flume 架构设计优化
2018-01-31 00:13
176 查看
对于企业中常用的flume type 概括如下:
ource(获取数据源):
exec (文件)
spoolingdir (文件夹)
taildir(文件夹及文件的变动)
kafka
syslog
http
channel(管道):
mem
file
kafka
sink(将channel中的 数据发送到目标地址):
hdfs
hive
hbase
ES
从集群可用性,可靠性,可扩展性和兼容性等方面,对架构优化进行设计。
1、可用性(availablity)
可用性(availablity)指固定周期内系统无故障运行总时间。要想提高系统的可用性,就需要消除系统的单点,提高系统的冗余度。
1.1 Agent死掉
机器死机
Agent进程死掉
所有的Agent在supervise的方式下启动,如果进程死掉会被系统立即重启,以提供服务。
所有的Agent进行存活监控,发现Agent死掉立即报警。
对于非常重要的日志,建议应用直接将日志写磁盘,Agent使用spooldir的方式获得最新的日志。
1.2 负载均衡与故障转移
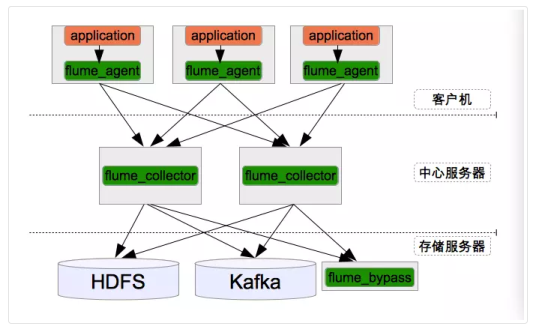
模块分解详解图
1.3 Hdfs正常停机
在Collector的HdfsSink中提供了开关选项,可以控制Collector停止写Hdfs,并且将所有的events缓存到FileChannel的功能。
1.4 Hdfs异常停机或不可访问
假如Hdfs异常停机或不可访问,此时Collector无法写Hdfs。由于我们使用DualChannel,Collector可以将所收到的events缓存到FileChannel,保存在磁盘上,继续提供服务。当Hdfs恢复服务以后,再将FileChannel中缓存的events再发送到Hdfs上。这种机制类似于Scribe,可以提供较好的容错性
1.5 Collector变慢或者Agent/Collector网络变慢
如果Collector处理速度变慢(比如机器load过高)或者Agent/Collector之间的网络变慢,可能导致Agent发送到Collector的速度变慢。同样的,对于此种情况,我们在Agent端使用DualChannel,Agent可以将收到的events缓存到FileChannel,保存在磁盘上,继续提供服务。当Collector恢复服务以后,再将FileChannel中缓存的events再发送给Collector。
1.6 Hdfs变慢
当Hadoop上的任务较多且有大量的读写操作时,Hdfs的读写数据往往变的很慢。由于每天,每周都有高峰使用期,所以这种情况非常普遍。对于Hdfs变慢的问题,我们同样使用DualChannel来解决。当Hdfs写入较快时,所有的events只经过MemChannel传递数据,减少磁盘IO,获得较高性能。当Hdfs写入较慢时,所有的events只经过FileChannel传递数据,有一个较大的数据缓存空间。
2、可靠性(reliability)
可靠性(reliability)是指Flume在数据流的传输过程中,保证events的可靠传递。
对Flume来说,所有的events都被保存在Agent的Channel中,然后被发送到数据流中的下一个Agent或者最终的存储服务中。那么一个Agent的Channel中的events什么时候被删除呢?当且仅当它们被保存到下一个Agent的Channel中或者被保存到最终的存储服务中。这就是Flume提供数据流中点到点的可靠性保证的最基本的单跳消息传递语义。
那么Flume是如何做到上述最基本的消息传递语义呢?
