【目标检测】SSD算法—-模型结构的详解及Python源码分析
前言
最近在研究SSD算法,感觉SSD是继Faster RCNN之后的最具有开创性的工作,SSD可以和Faster-RCNN的精度与Yolo的速度相媲美,现在很多公司还在应用SSD一类的算法,有必要好好钻研一下。
因此准备写一些对SSD的算法理解,以及一些关键源码的分析。
刚开始啃这一块,如果有问题,辛苦大家指出来。
SSD模型结构
先给出经典的网络结构图,以ssd300为例

可以发现SSD会从六个卷积层上提取信息。低层的如conv4_3主要用来获取一下小目标,到高层如conv10_2,conv11_2是为了获取较大的目标,甚至像图片大小的目标。conv11_2的特征层是1x1的,映射到原图,相当于300x300大小的目标
模型局部分析
从conv4-3层会分出来三条线路,分别是分类器mbox_conf,位置回归mbox_loc,以及锚框的生成priorbox
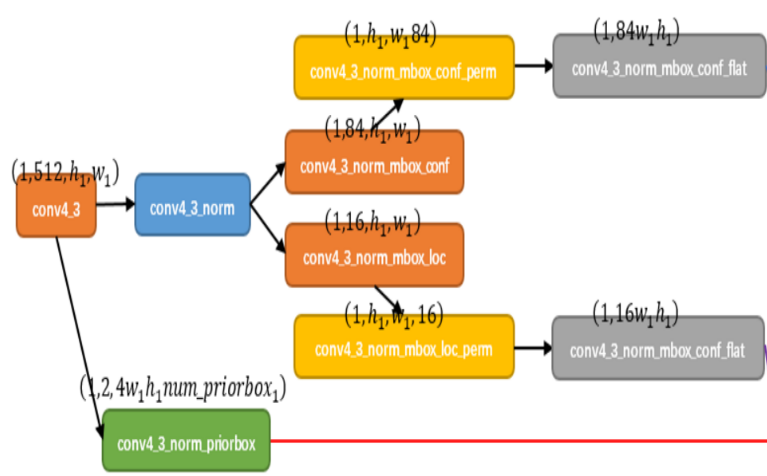
conv4_3层的参数shape是(1,512,h1,w1),1表示batch_size,512代表512个维度的h1,w1的特征图。
经过normalization后,一是连接分类层conn4_3_norm_mbox_conf,此时参数shape为(1,84,h1,w1),84表示4*21。21指类别数(20类+背景),4表示在conv4_3上每个像素点生成4个anchor box,经过mbox_conf_perm层,改变参数shape为(1,h1,w1,84),然后经过mbox_conf_flat层压扁,然后接softmax
另一个连接的是conv4_3norm_mbox_loc,此时参数shape为(1,16,h1,w1).16表示4*4.第一个4表示4个anchor box,第二个4表示4个关于位置的信息xmin,ymin,xmax,ymax,,然后接regression层
还有一条是生成priorbox shape:[1,2,4h1w1num_priorbox ] 2表示2个channel,分别存放四个尺寸(xmin ymin xmax ymax)和对应的四个variance
多featuremap的协作
但是并不是每一层都计算一遍softmax和regression,这样的计算量太大了,因此需要多个featuremap协作,也就是把所有特征层提取的关于类别或者位置的特征concat起来。在接softmax或者regression。具体看下图。
我们会将conv4_3,fc7,conv8_2,conv9_2,conv10_2,conv11_2的类别特征,位置特征和anchor box信息分别concat起来,一起计算softmax或者regression。。

下面展示各个层的mbox_conf,最后concat后的形状。

下面展示各个层的mbox_loc,最后concat后的形状。

下面展示 各个层的priorbox,最后concat后的形状。

最后会把mbox_conf/mbox_lox/mbox_priorbox的信一起concat起来,作为模型的输出,因此输出shape是[boxNum,classes+loc+anchor]
也就是每个图片输入网络,都会获得8732个anchor box,每个box都有

可以发现,输入一张300x300的图片,会生成8732个anchorbox,这些而其中绝大部分都是框到物体的。在计算损失的的时候,要选择合适的正样本和负样本的数量。
关于完整的模型图,想获取的可以点这里
ssd_keras源码分析
1.主体网络
主体网络就是删除了全连接层后的VGG16,因为没有全连接层,所以输入图片的大小可以不固定,300x300或512x512都可以用相同的预训练权重
[code] x = Input(shape=(img_height, img_width, img_channels)) # The following identity layer is only needed so that the subsequent lambda layers can be optional. x1 = Lambda(identity_layer, output_shape=(img_height, img_width, img_channels), name='identity_layer')(x) # 减均值 if not (subtract_mean is None): x1 = Lambda(input_mean_normalization, output_shape=(img_height, img_width, img_channels), name='input_mean_normalization')(x1) if not (divide_by_stddev is None): # 除标准差 x1 = Lambda(input_stddev_normalization, output_shape=(img_height, img_width, img_channels), name='input_stddev_normalization')(x1) if swap_channels: x1 = Lambda(input_channel_swap, output_shape=(img_height, img_width, img_channels), name='input_channel_swap')(x1) conv1_1 = Conv2D(64, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv1_1')(x1) conv1_2 = Conv2D(64, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv1_2')(conv1_1) pool1 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='pool1')(conv1_2) conv2_1 = Conv2D(128, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv2_1')(pool1) conv2_2 = Conv2D(128, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv2_2')(conv2_1) pool2 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='pool2')(conv2_2) conv3_1 = Conv2D(256, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv3_1')(pool2) conv3_2 = Conv2D(256, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv3_2')(conv3_1) conv3_3 = Conv2D(256, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv3_3')(conv3_2) pool3 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='pool3')(conv3_3) conv4_1 = Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv4_1')(pool3) conv4_2 = Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv4_2')(conv4_1) conv4_3 = Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv4_3')(conv4_2) pool4 = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='pool4')(conv4_3) conv5_1 = Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv5_1')(pool4) conv5_2 = Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv5_2')(conv5_1) conv5_3 = Conv2D(512, (3, 3), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv5_3')(conv5_2) pool5 = MaxPooling2D(pool_size=(3, 3), strides=(1, 1), padding='same', name='pool5')(conv5_3)
2.extra feature extract layer
[code] fc6 = Conv2D(1024, (3, 3), dilation_rate=(6, 6), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='fc6')(pool5) fc7 = Conv2D(1024, (1, 1), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='fc7')(fc6) conv6_1 = Conv2D(256, (1, 1), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv6_1')(fc7) conv6_1 = ZeroPadding2D(padding=((1, 1), (1, 1)), name='conv6_padding')(conv6_1) conv6_2 = Conv2D(512, (3, 3), strides=(2, 2), activation='relu', padding='valid', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv6_2')(conv6_1) conv7_1 = Conv2D(128, (1, 1), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv7_1')(conv6_2) conv7_1 = ZeroPadding2D(padding=((1, 1), (1, 1)), name='conv7_padding')(conv7_1) conv7_2 = Conv2D(256, (3, 3), strides=(2, 2), activation='relu', padding='valid', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv7_2')(conv7_1) conv8_1 = Conv2D(128, (1, 1), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv8_1')(conv7_2) conv8_2 = Conv2D(256, (3, 3), strides=(1, 1), activation='relu', padding='valid', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv8_2')(conv8_1) conv9_1 = Conv2D(128, (1, 1), activation='relu', padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv9_1')(conv8_2) conv9_2 = Conv2D(256, (3, 3), strides=(1, 1), activation='relu', padding='valid', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv9_2')(conv9_1)
3. convolutional predictor layers
[code] # Feed conv4_3 into the L2 normalization layer conv4_3_norm = L2Normalization(gamma_init=20, name='conv4_3_norm')(conv4_3) ### Build the convolutional predictor layers on top of the base network # 为每个anchor box预测n_classes个类别,因此分类器的filter应该是n_boxes x n_classes # confidence 层的输出形状: `(batch, height, width, n_boxes * n_classes) conv4_3_norm_mbox_conf = Conv2D(n_boxes[0] * n_classes, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv4_3_norm_mbox_conf')(conv4_3_norm) fc7_mbox_conf = Conv2D(n_boxes[1] * n_classes, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='fc7_mbox_conf')(fc7) conv6_2_mbox_conf = Conv2D(n_boxes[2] * n_classes, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv6_2_mbox_conf')(conv6_2) conv7_2_mbox_conf = Conv2D(n_boxes[3] * n_classes, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv7_2_mbox_conf')(conv7_2) conv8_2_mbox_conf = Conv2D(n_boxes[4] * n_classes, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv8_2_mbox_conf')(conv8_2) conv9_2_mbox_conf = Conv2D(n_boxes[5] * n_classes, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv9_2_mbox_conf')(conv9_2) # 我们为每个框预测4个坐标,因此位置预测器的filter为' n_boxes * 4 ' # localization位置层的输出形状: `(batch, height, width, n_boxes * 4)` conv4_3_norm_mbox_loc = Conv2D(n_boxes[0] * 4, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv4_3_norm_mbox_loc')(conv4_3_norm) fc7_mbox_loc = Conv2D(n_boxes[1] * 4, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='fc7_mbox_loc')(fc7) conv6_2_mbox_loc = Conv2D(n_boxes[2] * 4, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv6_2_mbox_loc')(conv6_2) conv7_2_mbox_loc = Conv2D(n_boxes[3] * 4, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv7_2_mbox_loc')(conv7_2) conv8_2_mbox_loc = Conv2D(n_boxes[4] * 4, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv8_2_mbox_loc')(conv8_2) conv9_2_mbox_loc = Conv2D(n_boxes[5] * 4, (3, 3), padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(l2_reg), name='conv9_2_mbox_loc')(conv9_2)
4. AnchorBoxes层
[code] # Output shape of anchors: `(batch, height, width, n_boxes, 8)` #AnchorBoxes层为自定义层 conv4_3_norm_mbox_priorbox = AnchorBoxes(img_height, img_width, this_scale=scales[0], next_scale=scales[1], aspect_ratios=aspect_ratios[0], two_boxes_for_ar1=two_boxes_for_ar1, this_steps=steps[0], this_offsets=offsets[0], clip_boxes=clip_boxes, variances=variances, coords=coords, normalize_coords=normalize_coords, name='conv4_3_norm_mbox_priorbox')(conv4_3_norm_mbox_loc) fc7_mbox_priorbox = AnchorBoxes(img_height, img_width, this_scale=scales[1], next_scale=scales[2], aspect_ratios=aspect_ratios[1], two_boxes_for_ar1=two_boxes_for_ar1, this_steps=steps[1], this_offsets=offsets[1], clip_boxes=clip_boxes, variances=variances, coords=coords, normalize_coords=normalize_coords, name='fc7_mbox_priorbox')(fc7_mbox_loc) conv6_2_mbox_priorbox = AnchorBoxes(img_height, img_width, this_scale=scales[2], next_scale=scales[3], aspect_ratios=aspect_ratios[2], two_boxes_for_ar1=two_boxes_for_ar1, this_steps=steps[2], this_offsets=offsets[2], clip_boxes=clip_boxes, variances=variances, coords=coords, normalize_coords=normalize_coords, name='conv6_2_mbox_priorbox')(conv6_2_mbox_loc) conv7_2_mbox_priorbox = AnchorBoxes(img_height, img_width, this_scale=scales[3], next_scale=scales[4], aspect_ratios=aspect_ratios[3], two_boxes_for_ar1=two_boxes_for_ar1, this_steps=steps[3], this_offsets=offsets[3], clip_boxes=clip_boxes, variances=variances, coords=coords, normalize_coords=normalize_coords, name='conv7_2_mbox_priorbox')(conv7_2_mbox_loc) conv8_2_mbox_priorbox = AnchorBoxes(img_height, img_width, this_scale=scales[4], next_scale=scales[5], aspect_ratios=aspect_ratios[4], two_boxes_for_ar1=two_boxes_for_ar1, this_steps=steps[4], this_offsets=offsets[4], clip_boxes=clip_boxes, variances=variances, coords=coords, normalize_coords=normalize_coords, name='conv8_2_mbox_priorbox')(conv8_2_mbox_loc) conv9_2_mbox_priorbox = AnchorBoxes(img_height, img_width, this_scale=scales[5], next_scale=scales[6], aspect_ratios=aspect_ratios[5], two_boxes_for_ar1=two_boxes_for_ar1, this_steps=steps[5], this_offsets=offsets[5], clip_boxes=clip_boxes, variances=variances, coords=coords, normalize_coords=normalize_coords, name='conv9_2_mbox_priorbox')(conv9_2_mbox_loc)
5.reshape层
一方面为了后面各个层提取的特征能够concat起来,也是为了后面计算softmax,我们需要把类别单独提取出来作为单独的axis,以conv4_3为例:

[code] # Reshape the class predictions, yielding 3D tensors of shape `(batch, height * width * n_boxes, n_classes)` # We want the classes isolated in the last axis to perform softmax on them conv4_3_norm_mbox_conf_reshape = Reshape((-1, n_classes), name='conv4_3_norm_mbox_conf_reshape')(conv4_3_norm_mbox_conf) fc7_mbox_conf_reshape = Reshape((-1, n_classes), name='fc7_mbox_conf_reshape')(fc7_mbox_conf) conv6_2_mbox_conf_reshape = Reshape((-1, n_classes), name='conv6_2_mbox_conf_reshape')(conv6_2_mbox_conf) conv7_2_mbox_conf_reshape = Reshape((-1, n_classes), name='conv7_2_mbox_conf_reshape')(conv7_2_mbox_conf) conv8_2_mbox_conf_reshape = Reshape((-1, n_classes), name='conv8_2_mbox_conf_reshape')(conv8_2_mbox_conf) conv9_2_mbox_conf_reshape = Reshape((-1, n_classes), name='conv9_2_mbox_conf_reshape')(conv9_2_mbox_conf) # Reshape the box predictions, yielding 3D tensors of shape `(batch, height * width * n_boxes, 4)` # We want the four box coordinates isolated in the last axis to compute the smooth L1 loss conv4_3_norm_mbox_loc_reshape = Reshape((-1, 4), name='conv4_3_norm_mbox_loc_reshape')(conv4_3_norm_mbox_loc) fc7_mbox_loc_reshape = Reshape((-1, 4), name='fc7_mbox_loc_reshape')(fc7_mbox_loc) conv6_2_mbox_loc_reshape = Reshape((-1, 4), name='conv6_2_mbox_loc_reshape')(conv6_2_mbox_loc) conv7_2_mbox_loc_reshape = Reshape((-1, 4), name='conv7_2_mbox_loc_reshape')(conv7_2_mbox_loc) conv8_2_mbox_loc_reshape = Reshape((-1, 4), name='conv8_2_mbox_loc_reshape')(conv8_2_mbox_loc) conv9_2_mbox_loc_reshape = Reshape((-1, 4), name='conv9_2_mbox_loc_reshape')(conv9_2_mbox_loc) # Reshape the anchor box tensors, yielding 3D tensors of shape `(batch, height * width * n_boxes, 8)` conv4_3_norm_mbox_priorbox_reshape = Reshape((-1, 8), name='conv4_3_norm_mbox_priorbox_reshape')(conv4_3_norm_mbox_priorbox) fc7_mbox_priorbox_reshape = Reshape((-1, 8), name='fc7_mbox_priorbox_reshape')(fc7_mbox_priorbox) conv6_2_mbox_priorbox_reshape = Reshape((-1, 8), name='conv6_2_mbox_priorbox_reshape')(conv6_2_mbox_priorbox) conv7_2_mbox_priorbox_reshape = Reshape((-1, 8), name='conv7_2_mbox_priorbox_reshape')(conv7_2_mbox_priorbox) conv8_2_mbox_priorbox_reshape = Reshape((-1, 8), name='conv8_2_mbox_priorbox_reshape')(conv8_2_mbox_priorbox) conv9_2_mbox_priorbox_reshape = Reshape((-1, 8), name='conv9_2_mbox_priorbox_reshape')(conv9_2_mbox_priorbox)
