种假设成立的时候。那么接下来我们将一起学习一下常见的降维算法。
三. PCA(主成分分析
主成分分析(PCA)是目前最流行的降维算法。主要是通过识别与数据最接近的超平面,然后将数据投影到其上。
3.1 保持差异
在将训练集投影到较低维超平面之前,您首先需要选择正确的超平面。例如,简单的2D数据集连同三个不同的轴(即一维超平面)一起在下图的左侧表示。右边是将数据集投影到这些轴上的结果。正如你所看到的,在c2方向上的投影保留了最大的方差,而在c1上的投影保留了非常小的方差。
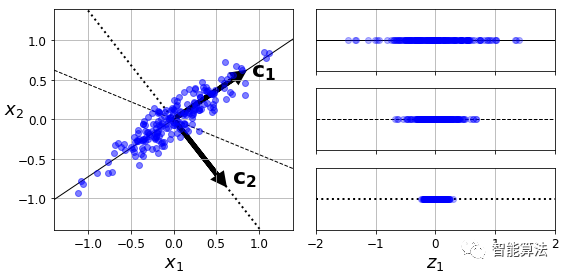
选择保留最大变化量的轴似乎是合理的,因为它最有可能损失比其他投影更少的信息。证明这一选择的另一种方法是,使原始数据集与其在该轴上的投影之间的均方距离最小化的轴。这是PCA背后的一个相当简单的想法。
3.2 PCA中的PC
主成分分析(PCA)识别训练集中变化量最大的轴。在上图中,它是实线。它还发现第二个轴,与第一个轴正交,占了剩余方差的最大量。如果它是一个更高维的数据集,PCA也可以找到与前两个轴正交的第三个轴,以及与数据集中维数相同的第四个,第五个等。
定义第i个轴的单位矢量称为第i个主成分(PC)。在上图中,第一个PC是c1,第二个PC是c2。在2.1节的图中,前两个PC用平面中的正交箭头表示,第三个PC与平面正交(指向上或下)。
主成分的方向不稳定:如果稍微扰动训练集并再次运行PCA,一些新的PC可能指向与原始PC相反的方向。但是,他们通常仍然位于同一轴线上。在某些情况下,一部分的PC甚至可能旋转或交换,但他们确定的平面通常保持不变。
那么怎样才能找到训练集的主要组成部分呢?幸运的是,有一种称为奇异值分解(SVD)的标准矩阵分解方法,可以将训练集矩阵X分解成三个矩阵U·Σ·VT的点积,其中VT包含我们正在寻找的所有主成分, 如下公式所示。
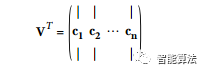
下面的Python代码使用NumPy的svd()函数来获取训练集的所有主成分,然后提取前两个PC:

3.3 投影到d维度
一旦确定了所有主要组成部分,就可以将数据集的维数降至d维,方法是将其投影到由第一个主要组件定义的超平面上。选择这个超平面确保投影将保留尽可能多的方差。例如,在2.1节中的数据集中,3D数据集向下投影到由前两个主成分定义的2D平面,从而保留了大部分数据集的方差。因此,二维投影看起来非常像原始的三维数据集。
为了将训练集投影到超平面上,可以简单地通过矩阵Wd计算训练集矩阵X的点积,该矩阵定义为包含前d个主分量的矩阵(即,由VT的前d列组成的矩阵 ),如下公式所示。
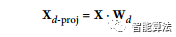
以下Python代码将训练集投影到由前两个主要组件定义的平面上:

现在我们已经知道如何将任何数据集的维度降低到任意维数,同时尽可能保留最多的差异。
3.4 使用Scikit-Learn
Scikit-Learn的PCA类使用SVD分解来实现PCA,就像我们之前做的那样。以下代码应用PCA将数据集的维度降至两维:

在将PCA变换器拟合到数据集之后,可以使用components_变量访问主成分(注意,它包含水平向量的PC,例如,第一个主成分等于pca.components_.T [:,0])。
3.5 解释方差比率
另一个非常有用的信息是解释每个主成分的方差比率,可通过explained_variance_ratio_变量得到。它指明了位于每个主成分轴上的数据集方差的比例。例如,让我们看看图8-2中表示的3D数据集的前两个分量的解释方差比率:

它告诉我们,84.2%数据集的方差位于第一轴,14.6%位于第二轴。第三轴的这一比例不到1.2%,所以可以认为它可能没有什么信息。
3.6 选择正确的维度数量
不是任意选择要减少的维度的数量,通常优选选择加起来到方差的足够大部分(例如95%)的维度的数量。当然,除非我们正在降低数据可视化的维度(在这种情况下,您通常会将维度降低到2或3)。
下面的代码在不降低维数的情况下计算PCA,然后计算保留训练集方差的95%所需的最小维数:

然后可以设置n_components = d并再次运行PCA。但是,还有一个更好的选择:不要指定要保留的主要组件的数量,您可以将n_components设置为0.0到1.0之间的浮点数,表示您希望保留的方差比率:

3.7 PCA压缩
降维后显然,训练集占用的空间少得多。例如,尝试将PCA应用于MNIST数据集,同时保留其95%的方差。你会发现每个实例只有150多个特征,而不是原来的784个特征。所以,虽然大部分方差都被保留下来,但数据集现在还不到原始大小的20%!这是一个合理的压缩比,你可以看到这是如何加速分类算法(如SVM分类器)。
也可以通过应用PCA投影的逆变换将缩小的数据集解压缩回到784维。当然这不会给你原来的数据,因为投影丢失了一点信息(在5%的差异内),但它可能会非常接近原始数据。原始数据与重构数据(压缩然后解压缩)之间的均方距离称为重建误差。例如,以下代码将MNIST数据集(公众号回复“mnist”)压缩到154维,然后使用inverse_transform()方法将其解压缩到784维。下图显示了原始训练集(左侧)的几个数字,以及压缩和解压缩后的相应数字。你可以看到有一个轻微的图像质量损失,但数字仍然大部分完好无损。


如下等式,显示了逆变换的等式。
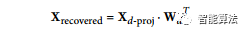
3.8 增量PCA
先于PCA实现的一个问题是,为了使SVD算法运行,需要整个训练集合在内存中。幸运的是,已经开发了增量式PCA(IPCA)算法:您可以将训练集分成小批量,并一次只提供一个小批量IPCA算法。这对于大型训练集是有用的,并且也可以在线应用PCA(即在新实例到达时即时运行)。
下面的代码将MNIST数据集分成100个小批量(使用NumPy的array_split()函数),并将它们提供给Scikit-Learn的IncrementalPCA class5,以将MNIST数据集的维度降低到154维(就像以前一样)。请注意,您必须调用partial_fit()方法,而不是使用整个训练集的fit()方法。

或者,您可以使用NumPy的memmap类,它允许您操作存储在磁盘上的二进制文件中的大数组,就好像它完全在内存中; 该类仅在需要时加载内存中所需的数据。由于IncrementalPCA类在任何给定时间只使用数组的一小部分,因此内存使用情况仍然受到控制。这可以调用通常的fit()方法,如下面的代码所示:

3.9 随机PCA
Scikit-Learn提供了另一种执行PCA的选项,称为随机PCA。这是一个随机算法,可以快速找到前d个主成分的近似值,它比以前的算法快得多。

四. Kernel PCA
在前面的系列中,我们讨论了内核技巧,一种将实例隐式映射到非常高维的空间(称为特征空间)的数学技术,支持向量机的非线性分类和回归。回想一下,高维特征空间中的线性决策边界对应于原始空间中的复杂非线性决策边界。
事实证明,同样的技巧可以应用于PCA,使得有可能执行复杂的非线性投影降维。这被称为内核PCA(KPCA)。在投影之后保留实例簇通常是好的,有时甚至可以展开靠近扭曲流形的数据集。
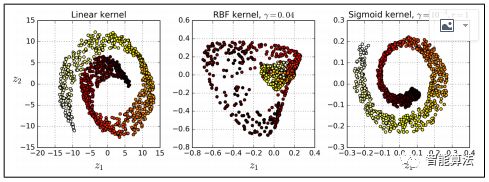
例如,以下代码使用Scikit-Learn的KernelPCA类来执行带RBF内核的KPCA(有关RBF内核和其他内核的更多详细信息,可以参考前面的系列文章):

