新鲜开源:基于Prometheus的企业监控平台设计与实现 - 运维
-
报警规则:与Prometheus中的报警规则概念相同。
-
数据源:Prometheus Server的URL,由Rule Engine将报警规则下发至该URL进行计算。
-
报警接收组:由多个报警接收人组成的组。
-
值班组:和报警接收组类似,但是它是动态的从接口中获取组成员的列表。
-
报警延迟:报警触发一段时间后才将报警发送给接收人。
-
报警周期:报警发送的周期。
-
报警计划:由多条报警策略组成的集合。
-
报警方式:对于内部用户,可以通过蓝信、短信和电话的方式进行报警。非内部用户可以采用HOOK的方式将报警转发到自定义的Web Server进行处理。
-
报警策略:一条报警策略包含报警延迟、报警周期、报警时间段、报警接收组、值班组以及报警方式等配置信息。
-
报警确认:如果需要短时间的暂停报警,可以通过勾选相应报警并填写暂停时长来确认报警。
-
维护组:如果希望屏蔽一些固定时间段内某些特定机器的报警,可以通过配置报警维护组策略来实现。
1、创建报警计划
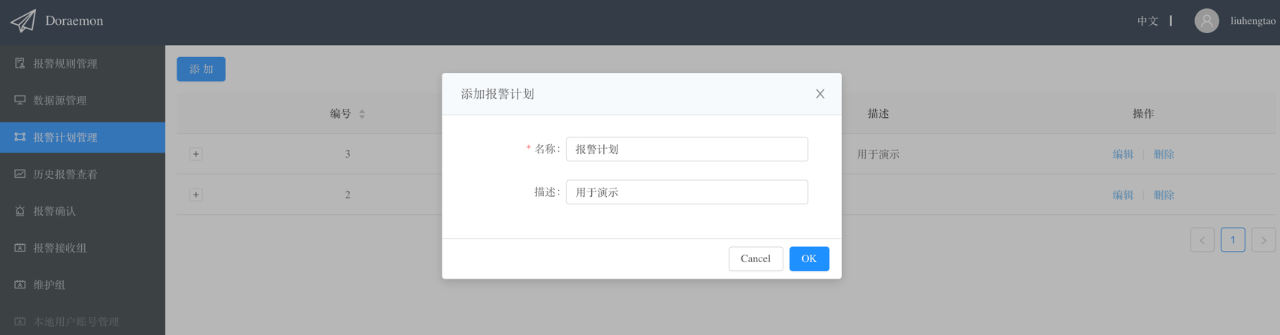
我们先创建一个计划,这个计划只需要填写一个名称和描述,然后在这个计划下添加具体的报警策略。
一个报警计划下面可以添加多个报警策略,通过这种方式既可以实现报警的定向发送也可以实现报警的升级。例如下图的报警计划实现了将含有标签idc=beijing的报警发给op1,将含有标签idc!=beijing的报警发送给op2,并且将所有超过60分钟还没有被确认的报警以电话形式通知leader。

以下是对上图术语的具体解释:
-
报警时间段:每天发送报警的时段。
-
报警延迟:报警触发多长时间后才开始发送报警,可用于实现报警升级。
-
报警周期:每隔多少分钟发送一次报警。
-
报警用户:报警接收人,可以输入多个报警接收人。
-
值班组:从接口动态获取报警值班人。
-
报警用户组:可以创建报警用户组,一个报警用户组包含多个报警接收人。
-
