分布式架构下的通信(一)
断断续续已经写了三年时光了,三年时光历历在目,也许这是我最后一年写技术类文章了。之前听朋友说,在三亚吹着海风写着代码是一种享受,所以头一热也就来体验了一把。陌生的环境给人一种空灵的感受,在这个我从未留过回忆的城市,给人一种什么都可以抓住的冲动,但也有什么都不敢抓的恐惧,也许这就是从头来过的体验,写完这篇文章后就准备返程回到那个刻满我无数回忆的旧城了,而这即将离开的新城也即将变成旧城。
之所以准备写通信这块内容,原因有两个,一个是即使你后端业务设计再大,如果连接受限,用户进不来,其实造成的影响是特别大的;另一个就是最近我们自己项目最近也出现了类型的情况,所以我想写这一个专题说一下通信的事,希望这一专题能给自己的人一个启发,可以学一点东西。
一、http协议
http是指HyperText Transfer Protocol,超文本传输协议,是一种详细规定了浏览器和万维网(WWW = World Wide Web)服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。它可以使浏览器更加高效,使网络传输减少。也可以理解成用于定义web浏览器到web服务器之间交换数据过程标准以及数据本身的格式。
http协议是tcp/ip协议族中的一种,而且是基于tcp协议之上,在http协议之上加tls协议或ssl协议就成了https协议,https相对于http来说安全性更高,当前微信小程序的请求都必须是https协议性质。http协议不单单是应用于web请求,只要是通信的双方都遵守了这个协议就可以通信,但主要是浏览器的web请求和响应。
最近考了高项,在学习备考的过程中才发现tcp/ip其实不是一个协议,而是包含了很多协议的协议族,tcp/ip包含了ip协议、imcp协议、tcp协议、udp协议、ftp协议、http协议、smtp协议、dns协议等。
tcp/ip把通信网络分为四层,也称为tcp/ip四层模型,从底层到上层依次为:网络接口层、网络层、传输层、应用层,如下图。
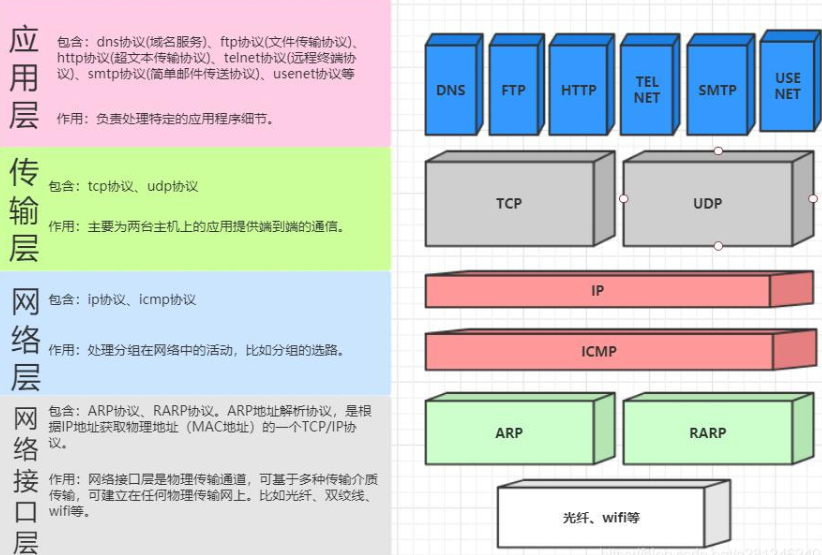
http协议位于tcp/ip协议模型中的应用层,基于请求—响应模式的,这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端,必须现有请求才有相应。http协议是一个无状态的协议,无状态是指协议对于事务处理没有记忆能力,一次请求完成立即关闭当前请求,且每一次请求都是完全隔离的,浏览器到web服务器之间的所有通讯是完全独立分开的请求和相应对。http默认都是短连接。
二、HTTP报文结构
传输层、网络层他们都有自己的头部信息来标识。HTTP 协议也是与 TCP/UDP 类似,同样也需要在实际传输的数据前附加一些头数据,不过与 TCP/UDP 不同的是,它是一个“纯文本”的协议,所以头数据都是 ASCII 码的文本,可以很容易地用肉眼阅读,不用借助程序解析也能够看懂。
用于HTTP的协议交互的信息被称为HTTP报文。请求端的HTTP报文叫做请求报文,响应端的叫做响应报文。
2.1、请求报文
HTTP的这两种报文都由四部分组成:请求行(起始行)、请求头(首部字段)、空行、请求体(报文主体)。

- 请求行:包含【请求的方法如GET、POST】,【请求URI】和【HTTP版本】,中间用空格分隔
