使用elasticsearch和filebeat做日志收集
在存储数据之前,elasticsearch可以使用Ingest Node对数据做预处理。
https://www.elastic.co/guide/en/beats/filebeat/current/configuring-ingest-node.html
1 使用ingest功能
1.1 定义一个pipeline
例如grib2-pipeline.json
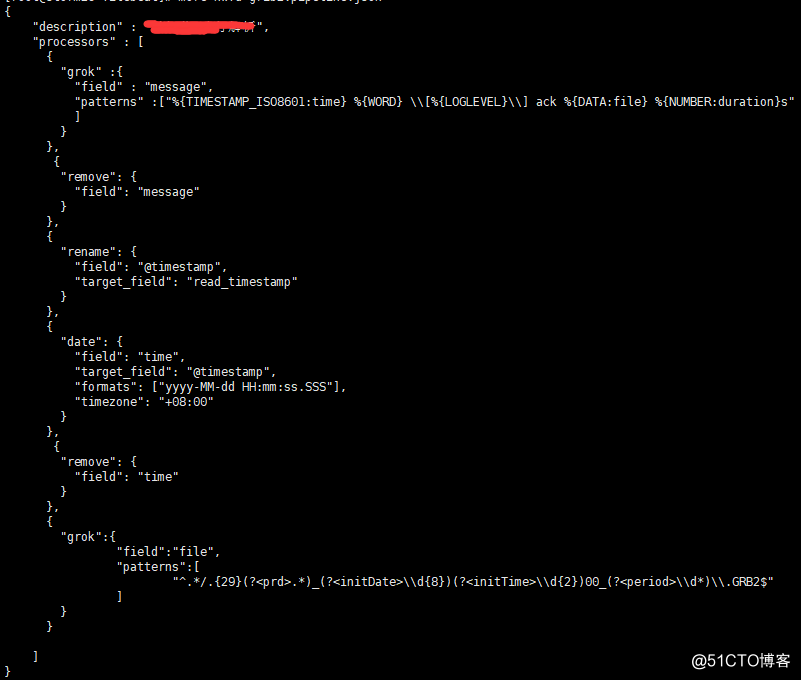
grok可以使用预定义Patterns(%{Pattern:name}匹配提取字段),也可以直接使用正则表达式(分组命名提取字段)
1.2 将pipeline添加到elasticsearch中
curl -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_ingest/pipeline/grib2' -d@grib2-pipeline.json
1.3 如何使用ingest功能
https://www.elastic.co/guide/en/elasticsearch/reference/6.4/ingest.html
PUT my-index/_doc/my-id?pipeline=my_pipeline_id
{
"foo": "bar"
}
2 配置filebeat
2.1 新建 ack.yml文件
filebeat.inputs:
- type: log
paths:
- /opt/deploy/storm/logs/workers-artifacts/grib2*/*/worker.log
include_lines: ['ack ']
output.elasticsearch:
hosts: ["127.0.0.1:9200"]
pipeline: grib2
index: "grib2-%{+yyyy.MM.dd}"
setup.template.name: "grib2"
setup.template.pattern: "grib2-*"
通过setup.template.name|pattern 和 output.elasticsearch.index配置索引的名称,便于将来的使用。
2.2 启动filebeat
nohup ./filebeat -c ack.yml &
-c 指定配置文件;nohup & 后台运行;
3 检索日志

- Kubernetes部署ELK并使用Filebeat收集容器日志
- 使用filebeat收集kubernetes容器日志
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
- 使用Filebeat 6 收集多个目录的日志并发送到lostash
- elk的安装部署三(kibana的安装及使用filebeat收集日志)
- ELK实战之使用filebeat代替logstash收集日志
- 使用 Filebeat 收集日志
- filebeat -> logstash -> elasticsearch -> kibana ELK 日志收集搭建
- logstash与filebeat收集日志
- logstash与filebeat收集日志
- 使用filebeat进行数据加密传输和区别不同的日志源
- filebeat+logstash+elasticsearch收集haproxy日志
- ELK 5.0.1+Filebeat5.0.1实时监控MongoDB日志并使用正则解析mongodb日志
- logstash与filebeat收集日志
- logstash与filebeat收集日志
- kubernetes POD 日志存储方式详解 以及使用filebeat处理日志
- filebeat-6.2.3收集日志到kafka配置
- filebeat 获取nginx日志 发送给ElasticSearch
- logstash与filebeat收集日志
- logstash与filebeat收集日志