Filter表达式:通过label来过滤要发送的报警。支持“=”,“!=”,“&”,“|”,“(”,“)”这几种运算符号,并且在保存Filter表达式之前会自动校验表达式的合法性,对于不合法的表达式会给出提示。例如只发送来自北京或上海机房并且名称是搜索的报警,对应的Filter表达式就是“name=sousuo&(idc=beijing|idc=shanghai)”。
-
报警方式:支持HOOK方式将报警以HTTP POST请求的形式发送至指定报警网关。
在创建完报警计划后,需要创建Prometheus的数据源,这个比较简单,只需要填写一个Prometheus的名称,还有把Prometheus暴露的Query API的url填写上就可以了。有了报警计划和数据源之后,就可以创建一个报警规则,然后将报警规则关联到数据源,这样Rule Engine就会把这个规则下发到指定的Prometheus上进行计算。计算的结果会由Web后端定时扫描,根据我们刚才创建的报警计划来发送给指定的人。
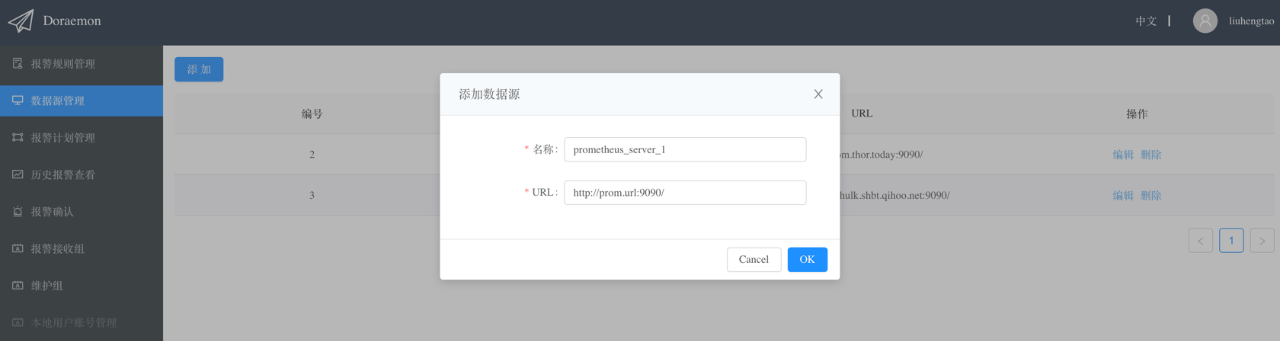
2、添加报警规则
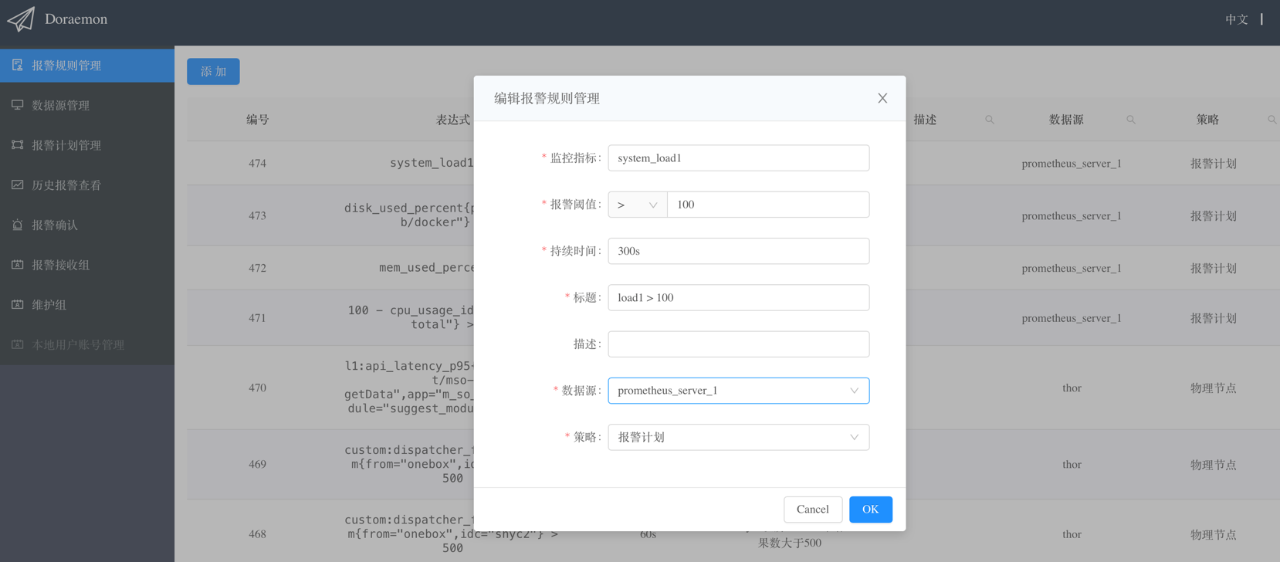
以下是添加报警规则需要填写的一些参数的解释,其实跟Prometheus官方文档上提到的是一致的 :
-
监控指标:对应Prometheus的alerting rules中的“expr”。
-
报警阈值:expr的阈值。
-
持续时间:对应Prometheus的alerting rules中的“for”。
-
标题:对应Prometheus的alerting rules中的“summary”。
-
描述:对应Prometheus的alerting rules中的“description”。
-
数据源:关联到前面创建的Prometheus Server的信息,即将这条监控规则下发到该Prometheus进行计算。
-
策略:关联到前面创建的报警计划。
3、报警聚合
哆啦A梦所发送出来的报警都是从报警规则的维度进行聚合的,例如某个报警规则所关联的报警计划下面有两个报警策略,一条策略的报警周期是5分钟,则该条规则下的所有报警会每5分钟聚合一次并发送,另一条策略的报警周期是10分钟,则相应的报警会每10分钟聚合一次并发送。对于报警恢复的恢复信息会每分钟聚合一次并发送。对于同一条报警,根据报警策略的不同会以不同的报警延时,不同的报警周期聚合后发送给不同的接收者。