- 请求头:包含请求的各种条件和属性,使用key:value的形式展示
- 空行:它的作用是通过一个空行,告诉服务器请求头部到此为止。
- 请求体:实际传输的数据,不一定是文本,可以是图片视频等二进制文件。若方法字段是GET,则此项为空,没有数据;若方法字段是POST,则通常来说此处放置的就是要提交的数据。其中,请求行和请求头可以合称为请求头,即常说的 header ,而请求体是我们常说的 body 。
请求头整体结构大概就是:

HTTP协议规定报文必须有 header ,可以没有 body ,比如常用的 GET 请求。且 header 和 body 中间必须有个空行。
一个GET请求一般实际上长这个样子:
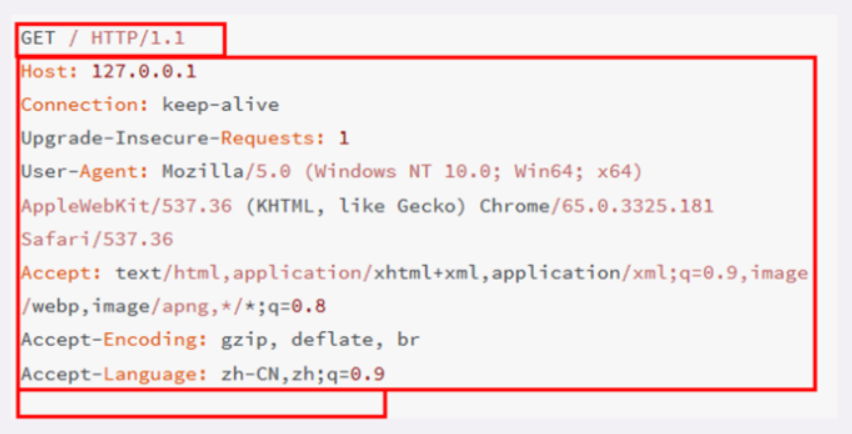
在这个浏览器发出的请求报文里,第一行“GET / HTTP/1.1”就是请求行,其中 GET 就是请求方法, / 就是请求的 URI ,HTTP/1.1 就是HTTP协议及版本;而后面的“Host”、“Connection”等等都属于 header,报文的最后是一个空白行结束,没有 body。
对于POST请求而言,几乎一样,只是请求方法变成POST,空行下面会有请求参数构成的Body。
2.2、响应报文
同样的,HTTP响应报文也由四部分组成:响应行(状态行)、响应头、空行、响应体(报文主体)。
- 响应行:响应行一般由【协议版本】、【状态码如200】及其【描述】组成 比如 HTTP/1.1 200 OK
- 响应头:响应头用于描述服务器的基本信息,以及数据的描述,服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据。
- 空行:它的作用是通过一个空行,告诉客户端请求头部到此为止。
- 响应体:响应体就是响应的消息体,如果是纯数据就是返回纯数据,如果请求的是HTML页面,那么返回的就是HTML代码,如果是JS就是JS代码,如此之类。
响应行和响应头整体结构大概为:

来个实际例子,如请求一个HTML页面的请求报文和响应报文:

三、HTTP的头部字段
头部的字段帮助客户端和服务端更好地交互,这里先拿几个重要字段说明下。
3.1、Accept和Content-Type
数据交互的时候,我们需要解决三个问题:数据类型协商(数据类型、压缩算法)、语言类型协商、字符集编码类型协商。解决了这三个问题,两者之间就可以愉快地进行交流了。
【①数据类型协商和压缩算法协商】
首先我们要知道数据是有佷多类型的,比如分为文本类型有:text/html、text/plain、text/css等;有图片image/gif、image/png等,有音频和视频:audio/mepg、audio/mp4等。也有我们常用的不固定的数据格式,由上层应用来解释的比如application/json。
这些类型有个名字,叫做:MIME Type,但是HTTP传输的时候会进行数据压缩,因此还有一个字段叫做:Encoding Type,告诉对方数据用了什么压缩格式,好让对方还原出来原始数据。Encoding Type类型就少了佷多,一般用的是:gzip、deflate、br等压缩算法。
好了,有了 MIME type 和 Encoding type,无论是浏览器还是服务器就都可以轻松识别出 body 的类型,也就能够正确处理数据了。通过什么字段呢?
