Beats:使用Filebeat传送多行日志
在解决应用程序问题时,多行日志为开发人员提供了宝贵的信息。 堆栈跟踪就是一个例子。 堆栈跟踪是引发异常时应用程序处于中间的一系列方法调用。 堆栈跟踪包括遇到错误的相关行以及错误本身。 可以在此处查看Java堆栈跟踪的示例:
[code]Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book.java:16) at com.example.myproject.Author.getBookTitles(Author.java:25) at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
当使用类似Elastic Stack的日志记录工具时,如果没有正确的配置,可能很难识别和搜索堆栈跟踪。 使用像Filebeat这样的开源轻型日志摄入器发送应用程序日志时,堆栈跟踪的每一行在Kibana中都将被视为单个文档。
因此,上面的堆栈跟踪将在Kibana中视为四个单独的文档。 这使得在堆栈跟踪中搜索和理解错误和异常变得很困难,因为它们与它们的上下文脱离了共同的事件。 使用Filebeat记录应用程序日志时,用户可以通过在filebeat.yml文件中添加配置选项来避免此问题。
你可以配置filebeat.yml输入部分 filebeat.inputs 以添加一些多行配置选项,以确保将多行日志(如堆栈跟踪)作为一个完整文档发送。 将以下配置选项添加到filebeat.yml输入部分,将确保上面引用的Java堆栈跟踪将作为单个文档发送。
[code]multiline.pattern: '^[[:space:]]' multiline.negate: false multiline.match: after
根据 Elastic 的官方文档介绍:
multiline.pattern
指定要匹配的正则表达式模式。 请注意,Filebeat支持的正则表达式模式与Logstash支持的模式有些不同。 有关受支持的正则表达式模式的列表,请参见正则表达式支持。 根据你配置其他多行选项的方式,与指定正则表达式匹配的行将被视为上一行的延续或新多行事件的开始。 你可以设置negate
选项以否定模式。
multiline.negate
定义是否为否定模式,也就是和上面定义的模式相反。 默认为false。
multiline.match
指定Filebeat如何将匹配的行组合到事件中。 设置在之后 (after) 或之前 (before)。 这些设置的行为取决于你为否定指定的内容:
| negate | match | 结果 |
pattern: ^b 匹配以b开头的行 |
|---|---|---|---|
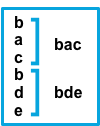
| false | after | 与模式匹配的连续行将追加到不匹配的前一行。在右边以 a 为开头的行是和 pattern 不相匹配的,那么它后面匹配以 b 为开头的行将被追加到前面的以 a 为开头的行,所以第一个是 abb,第二个是 cbb |
|
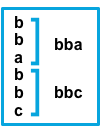
| false | before | 匹配模式的连续行将被添加到不匹配的下一行。在右边以 b 为开头的行都是符号pattern的,而以 a 为开头的行是不匹配的,那么在以 a 为截止之前的所有的行将被连起来形成一个整体,也就是 bba。第二次就是 bbc。 |
|
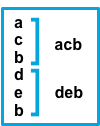
| true | after | 不匹配模式的连续行将追加到匹配的前一行。在右边,a,c 行都不是以 b 为开头的行,不符合 pattern。它们被追加到前面匹配的以 b 为开头的行。 |
|
| true | before | 与模式不匹配的连续行将被添加到下一个匹配的行之前。 |
|

我们还是以上面的log例子为例。我们来创建一个叫做 mulitline.log 的文件:
mulitline.log
[code]Exception in thread "main" java.lang.NullPointerException at com.example.myproject.Book.getTitle(Book.java:16) at com.example.myproject.Author.getBookTitles(Author.java:25) at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
我们创建一个 filebeat 的配置文件:
mulitiline.yml
[code]filebeat.inputs: - type: log enabled: true paths: - /Users/liuxg/data/multiline/multiline.log multiline.pattern: '^[[:space:]]' multiline.negate: false multiline.match: after output.elasticsearch: hosts: ["localhost:9200"] index: "multiline" setup.ilm.enabled: false setup.template.name: multiline setup.template.pattern: multiline
运行 filebeat,我们看一下被导入的文档的内容:
[code]GET multiline/_search
[code]{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "multiline",
"_type" : "_doc",
"_id" : "9FI7OnIBmMpX8h3C4Cx8",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2020-05-22T02:34:55.533Z",
"ecs" : {
"version" : "1.5.0"
},
"host" : {
"name" : "liuxg"
},
"agent" : {
"ephemeral_id" : "53a2f64e-c587-4f82-90bc-870274227c54",
"hostname" : "liuxg",
"id" : "be15712c-94be-41f4-9974-0b049dc95750",
"version" : "7.7.0",
"type" : "filebeat"
},
"log" : {
"offset" : 0,
"file" : {
"path" : "/Users/liuxg/data/multiline/multiline.log"
},
"flags" : [
"multiline"