例如这样的报警策略:报警持续5分钟后开始发出第一条报警,每5分钟发一次。假设在第0、1、2、3、4分钟的每一分钟都有2台不同的机器触发了rule A的报警,如果不聚合则在5-9分钟每分钟都会发出一个报警,每条报警包含两台机器的信息。这样当出现多条rule下的多台机器一起报警的时候,会出现在短时间内多条rule的报警交替出现,这样对运维人员不友好,不好辨别这一分钟里到底是哪几条rule触发的报警。
而聚合后,将在第5分钟将第0分钟触发的报警发出,第10分钟将第0、1、2、3、4分钟的报警聚合发出,即每五分钟聚合一次rule A的报警。如果某个报警在第1分钟到第9分钟内触发,并且在这期间又恢复了,则用户不会收到报警信息以及报警恢复信息。对于同一条报警,由于报警策略不同,会导致有的用户可能收到过该条报警,而有的用户没有,系统会保证该条报警的恢复信息只会发送给已经收到过该报警的用户。对于没有发出的报警可以在报警历史记录中查看。
4、报警确认
有两种方式进行报警确认,一种是点击报警信息中的确认链接,这种方式是从报警规则的维度进行报警确认的(因为报警是以报警规则的维度聚合发送的)。例如,在报警策略中配置了报警延时为5分钟,只接收idc=zzzc和idc=shbt的报警,则点开报警确认链接只能看到以及确认满足该报警策略的报警。也就是说,不同的报警策略所展示的报警确认页面的内容也是不同的:

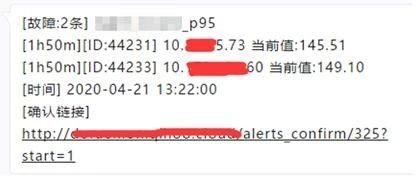
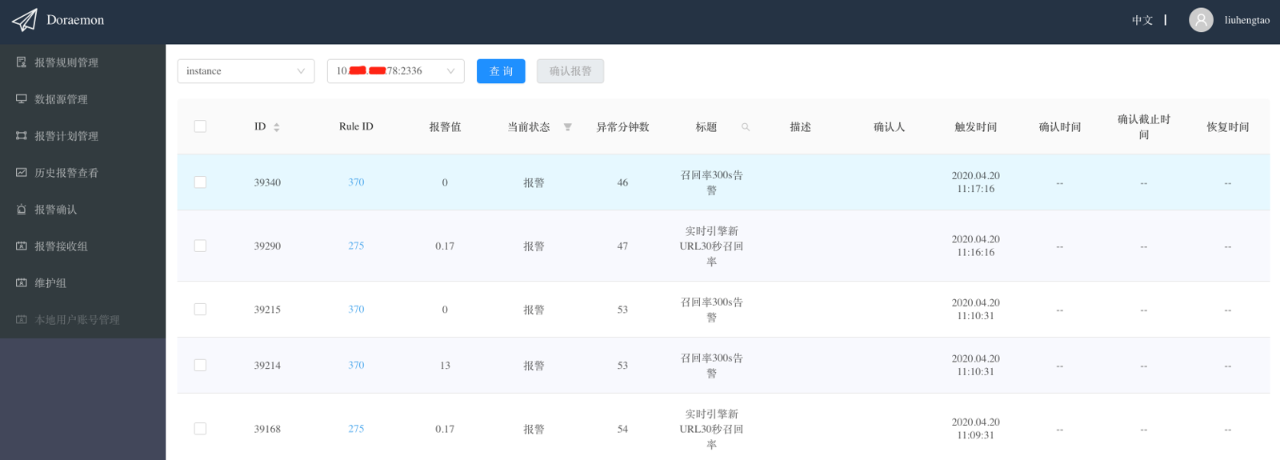
另一种报警确认方式是从label的维度进行报警确认,比如IP为10.0.0.1的机器宕机了,触发了多条报警规则的报警,此时从报警规则的维度进行报警确认效率很低,但如果从label的维度进行报警确认就会非常方便,因为含有“instance=10.0.0.1:9090”的报警都是该机器产生的报警我们可以一次性的确认。下图是从label的维度进行报警确认:
5、维护组
有些时候可能会有大批量的机器处于维护状态,或者某些机器在一段时间内出现故障,需要屏蔽来自这些机器的报警,此时就可以将这些机器的instance标签的值(不含端口号)作为机器的唯一识别信息加入维护组。