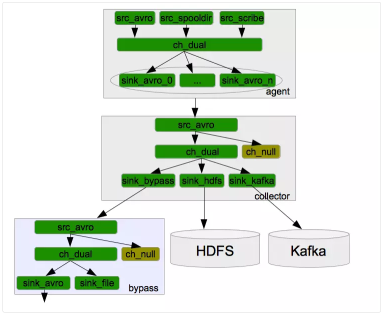
首先,Agent间的事务交换。Flume使用事务的办法来保证event的可靠传递。Source和Sink分别被封装在事务中,这些事务由保存event的存储提供或者由Channel提供。这就保证了event在数据流的点对点传输中是可靠的。在多级数据流中,如下图,上一级的Sink和下一级的Source都被包含在事务中,保证数据可靠地从一个Channel到另一个Channel转移。
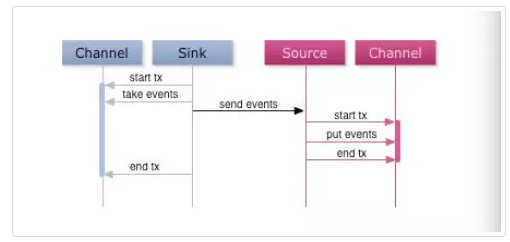
其次,数据流中 Channel的持久性。Flume中MemoryChannel是可能丢失数据的(当Agent死掉时),而FileChannel是持久性的,提供类似mysql的日志机制,保证数据不丢失。
3、可扩展性(scalability)
可扩展性(scalability)是指系统能够线性扩展。当日志量增大时,系统能够以简单的增加机器来达到线性扩容的目的。对于基于Flume的日志收集系统来说,需要在设计的每一层,都可以做到线性扩展地提供服务。下面将对每一层的可扩展性做相应的说明。
3.1 Agent层
对于Agent这一层来说,每个机器部署一个Agent,可以水平扩展,不受限制。一个方面,Agent收集日志的能力受限于机器的性能,正常情况下一个Agent可以为单机提供足够服务。另一方面,如果机器比较多,可能受限于后端Collector提供的服务,但Agent到Collector是有Load Balance机制,使得Collector可以线性扩展提高能力。
3.2 Collector层
对于Collector这一层,Agent到Collector是有Load Balance机制,并且Collector提供无差别服务,所以可以线性扩展。其性能主要受限于Store层提供的能力。
3.3 Store层
对于Store这一层来说,Hdfs和Kafka都是分布式系统,可以做到线性扩展。Bypass属于临时的应用,只对应于某一类日志,性能不是瓶颈。
4、Channel的选择
Flume提供常用的MemoryChannel和FileChannel优缺点相反,分别有自己适合的场景。然而,对于大部分应用来说,我们希望Channel可以同提供高吞吐和大缓存。基于此,美团开发了DualChannel。
DualChannel:基于 MemoryChannel和 FileChannel开发。当堆积在Channel中的events数小于阈值时,所有的events被保存在MemoryChannel中,Sink从MemoryChannel中读取数据; 当堆积在Channel中的events数大于阈值时, 所有的events被自动存放在FileChannel中,Sink从FileChannel中读取数据。这样当系统正常运行时,我们可以使用MemoryChannel的高吞吐特性;当系统有异常时,我们可以利用FileChannel的大缓存的特性。
5、系统监控
5.1 发送速度,拥堵情况,写Hdfs速度
5.2 flume写hfds状态的监控
5.3 日志大小异常监控
对于重要的日志,我们会每个小时都监控日志大小周同比是否有较大波动,并给予提醒,这个报警有效的发现了异常的日志,且多次发现了应用方日志发送的异常,及时给予了对方反馈,帮助他们及早修复自身系统的异常。
6、美团优化经验参考
6.1 Flume的问题总结
Channel“水土不服”:使用固定大小的MemoryChannel在日志高峰时常报队列大小不够的异常;使用FileChannel又导致IO繁忙的问题;
HdfsSink的性能问题:使用HdfsSink向Hdfs写日志,在高峰时间速度较慢;
系统的管理问题:配置升级,模块重启等;
6.2 增加Zabbix monitor服务
Flume本身提供了http, ganglia的监控服务,而我们目前主要使用zabbix做监控。因此,我们为Flume添加了zabbix监控模块,和sa的监控服务无缝融合。
另一方面,净化Flume的metrics。只将我们需要的metrics发送给zabbix,避免 zabbix server造成压力。目前我们最为关心的是Flume能否及时把应用端发送过来的日志写到Hdfs上, 对应关注的metrics为:
Source : 接收的event数和处理的event数
Channel : Channel中拥堵的event数
Sink : 已经处理的event数
6.3 增加DualChannel
flumee本身提供了MemoryChannel和FileChannel。MemoryChannel处理速度快,但缓存大小有限,且没有持久化;FileChannel则刚好相反。我们希望利用两者的优势,在Sink处理速度够快,Channel没有缓存过多日志的时候,就使用MemoryChannel,当Sink处理速度跟不上,又需要Channel能够缓存下应用端发送过来的日志时,就使用FileChannel,由此我们开发了DualChannel,能够智能的在两个Channel之间切换。