客户端可以通过 Accept 字段告诉服务器希望接收什么格式的数据,服务器可以用 content-type 告诉客户端实际发送了什么格式的数据。
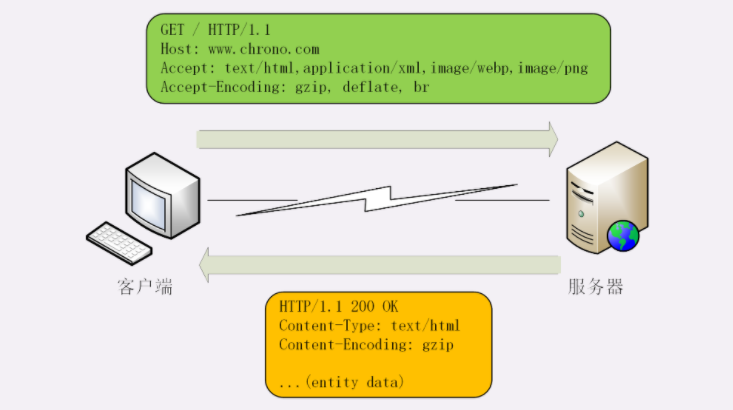
上图中,意思是客户端告诉服务器,我只能看懂HTML、XML的文本和数据,还有就是webp和png格式的图片,其他的我不认识。服务器返回的时候告诉客户端本次返回内容的格式和压缩算法。
【②语言类型协商】
除了格式的协商,还有语言和编码的协商,如果客户端只认识英文,而服务器返回了中文,不就尴尬了。
客户端会发送Accept-Language表明自己看得懂的语言,比如zh-CN 的汉语文字。
Accept-Language: zh-CN, zh, en
而服务器会在响应头中用Content-Language告诉客户端实体数据用的语言类型。
Content-Language: zh-CN
【③字符集编码类型协商】
而字符集编码是客户端发送Accept-Charset字段来说明,比如自己只能处理GBK和UTF8字符编码,其他的不行。服务器如果返回UTF8编码如何返回呢?逐一响应头没有对应的Content-Charset,而是在ontent-Type字段的数据类型后面用“charset=xxx”来表示。