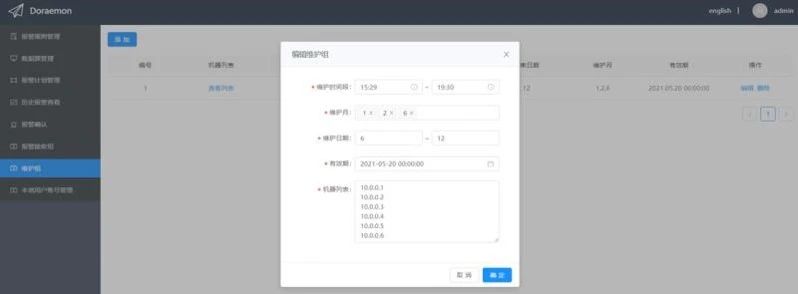
这里我们看一下维护组都需要填写哪些信息:
-
维护时间段:屏蔽报警的时间段。
-
维护月:屏蔽报警的月份。
-
维护日期:在维护月份的哪些天对报警进行屏蔽。
-
有效期:维护规则的有效期(过了该时间维护规则自动失效)。
-
机器列表:instance标签的值(去掉端口号),通常为机器IP。
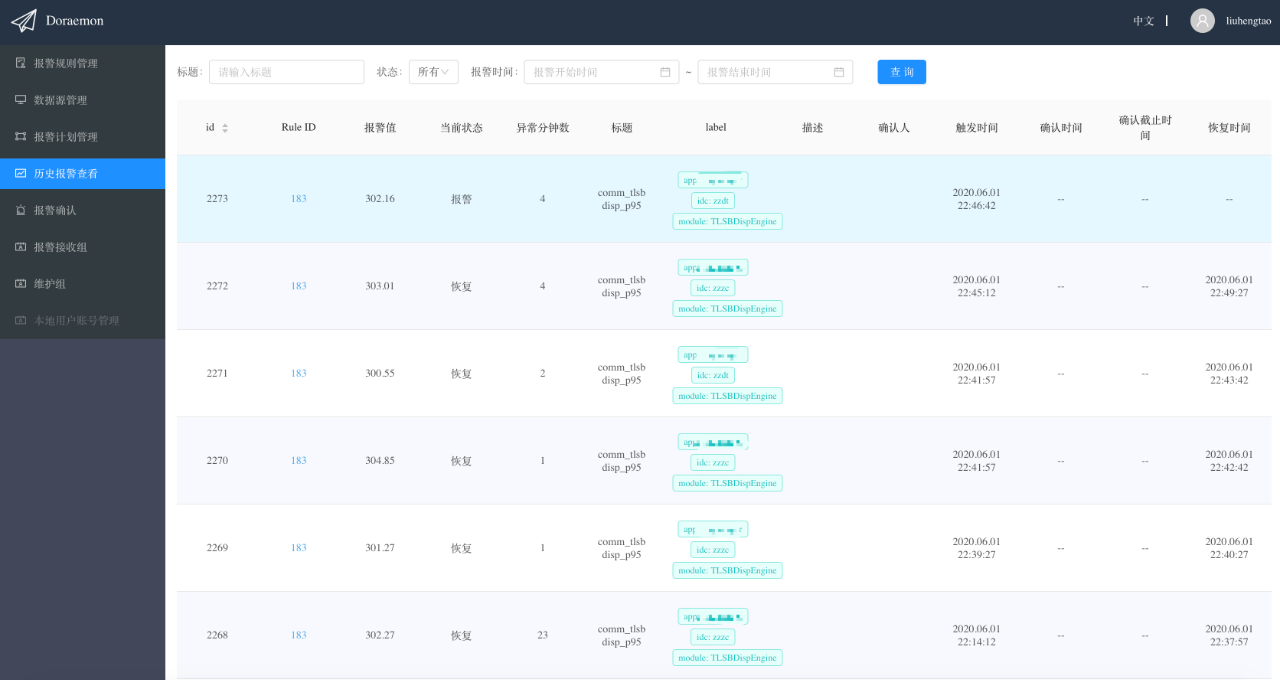
6、历史报警
在“历史报警查看”页面可以看到所有的历史报警信息,包括那些没有被发送只是抖动了一下(没有到报警聚合点就已经自动恢复的报警)的报警,这里也会把它展示出来。
四、哆啦A梦的快速部署
哆啦A梦提供了两种部署方式,一种是基于docker-compose本地部署,由于没有提供额外的高可用机制,因此这种方式仅用于本地测试;另一种方式是基于Kubernetes集群部署,用于生产环境。两种部署方式都非常简单。
1、docker-compose部署
1)从GitHub下载代码。
2)将deployments/docker-compose/conf/config.js中的“localhost”替换为本机物理网卡IP或域名,端口号保持不变。
3)进入deployments/docker-compose/目录下执行docker-compose up -d即可,然后就可以通过http://本机ip:32000访问Doraemon。
2、基于Kubernetes部署
1)从GitHub下载代码。
2)修改deployments/kubernetes/doraemon.yml,配置好MySQL数据库信息,并将“doraemon-ui”这个configmap中的“baseURL”的“nodeip”替换为Kubernetes集群中任意结点的结点IP。
3)执行kubectl apply -f deployments/kubernetes/doraemon.yml,之后通过http://nodeip:32000来访问Doraemon。
五、报警恢复聚合方案
1、报警聚合