6.4 增加NullChannel
Flume提供了NullSink,可以把不需要的日志通过NullSink直接丢弃,不进行存储。然而,Source需要先将events存放到Channel中,NullSink再将events取出扔掉。为了提升性能,我们把这一步移到了Channel里面做,所以开发了NullChannel。
6.5 Flume系统调优经验总结
HdfsSink中默认的serializer会每写一行在行尾添加一个换行符,我们日志本身带有换行符,这样会导致每条日志后面多一个空行,修改配置不要自动添加换行符; lc.sinks.sink_hdfs.serializer.appendNewline = false
调大MemoryChannel的capacity,尽量利用MemoryChannel快速的处理能力;
调大HdfsSink的batchSize,增加吞吐量,减少hdfs的flush次数;
适当调大HdfsSink的callTimeout,避免不必要的超时错误;
6.6 HdfsSink获取Filename的优化
HdfsSink的path参数指明了日志被写到Hdfs的位置,该参数中可以引用格式化的参数,将日志写到一个动态的目录中。这方便了日志的管理。例如我们可以将日志写到category分类的目录,并且按天和按小时存放:
dfsS ink中处理每条event时,都要根据配置获取此event应该写入的Hdfs path和filename,默认的获取方法是通过正则表达式替换配置中的变量,获取真实的path和filename。因为此过程是每条event都要做的操作,耗时很长。通过我们的测试,20万条日志,这个操作要耗时6-8s左右。
由于我们目前的path和filename有固定的模式,可以通过字符串拼接获得。而后者比正则匹配快几十倍。拼接定符串的方式,20万条日志的操作只需要几百毫秒。
6.7 日志管理系统:图形化的展示和控制日志收集系统
7、监控
7.1 Flume主要有以下集中监控方式:
JMX监控
HTTP监控
Ganglia监控
自定义监控
7.2 metrics 指标
小结
可用性监控:Agent状态、负载均衡、故障转移
NullChannel、DuelChannel
热插拔扩展与维护
参考资料
https://tech.meituan.com/mt-log-system-optimization.html
https://segmentfault.com/a/1190000002532284
美团flume改进代码
监控:
http://www.wfuyu.com/technology/25331.html
http://blog.csdn.net/simonchi/article/details/43270461
https://www.jianshu.com/p/09493efe0fb8
ource(获取数据源):
exec (文件)
spoolingdir (文件夹)
taildir(文件夹及文件的变动)
kafka
syslog
http
channel(管道):
mem
file
kafka
sink(将channel中的 数据发送到目标地址):
hdfs
hive
hbase
ES
从集群可用性,可靠性,可扩展性和兼容性等方面,对架构优化进行设计。
1、可用性(availablity)
可用性(availablity)指固定周期内系统无故障运行总时间。要想提高系统的可用性,就需要消除系统的单点,提高系统的冗余度。
1.1 Agent死掉
机器死机
Agent进程死掉
所有的Agent在supervise的方式下启动,如果进程死掉会被系统立即重启,以提供服务。
所有的Agent进行存活监控,发现Agent死掉立即报警。
对于非常重要的日志,建议应用直接将日志写磁盘,Agent使用spooldir的方式获得最新的日志。
1.2 负载均衡与故障转移
模块分解详解图
1.3 Hdfs正常停机
在Collector的HdfsSink中提供了开关选项,可以控制Collector停止写Hdfs,并且将所有的events缓存到FileChannel的功能。
1.4 Hdfs异常停机或不可访问
假如Hdfs异常停机或不可访问,此时Collector无法写Hdfs。由于我们使用DualChannel,Collector可以将所收到的events缓存到FileChannel,保存在磁盘上,继续提供服务。当Hdfs恢复服务以后,再将FileChannel中缓存的events再发送到Hdfs上。这种机制类似于Scribe,可以提供较好的容错性
1.5 Collector变慢或者Agent/Collector网络变慢