]
},
"message" : """Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)""",
"input" : {
"type" : "log"
}
}
}
]
}
}
从上面,我们可以看到在 message 字段,它含有 stack trace 的总三行信息。
另外一个例子是在 Elastic 的官方文档中:
[code]multiline.pattern: '^\[' multiline.negate: true multiline.match: after
上面将匹配所有以 [ 为开头的行,并且后面非以 [ 为开头的行将被追加到匹配的那一行。那么它很好地匹配了像如下的日志:
[code][beat-logstash-some-name-832-2015.11.28] IndexNotFoundException[no such index] at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver$WildcardExpressionResolver.resolve(IndexNameExpressionResolver.java:566) at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:133) at org.elasticsearch.cluster.metadata.IndexNameExpressionResolver.concreteIndices(IndexNameExpressionResolver.java:77) at org.elasticsearch.action.admin.indices.delete.TransportDeleteIndexAction.checkBlock(TransportDeleteIndexAction.java:75)
针对如下的信息:
[code]Exception in thread "main" java.lang.IllegalStateException: A book has a null property at com.example.myproject.Author.getBookIds(Author.java:38) at com.example.myproject.Bootstrap.main(Bootstrap.java:14) Caused by: java.lang.NullPointerException at com.example.myproject.Book.getId(Book.java:22) at com.example.myproject.Author.getBookIds(Author.java:35) ... 1 more
我们可以采用如下的配置:
[code]multiline.pattern: '^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:'
multiline.negate: false
multiline.match: after
在上面的例子中,它的 pattern 匹配了如下的情况:
- 这一行开始以一个 SPACE 为开头,并接着一个词 at
- 这一行以一个短语 Caused by 为开始的
更多参考,请参阅官方文档 https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
除了上面提到的多行配置选项外,您还可以设置选项来刷新多行消息的内存,设置单个事件中可以包含的最大行数 multiline.max_lines
,并且可以将超时时间设置为5秒(默认值)multiline.timeout
。在指定的超时后,即使未找到新的模式来启动新事件,Filebeat也会发送多行事件。
让我们看一下使用multiline.flush_pattern的示例。 Filebeat的此配置选项对于包含事件以特定标记开始和结束的多行应用程序日志很有用。
[code][2015-08-24 11:49:14,389] Start new event [2015-08-24 11:49:14,395] Content of processing something [2015-08-24 11:49:14,399] End event
如果我们希望这些行在Kibana中显示为单个文档,我们将在filebeat.yml中使用以下多行配置选项:
[code]multiline.pattern: ‘Start new event’ multiline.negate: true multiline.match: after multiline.flush_pattern: ‘End event’
从上面的配置选项中,当看到“Start new event”模式并且以下几行与该模式不匹配时,它们将被追加到与该模式匹配的前一行。 当看到以“End event”开头的一行时,flush_pattern选项将指示多行事件结束。
结论
将应用程序日志集中到一个位置是重要的第一步,可以帮助解决应用程序出现的任何问题。 确保在该工具中正确提取并显示了日志,可以帮助公司减少平均解决时间。
参考:
【1】https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html

- Beats:如何使用Filebeat将MySQL日志发送到Elasticsearch
- Beats: 使用 Filebeat 进行日志结构化
- 使用filebeat替代logstash进行日志采集
- Kubernetes部署ELK并使用Filebeat收集容器日志
- 使用Filebeat 6 收集多个目录的日志并发送到lostash
- 使用elasticsearch和filebeat做日志收集
- ELK日志系统:Filebeat使用及Kibana如何设置登录认证
- filebeat合并多行日志示例
- 从零进阶--教你如何使用Filebeat实现日志可视化收集
- Elastic技术栈Beats日志收集工具filebeat的安装
- ELK实战之使用filebeat代替logstash收集日志
- 使用Filebeat和Logstash集中归档游戏日志
- filebeat 多行日志的处理
- Beats数据采集---Packetbeat\Filebeat\Topbeat\WinlogBeat使用指南
- elk的安装部署三(kibana的安装及使用filebeat收集日志)
- 使用filebeat收集kubernetes容器日志
- K8S使用filebeat统一收集应用日志
- ELK6.3.1版本使用filebeat收集nginx的日志配置文件
- ELK之-redis(错误,警告)日志使用filebeat收集
- K8S使用filebeat统一收集应用日志