我们的报警聚合是希望能尽量利用数据库中已有的信息来实现目标,其中需要注意的地方有:
-
一条报警可能有多个接收者,而每个接收者的报警延迟以及报警周期都是不同的。
-
每分钟发送报警的线程和接收来自计算引擎的报警恢复信息是异步的。
2、报警发送聚合方案
由于目标是按照rule来聚合报警,因此我们需要一个rule级别的计数器,又因为一条rule可以有多个报警规则,并且它们的报警延迟和报警周期各不相同,因此针对每一个rule和每一个报警规则创建一个计数器rulecount,并将它保存在一个map中,即map[[2]int{ruleid,start}]=rulecount,其中start表示报警规则的报警延迟。于是报警聚合发送流程如下:

3、rulecount具体实现与优化
为了更快的获取到rulecount的值,选择map来存储。然而随着rule的数量增加以及报警规则的增加,map占用的内存将会越来越多(golang中即便通过delete删除map中的元素也不会真正释放内存,仅仅是将原来的位置设为empty),可以采用如下方式来优化:

4、报警恢复聚合方案
报警聚合还触及到报警恢复的问题,相当于说当我有一条报警恢复了,这个报警恢复到底该发送给哪些人。针对这个点,我们借助了之前说到的两个计数器,一个是count,一个是rulecount。通过这两个计数器的关系,来计算出某个报警恢复是否需要发送给某个指定的用户。

主要分成三种情况:
-
当count-start>=period时,报警信息肯定已经发出,因此需要发送这条报警恢复信息。
-
当0<=count-start=period。时,由上图可知,当n∙period∈[rulecount-(count-start),rulecount]时报警信息已经发出,因此需要发送该报警恢复信息,即(rulecount-(count-start))%period=0或者rulecount-((rulecount-(count-start))>
-
当count-start<0时,没有发出报警。
整体结合在一起,我们综合得到了这么一个报警聚合的发送方案,以及一个报警聚合恢复信息的发送方案。

5、特殊情况下的最坏影响
如果在报警过程中动态的修改报警规则的报警延迟和报警周期会有什么样的影响?