如果Collector处理速度变慢(比如机器load过高)或者Agent/Collector之间的网络变慢,可能导致Agent发送到Collector的速度变慢。同样的,对于此种情况,我们在Agent端使用DualChannel,Agent可以将收到的events缓存到FileChannel,保存在磁盘上,继续提供服务。当Collector恢复服务以后,再将FileChannel中缓存的events再发送给Collector。
1.6 Hdfs变慢
当Hadoop上的任务较多且有大量的读写操作时,Hdfs的读写数据往往变的很慢。由于每天,每周都有高峰使用期,所以这种情况非常普遍。对于Hdfs变慢的问题,我们同样使用DualChannel来解决。当Hdfs写入较快时,所有的events只经过MemChannel传递数据,减少磁盘IO,获得较高性能。当Hdfs写入较慢时,所有的events只经过FileChannel传递数据,有一个较大的数据缓存空间。
2、可靠性(reliability)
可靠性(reliability)是指Flume在数据流的传输过程中,保证events的可靠传递。
对Flume来说,所有的events都被保存在Agent的Channel中,然后被发送到数据流中的下一个Agent或者最终的存储服务中。那么一个Agent的Channel中的events什么时候被删除呢?当且仅当它们被保存到下一个Agent的Channel中或者被保存到最终的存储服务中。这就是Flume提供数据流中点到点的可靠性保证的最基本的单跳消息传递语义。
那么Flume是如何做到上述最基本的消息传递语义呢?
首先,Agent间的事务交换。Flume使用事务的办法来保证event的可靠传递。Source和Sink分别被封装在事务中,这些事务由保存event的存储提供或者由Channel提供。这就保证了event在数据流的点对点传输中是可靠的。在多级数据流中,如下图,上一级的Sink和下一级的Source都被包含在事务中,保证数据可靠地从一个Channel到另一个Channel转移。
其次,数据流中 Channel的持久性。Flume中MemoryChannel是可能丢失数据的(当Agent死掉时),而FileChannel是持久性的,提供类似mysql的日志机制,保证数据不丢失。
3、可扩展性(scalability)
可扩展性(scalability)是指系统能够线性扩展。当日志量增大时,系统能够以简单的增加机器来达到线性扩容的目的。对于基于Flume的日志收集系统来说,需要在设计的每一层,都可以做到线性扩展地提供服务。下面将对每一层的可扩展性做相应的说明。
3.1 Agent层
对于Agent这一层来说,每个机器部署一个Agent,可以水平扩展,不受限制。一个方面,Agent收集日志的能力受限于机器的性能,正常情况下一个Agent可以为单机提供足够服务。另一方面,如果机器比较多,可能受限于后端Collector提供的服务,但Agent到Collector是有Load Balance机制,使得Collector可以线性扩展提高能力。
3.2 Collector层
对于Collector这一层,Agent到Collector是有Load Balance机制,并且Collector提供无差别服务,所以可以线性扩展。其性能主要受限于Store层提供的能力。
3.3 Store层
对于Store这一层来说,Hdfs和Kafka都是分布式系统,可以做到线性扩展。Bypass属于临时的应用,只对应于某一类日志,性能不是瓶颈。
4、Channel的选择
Flume提供常用的MemoryChannel和FileChannel优缺点相反,分别有自己适合的场景。然而,对于大部分应用来说,我们希望Channel可以同提供高吞吐和大缓存。基于此,美团开发了DualChannel。
DualChannel:基于 MemoryChannel和 FileChannel开发。当堆积在Channel中的events数小于阈值时,所有的events被保存在MemoryChannel中,Sink从MemoryChannel中读取数据; 当堆积在Channel中的events数大于阈值时, 所有的events被自动存放在FileChannel中,Sink从FileChannel中读取数据。这样当系统正常运行时,我们可以使用MemoryChannel的高吞吐特性;当系统有异常时,我们可以利用FileChannel的大缓存的特性。
5、系统监控
5.1 发送速度,拥堵情况,写Hdfs速度
5.2 flume写hfds状态的监控
5.3 日志大小异常监控
对于重要的日志,我们会每个小时都监控日志大小周同比是否有较大波动,并给予提醒,这个报警有效的发现了异常的日志,且多次发现了应用方日志发送的异常,及时给予了对方反馈,帮助他们及早修复自身系统的异常。
6、美团优化经验参考
6.1 Flume的问题总结
Channel“水土不服”:使用固定大小的MemoryChannel在日志高峰时常报队列大小不够的异常;使用FileChannel又导致IO繁忙的问题;