Accept-Charset: gbk, utf-8 Content-Type: text/html; charset=utf-8
这边不能乱,总结下:
- 数据类型表示实体数据的类型,是文本还是图片等,相关的头字段是 Accept 和 Content-Type;
- 压缩算法表示实体数据的压缩方式,相关的头字段是 Accept-Encoding 和 Content-Encoding;
- 语言类型表示实体数据的自然语言,相关的头字段是 Accept-Language 和 Content-Language;
- 字符集表示实体数据的编码方式,相关的头字段是 Accept-Charset和 Content-Type;

不过现在的浏览器都支持多种字符集,通常不会发送 Accept-Charset,而服务器也不会发送 Content-Language,因为使用的语言完全可以由字符集推断出来,所以在请求头里一般只会有 Accept-Language 字段,响应头里只会有 Content-Type字段:
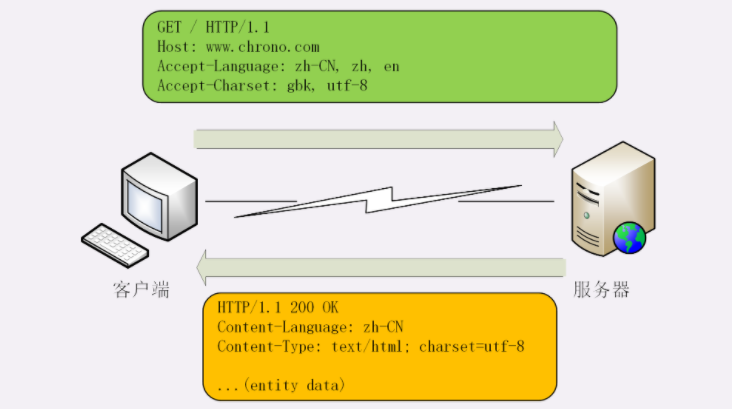
- Host:指定被请求资源的IP和PORT
- Referer:告诉服务器我是从哪个页面链接过来的
- User-Agent:客户端所使用的操作系统和浏览器名称、版本