-
报警发生:影响下一次报警的报警时间,之后恢复正常。
-
报警恢复:对已经处于报警状态的报警可能会丢失报警恢复,对于修改之后触发的新的报警没有影响。
六、标签匹配筛选
新监控平台最初有一个计划是通过标签匹配表达式来实时筛选符合条件的报警,将指定标签的报警发给指定的人。例如筛选满足如下条件的报警:
host!=H1 & (idc=SHYC | idc=ZZZC) | port=80
目标:
-
能够校验表达式的正确性,如果表达式不正确,能够返回错误原因。
-
表达式的计算时间复杂度尽可能低。
方案:当用户在前端录入表达式后,由后端进行有效性验证,如果验证通过就存入数据库,否则将错误原因返回前端。
我们借用了逆波兰表达式的概念,又叫做后缀表达式。逆波兰表示法是波兰逻辑学家J・卢卡西维兹(J・Lukasewicz)在1929年首先提出的一种表达式的表示方法,它是一种没有括号,并严格遵循“从左到右”运算的后缀式表达方法。
举例:

我们的标签匹配算法具体流程如下:
1)当用户在前端输入表达式后,由后端将表达式转换为逆波兰表达式,在转换表达式的过程中同时验证表达式的正确性,如果能成功将表达式转换说明原表达式是有效的表达式,并将转换后的逆波兰表达式存在数据库中,否则返回转换错误原因。
2)监控平台从数据库中取出表达式并计算。
以下举一个更为具体的例子:
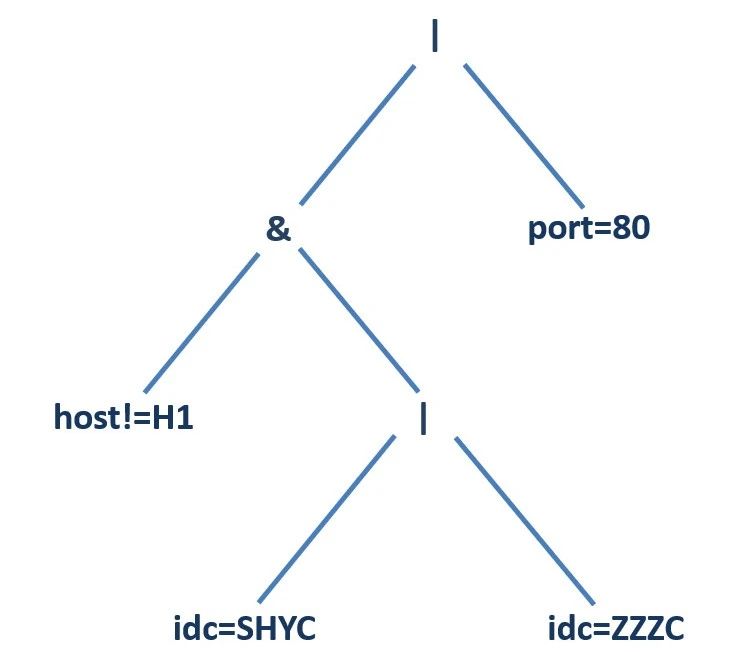
令“&”表示“与”,“|”表示“或”,“=”表示“等于”,“!=”表示“不等于”,以host!=H1 & (idc=SHYC | idc=ZZZC) | port=80为例,由于“与”“或”运算都是二元运算符,可以考虑将其解析为一棵二叉树,然后对其进行后序遍历可以得到逆波兰表达式:
host!=H1 idc=SHYC idc=ZZZC | & port=80 |
该算法的时间复杂度为O(n ∙ log(n)),在增加空间复杂度的情况下时间复杂度可以优化至O(n)。
以上就是我们标签表达式的一个实现方式。

- 嵌入式软件开发之程序架构设计-任务调度
- 民生银行日接入量15T的ELK日志平台(Apollo+ES源码改造) - 运维
- 超详细干货!Docker+PXC+Haproxy搭建高可用强一致性的MySQL集群
- 邱盛昌:OPPO商业化数据体系建设实战
- [pwn基础]Linux内核装载ELF过程简介
- 嵌入式软件架构设计-程序分层
- 嵌入式软件架构设计-模块化
- 一篇吃透监控系统:常用组合方案和主流工具选型 - 运维
- Docker-Compose实现Mysql主从
- 在nginx中使用proxy protocol协议
- Nginx-虚拟主机配置
- Web的缓存加速(Squid的安装与配置)
- 阿里大牛是怎么变Bug为宝的? - 架构
- 【Azure 应用服务】App Service For Linux 环境中,如何修改 Nginx 配置中 server_name的默认值 example.com
- 分布式架构下的通信(一)
- 深度学习与CV教程(9) | 典型CNN架构 (Alexnet,VGG,Googlenet,Resnet等)
- DevOps落地成不成,关键不在持续集成? - 运维
- 使用 source 命令将函数和变量导入 Bash
- 【Azure 应用服务】App Service for Windows 环境中为Tomcat自定义4xx/5xx页面
- Nginx使用Logrotate工具实现日志切割