下图显示了使用线性内核(等同于简单使用PCA类),RBF内核和S形内核(Logistic)减少到二维的瑞士卷。
五. LLE(局部线性嵌入)
局部线性嵌入(LLE)是另一种非常强大的非线性降维(NLDR)技术。这是一个流形学习技术,不依赖于像以前的投影算法。简而言之,LLE通过首先测量每个训练实例如何与其最近的邻居(c.n.)线性相关,然后寻找保持这些本地关系最好的训练集的低维表示。这使得它特别擅长展开扭曲的流形,尤其是在没有太多噪声的情况下。
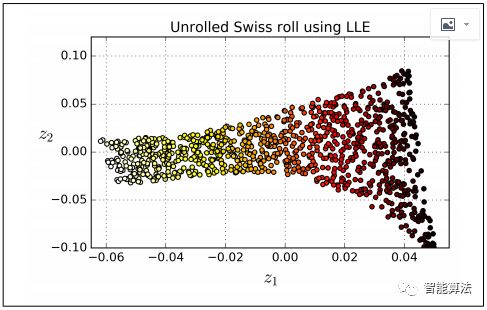
例如,下面的代码使用Scikit-Learn的LocallyLinearEmbedding类来展开瑞士卷。得到的二维数据集如下图所示。正如你所看到的,瑞士卷是完全展开的,实例之间的距离在本地保存得很好。但是,展开的瑞士卷的左侧被挤压,而右侧的部分被拉长。尽管如此,LLE在对多样性进行建模方面做得相当不错。

六. 本期小结
本期我们从维度灾难入手,一起学习了降维的投影和流行分析的主要两种途径,接下来学习了主成分分析,核PCA以及LLE的相关知识,希望从本节我们更详细的了解到有关降维的相知识,以及将其用到工作项目中。
(如需更好的了解相关知识,欢迎加入智能算法社区,在“智能算法”公众号发送“社区”,即可加入算法微信群和QQ群)
本期代码关键字:dim_redu
本文分享自微信公众号 - 智能算法(AI_Algorithm)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

- 机器学习系列(12)_XGBoost参数调优完全指南(附Python代码)
- 机器学习三人行(系列六)----Logistic和Softmax回归实战剖析(附代码)
- 开源神器,无需一行代码就能搞定机器学习,不会数学也能上手
- 开源神器,无需一行代码就能搞定机器学习,不会数学也能上手
- 【机器学习系列】SVD奇异值分解(python代码)
- 机器学习三人行(系列七)----支持向量机实践指南(附代码)
- 【机器学习系列】感知机学习代码
- 机器学习三人行(系列五)----你不了解的线性模型(附代码)
- 开源神器,无需一行代码就能搞定机器学习,不会数学也能上手
- Spark2.0机器学习系列之5:GBDT(梯度提升决策树)、GBDT与随机森林差异、参数调试及Scikit代码分析
- 无需一行代码就能搞定机器学习的开源神器
- 机器学习系列(9)_机器学习算法一览(附Python和R代码)
- <转>机器学习系列(9)_机器学习算法一览(附Python和R代码)
- 机器学习系列(9)_机器学习算法一览(附Python和R代码)
- 开源神器,无需一行代码就能搞定机器学习,不会数学也能上手
- Spark2.0机器学习系列之6:GBDT(梯度提升决策树)、GBDT与随机森林差异、参数调试及Scikit代码分析
- 机器学习系列(9)_机器学习算法一览(附Python和R代码)
- 无需一行代码就能搞定机器学习的开源神器——手把手教你配置使用
- 【机器学习系列之七】模型调优与模型融合(代码应用篇)
- Spark2.0机器学习系列之3:决策树及Spark 2.0-MLlib、Scikit代码分析