HdfsSink的性能问题:使用HdfsSink向Hdfs写日志,在高峰时间速度较慢;
系统的管理问题:配置升级,模块重启等;
6.2 增加Zabbix monitor服务
Flume本身提供了http, ganglia的监控服务,而我们目前主要使用zabbix做监控。因此,我们为Flume添加了zabbix监控模块,和sa的监控服务无缝融合。
另一方面,净化Flume的metrics。只将我们需要的metrics发送给zabbix,避免 zabbix server造成压力。目前我们最为关心的是Flume能否及时把应用端发送过来的日志写到Hdfs上, 对应关注的metrics为:
Source : 接收的event数和处理的event数
Channel : Channel中拥堵的event数
Sink : 已经处理的event数
6.3 增加DualChannel
flumee本身提供了MemoryChannel和FileChannel。MemoryChannel处理速度快,但缓存大小有限,且没有持久化;FileChannel则刚好相反。我们希望利用两者的优势,在Sink处理速度够快,Channel没有缓存过多日志的时候,就使用MemoryChannel,当Sink处理速度跟不上,又需要Channel能够缓存下应用端发送过来的日志时,就使用FileChannel,由此我们开发了DualChannel,能够智能的在两个Channel之间切换。
6.4 增加NullChannel
Flume提供了NullSink,可以把不需要的日志通过NullSink直接丢弃,不进行存储。然而,Source需要先将events存放到Channel中,NullSink再将events取出扔掉。为了提升性能,我们把这一步移到了Channel里面做,所以开发了NullChannel。
6.5 Flume系统调优经验总结
HdfsSink中默认的serializer会每写一行在行尾添加一个换行符,我们日志本身带有换行符,这样会导致每条日志后面多一个空行,修改配置不要自动添加换行符; lc.sinks.sink_hdfs.serializer.appendNewline = false
调大MemoryChannel的capacity,尽量利用MemoryChannel快速的处理能力;
调大HdfsSink的batchSize,增加吞吐量,减少hdfs的flush次数;
适当调大HdfsSink的callTimeout,避免不必要的超时错误;
6.6 HdfsSink获取Filename的优化
HdfsSink的path参数指明了日志被写到Hdfs的位置,该参数中可以引用格式化的参数,将日志写到一个动态的目录中。这方便了日志的管理。例如我们可以将日志写到category分类的目录,并且按天和按小时存放:
lc.sinks.sink_hdfs.hdfs.path = /user/hive/work/orglog.db/%{category}/dt=%Y%m%d/hour=%HdfsS ink中处理每条event时,都要根据配置获取此event应该写入的Hdfs path和filename,默认的获取方法是通过正则表达式替换配置中的变量,获取真实的path和filename。因为此过程是每条event都要做的操作,耗时很长。通过我们的测试,20万条日志,这个操作要耗时6-8s左右。
由于我们目前的path和filename有固定的模式,可以通过字符串拼接获得。而后者比正则匹配快几十倍。拼接定符串的方式,20万条日志的操作只需要几百毫秒。
6.7 日志管理系统:图形化的展示和控制日志收集系统
7、监控
7.1 Flume主要有以下集中监控方式:
JMX监控
HTTP监控
Ganglia监控
自定义监控
7.2 metrics 指标
{
"SOURCE.src-1":{
"OpenConnectionCount":"0", //目前与客户端或sink保持连接的总数量(目前只有avro source展现该度量)
"Type":"SOURCE",
"AppendBatchAcceptedCount":"1355", //成功提交到channel的批次的总数量
"AppendBatchReceivedCount":"1355", //接收到事件批次的总数量
"EventAcceptedCount":"28286", //成功写出到channel的事件总数量,且source返回success给创建事件的sink或RPC客户端系统
"AppendReceivedCount":"0", //每批只有一个事件的事件总数量(与RPC调用中的一个append调用相等)
"StopTime":"0", //source停止时自Epoch以来的毫秒值时间
"StartTime":"1442566410435", //source启动时自Epoch以来的毫秒值时间