- Connection:控制是否开启长连接,如果是keep-alive说明是开启长连接,同一个客户端的请求可以复用一个TCP连接。反之close就不复用TCP连接。
上面这样说可能有些人对http的整体通信过程还是不够了解,下面就从宏观的角度从通信发包和接包的过程来进行讲解:
http通信发包过程
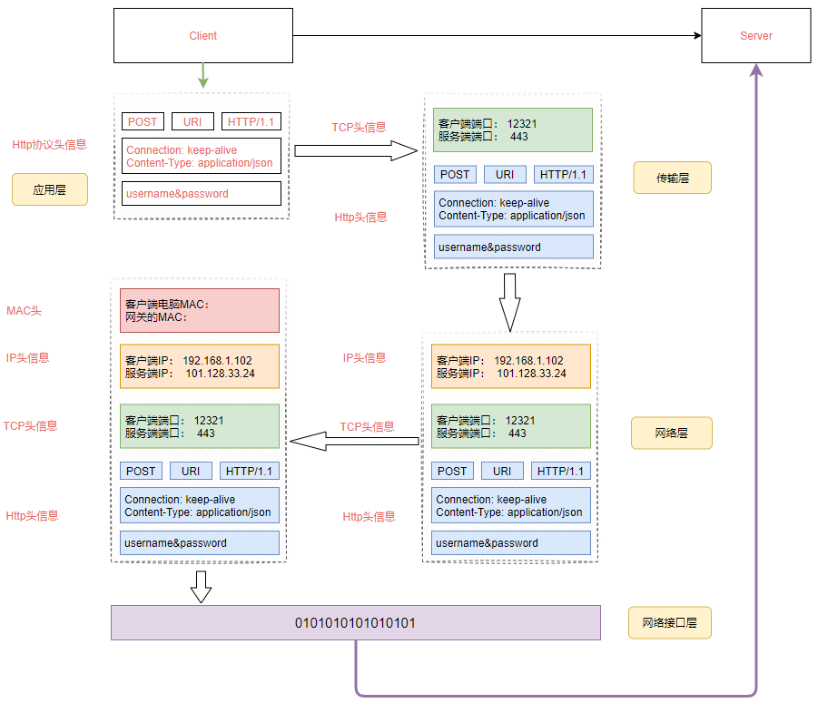
工作流程描述如下:
-
假设我们要登录某一个网站,此时基于Http协议会构建一个http协议报文,这个报文中按照http协议的规范组装,其中包括要传输的用户名和密码。这个是属于应用层协议。
-
经过应用层封装后,浏览器会把应用层的包交给TCP/IP四层模型中的下一层,也就是传输层来完成,传输层有两种协议:
TCP协议,可靠的通信协议,该协议会确保数据包能达到目的地 - UDP协议,不可靠通信协议,可能会存在数据丢失
在http通信中使用了TCP协议,TCP协议会有两个端口,一个是浏览器监听的端口,一个是目标服务器进程的端口。操作系统会根据端口来判断这个数据包应该分发给那个进程。
-
传输层封装完成后,该数据包会技术交给网络层来处理,网络层协议是IP协议,IP协议中会包含源IP地址(也就是客户端及其的IP)和目标服务器的IP地址。