6. concat层
[code] ### Concatenate the predictions from the different layers # 因为axis 0 与 axis 2对于每个预测层都是一样的,因此我们可以沿着axis 1进行拼接起来 # Output shape of `mbox_conf`: (batch, n_boxes_total, n_classes) mbox_conf = Concatenate(axis=1, name='mbox_conf')([conv4_3_norm_mbox_conf_reshape, fc7_mbox_conf_reshape, conv6_2_mbox_conf_reshape, conv7_2_mbox_conf_reshape, conv8_2_mbox_conf_reshape, conv9_2_mbox_conf_reshape]) # Output shape of `mbox_loc`: (batch, n_boxes_total, 4) mbox_loc = Concatenate(axis=1, name='mbox_loc')([conv4_3_norm_mbox_loc_reshape, fc7_mbox_loc_reshape, conv6_2_mbox_loc_reshape, conv7_2_mbox_loc_reshape, conv8_2_mbox_loc_reshape, conv9_2_mbox_loc_reshape]) # Output shape of `mbox_priorbox`: (batch, n_boxes_total, 8) mbox_priorbox = Concatenate(axis=1, name='mbox_priorbox')([conv4_3_norm_mbox_priorbox_reshape, fc7_mbox_priorbox_reshape, conv6_2_mbox_priorbox_reshape, conv7_2_mbox_priorbox_reshape, conv8_2_mbox_priorbox_reshape, conv9_2_mbox_priorbox_reshape])
7. softmax层
框坐标的预测mbox_loc将会直接进入损失函数,但对于类预测,我们将首先应用softmax激活层
[code] mbox_conf_softmax = Activation('softmax', name='mbox_conf_softmax')(mbox_conf)
8. 预测结果合并
[code] # 将类和框预测以及锚连接到一个大型预测向量 # Output shape of `predictions`: (batch, n_boxes_total, n_classes + 4 + 8) predictions = Concatenate(axis=2, name='predictions')([mbox_conf_softmax, mbox_loc, mbox_priorbox])
9. 模型的输出
如果是训练模型,预测结果会进入损失函数,计算误差,然后更新模型参数
[code]model = Model(inputs=x, outputs=predictions)
如果是预测模式的话,预测结果就会被解码。通过调整confidence_thresh,NMS或者iou_thresh, top_k的参数的选择,最后从8732个预测框中选择我们想要的框,作为最后的输出。
[code] decoded_predictions = DecodeDetectionsFast(confidence_thresh=confidence_thresh, iou_threshold=iou_threshold, top_k=top_k, nms_max_output_size=nms_max_output_size, coords=coords, normalize_coords=normalize_coords, img_height=img_height, img_width=img_width, name='decoded_predictions')(predictions) model = Model(inputs=x, outputs=decoded_predictions)
完整代码:地址
刚开始啃这一块,如果我的理解有问题,还要辛苦大家指出来。%>_<%
阅读更多
- 目标检测算法SSD源码解读~~~~~~~~~~ssd_pascal.py
- 【目标检测】SSD算法--损失函数的详解(tensorflow实现)
- 深度学习目标检测模型全面综述:Faster R-CNN、R-FCN和SSD
- 卷二 Dalvik与Android源码分析 第五章 Interpreter与JIT 5.1 解释器编译结构、5.2dalvik寄存器编译模型 图书版试读--请勿转发
- 深度学习目标检测模型全面综述:Faster R-CNN、R-FCN和SSD
- 数据结构与算法学习(一)顺序存储结构ArrayList源码分析
- OpenCV学习笔记(29)KAZE 算法原理与源码分析(三)特征检测与描述
- opencv3.3中基于ssd算法的目标检测示例教程
- 目标检测:SSD算法的Default Box
- SSD目标检测算法改进:DSOD(不需要预训练的目标检测算法)
- 基于深度学习的目标检测算法:SSD
- Python与机器学习之模型结构(生成学习算法)
- 数据结构与算法学习(二)链式存储结构LinkedList源码分析
- 机器学习经典算法详解及Python实现--CART分类决策树、回归树和模型树
- SSD目标检测算法中default box在ssd_pascal.py的设置
- Python数据结构与算法之二叉树结构定义与遍历方法详解
- 数据结构与算法之LinkedList源码分析
- C++卷积神经网络实例:tiny_cnn代码详解(11)——层结构容器layers类源码分析
- 运动目标检测 之 GMM背景模型算法
- 机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用