"EventReceivedCount":"28286", //目前为止source已经接收到的事件总数量
"AppendAcceptedCount":"0" //单独传入的事件到Channel且成功返回的事件总数量
},
"CHANNEL.ch-1":{
"EventPutSuccessCount":"28286", //成功写入channel且提交的事件总数量
"ChannelFillPercentage":"0.0", //channel满时的百分比
"Type":"CHANNEL",
"StopTime":"0", //channel停止时自Epoch以来的毫秒值时间
"EventPutAttemptCount":"28286", //Source尝试写入Channe的事件总数量
"ChannelSize":"0", //目前channel中事件的总数量
"StartTime":"1442566410326", //channel启动时自Epoch以来的毫秒值时间
"EventTakeSuccessCount":"28286", //sink成功读取的事件的总数量
"ChannelCapacity":"1000000", //channel的容量
"EventTakeAttemptCount":"313734329512" //sink尝试从channel拉取事件的总数量。这不意味着每次事件都被返回,因为sink拉取的时候channel可能没有任何数据
},
"SINK.sink-1":{
"Type":"SINK",
"ConnectionClosedCount":"0", //下一阶段或存储系统关闭的连接数量(如在HDFS中关闭一个文件)
"EventDrainSuccessCount":"28286", //sink成功写出到存储的事件总数量
"KafkaEventSendTimer":"482493",
"BatchCompleteCount":"0", //与最大批量尺寸相等的批量的数量
"ConnectionFailedCount":"0", //下一阶段或存储系统由于错误关闭的连接数量(如HDFS上一个新创建的文件因为超时而关闭)
"EventDrainAttemptCount":"0", //sink尝试写出到存储的事件总数量
"ConnectionCreatedCount":"0", //下一个阶段或存储系统创建的连接数量(如HDFS创建一个新文件)
"BatchEmptyCount":"0", //空的批量的数量,如果数量很大表示souce写数据比sink清理数据慢速度慢很多
"StopTime":"0",
"RollbackCount":"9", //
"StartTime":"1442566411897",
"BatchUnderflowCount":"0" //比sink配置使用的最大批量尺寸更小的批量的数量,如果该值很高也表示sink比souce更快
}
}小结
可用性监控:Agent状态、负载均衡、故障转移
NullChannel、DuelChannel
热插拔扩展与维护
参考资料
https://tech.meituan.com/mt-log-system-optimization.html
https://segmentfault.com/a/1190000002532284
美团flume改进代码
监控:
http://www.wfuyu.com/technology/25331.html
http://blog.csdn.net/simonchi/article/details/43270461
https://www.jianshu.com/p/09493efe0fb8

相关文章推荐
- flume-ng性能优化与架构设计
- flume-ng性能优化与架构设计
- flume-ng性能优化与架构设计
- flume-ng性能优化与架构设计
- flume-ng性能优化与架构设计
- TYPESDK手游聚合SDK服务端设计思路与架构之四:流程优化之信息安全与订单校验
- 基于Flume的美团日志收集系统(一)架构和设计
- 关于架构的优化和设计,架构师必须悟透的事情
- [架构] 大型网站架构系列之三 ---------------- 多对多关系的优化设计
- MySQL中SQL优化和架构设计的一些简单想法
- 网站架构优化与设计模式
- 疯狂代码,大型网站架构系列之三,多对多关系的优化设计
- TYPESDK手游聚合SDK服务端设计思路与架构之三:流程优化之订单保存与通知
- 基于Flume的美团日志收集系统(一)架构和设计
- 资料收集:高并发 高性能 高扩展性 Web 2.0 站点架构设计及优化策略
- Flume(NG)架构设计要点及配置实践
- Flume(NG)架构设计要点及配置实践
- 资料收集:高并发 高性能 高扩展性 Web 2.0 站点架构设计及优化策略
- 基于Flume的美团日志收集系统(一)架构和设计
- 吴英昊:电商搜索引擎的架构设计和性能优化