-
操作系统知道了目标IP地址后,就开始根据这个IP来寻找目标机器,而目标服务器一定是部署在不同的地方,这种跨网络节点的访问,需要经过网关(所谓网关就是一个网络到另外一个网络的关口)。
所以数据包首先需要先通过自己当前所在网络的网关出去,然后访问到目标服务器,但是在数据包传输到目标服务器之前,需要再组装MAC头信息。
Mac头包含本地的Mac地址和目标服务器的Mac地址,这个MAC地址怎么获得的呢?
获取本机MAC地址的方法是,操作系统会发送一个广播消息询问网关地址(192.168.1.1)是谁?收到该广播消息的网关会回应一个MAC地址。这个广播消息是基于ARP协议实现的(这个协议简单来说就是已知目标机器的ip,需要获得目标机器的mac地址。(发送一个广播消息,这个ip是谁的,请来认领。认领ip的机器会发送一个mac地址的响应))。
为了避免每次都用 ARP 请求,机器本地也会进行 ARP 缓存。当然机器会不断地上线下线,IP 也可能会变,所以 ARP 的 MAC 地址缓存过一段时间就会过期。
-
获取远程机器的MAC地址的方法也同样是基于ARP协议实现的。
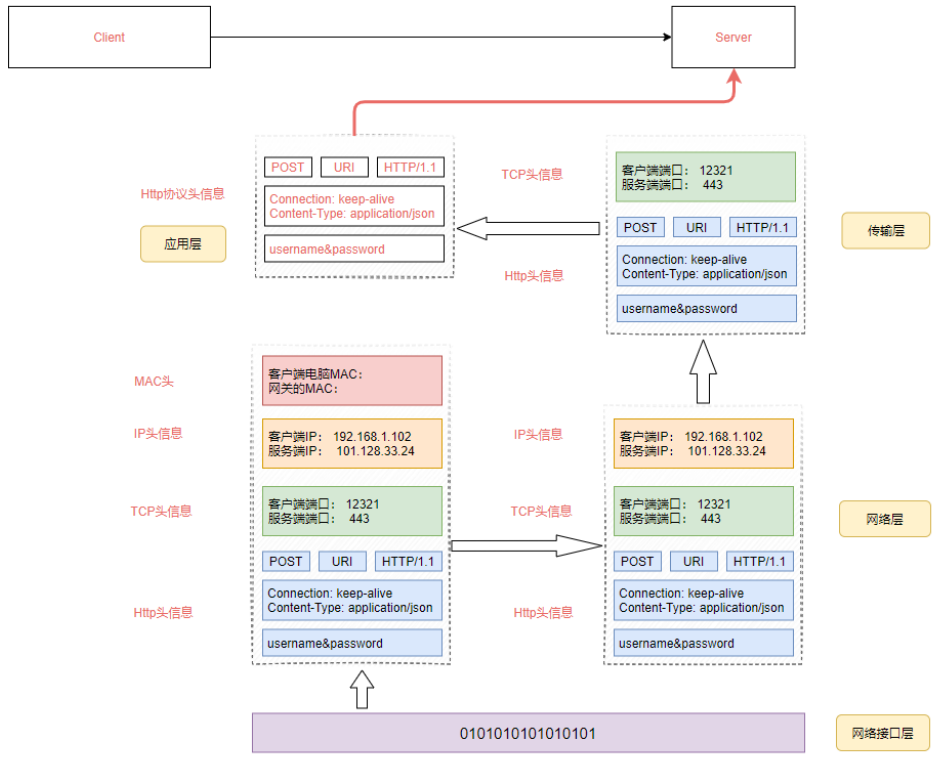
当数据包发送到网关后,会根据网关的路由信息判断该数据包要传输到那个网段上。数据从客户端发送到目标服务器,可能会经过多个网关,所以数据包根据网关路由进入到下一个网关后,继续根据下一个网关的MAC地址寻找下下一个网关,直到到达目标网络服务器上。
这个时候服务器收到包之后,最后一个网关知道这个网络包就是要去当前局域网的,于是拿着目标IP通过ARP协议大喊一声这是谁? 目标服务器就会给网关回复一个MAC地址。 然后网络包在最后那个网关修改目标的MAC地址,通过这个MAC地址,网络包找到了目标服务器。
当目标服务器和MAC地址对上后,开始取出MAC头信息,接着把数据包发送给操作系统的网络层。网络层会取出IP头信息,IP头里面会写上一层封装的是TCP协议,于是交给传输层来处理。
在这一层中,对于收到的每个数据包都会有一个回复,表示服务器端已经收到了该数据包。如果过一段时间客户端没有收到该确认包,发送端的 TCP 层会重新发送这个包,还是上面的过程,直到最终收到回复。
这个重试是TCP协议层来实现的,不需要我们应用来主动发起。
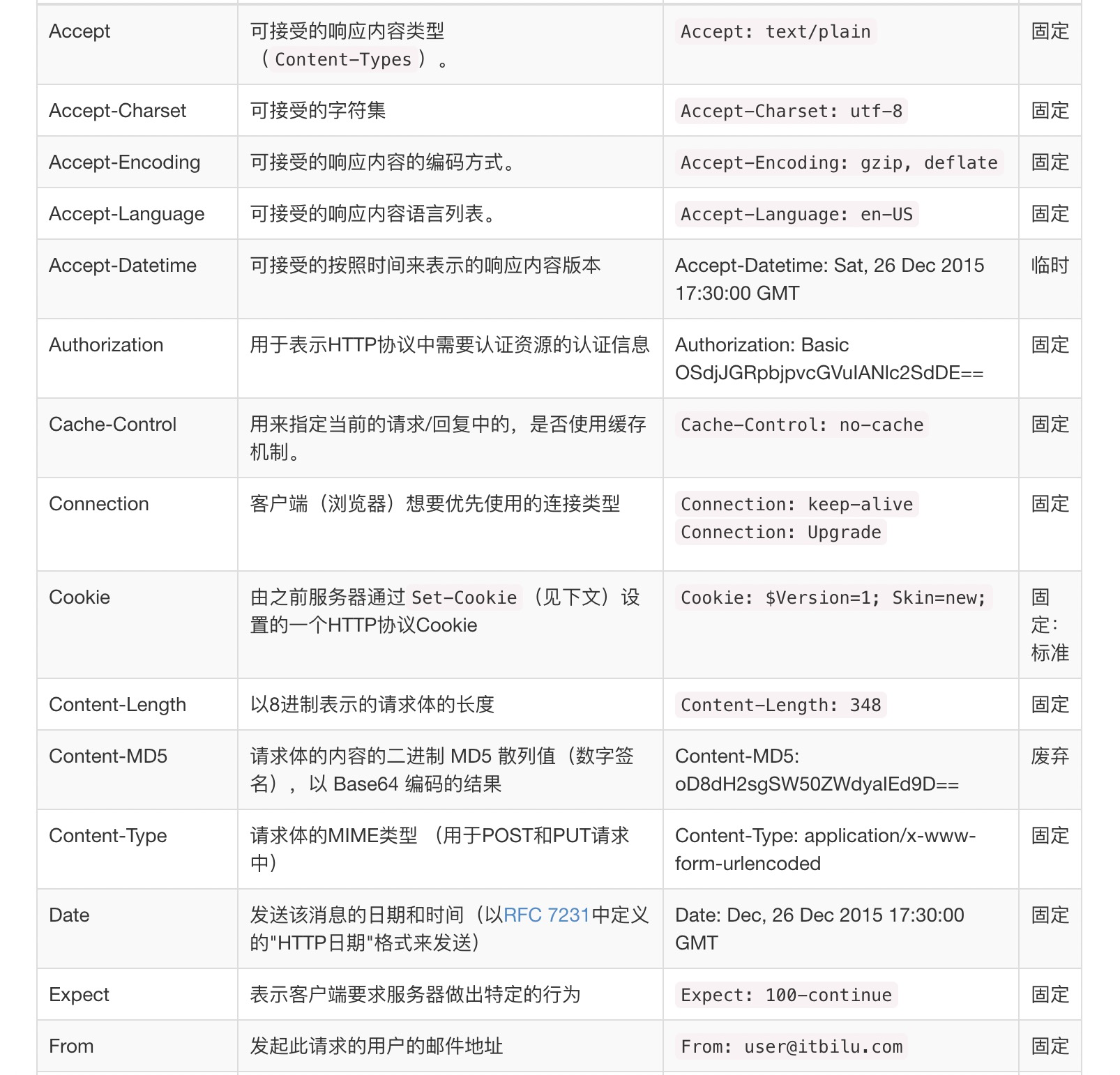
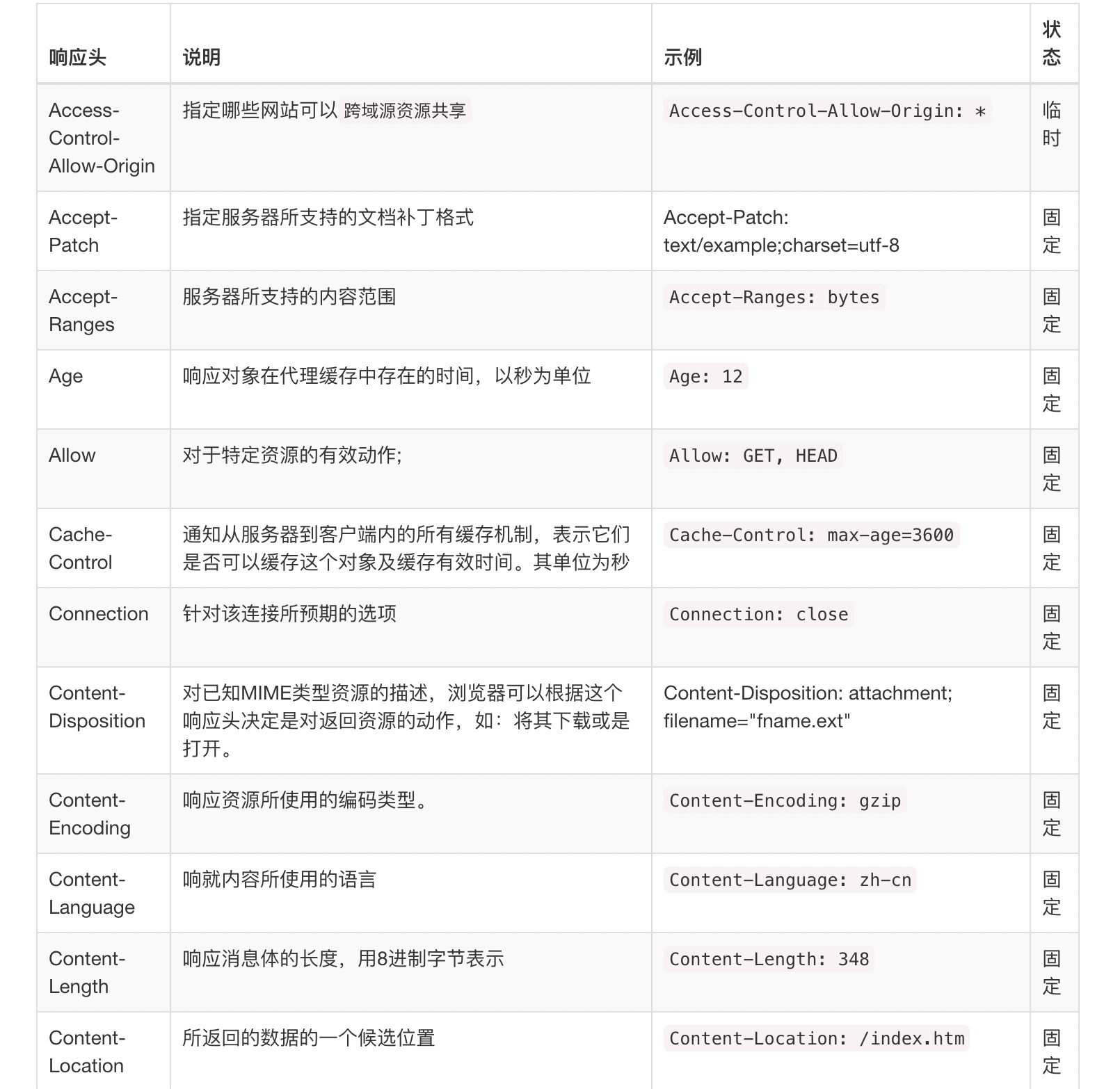
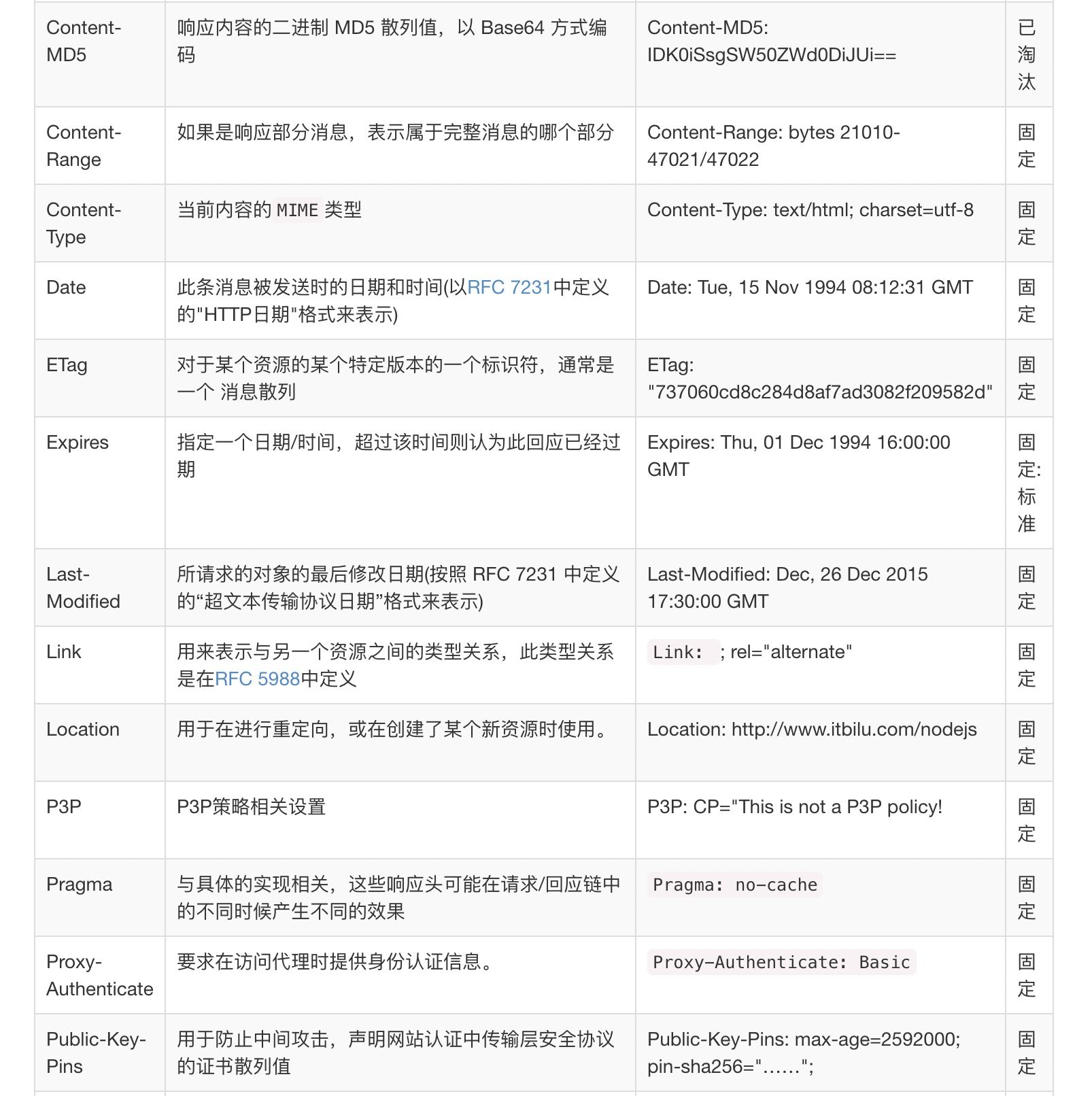
HTTP的头佷多,下面用几张图来预览下,后续将根据实际情况再对某些头部字段进行详解。
常用的HTTP请求头
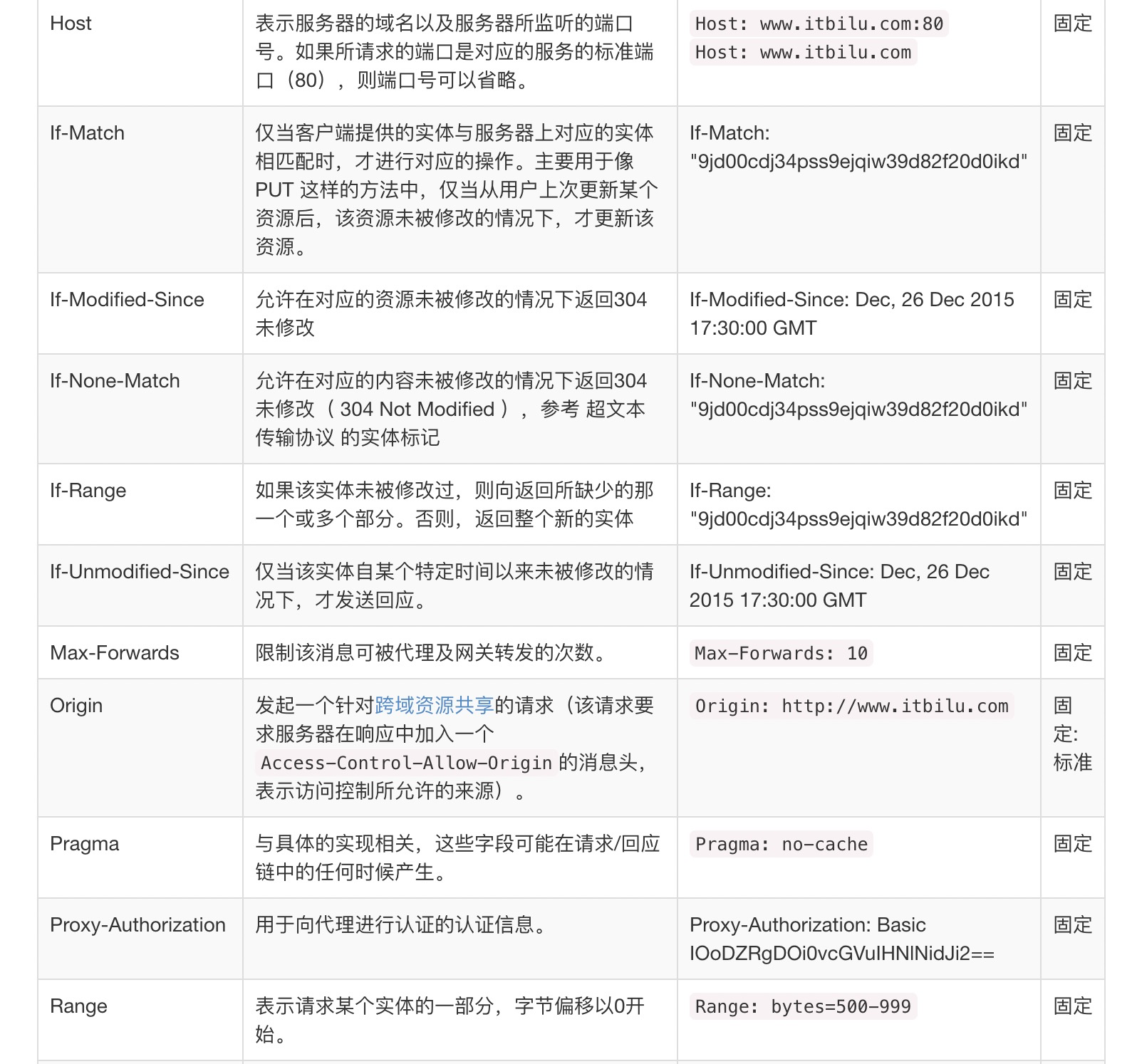

常用的HTTP响应头


- 大型网站系统架构实践(二)分布式模块之间的通信
- 业界 | Poseidon:高效的分布式深度学习通信架构
- java分布式通信系统(J2EE分布式服务器架构)
- java分布式通信系统(J2EE分布式服务器架构)
- java分布式通信系统(J2EE分布式服务器架构)
- 大型网站系统架构实践(二)分布式模块之间的通信
- java分布式通信系统(J2EE分布式服务器架构)
- java分布式通信系统(J2EE分布式服务器架构)
- 大型网站系统架构实践(二)分布式模块之间的通信
- 大型网站系统架构实践(二)分布式模块之间的通信
- 小白学分布式程序开发2-分布式架构下系统间交互的5种通信模式
- java平台上异构系统通信和分布式架构经常涉及的技术
- java分布式通信系统(J2EE分布式服务器架构)
- 大型网站系统架构实践(二)分布式模块之间的通信
- java分布式通信系统(J2EE分布式服务器架构)
- 大型网站系统架构实践(二)分布式模块之间的通信
- LAMP分布式架构,通过fcgi通信方式进行工作详解和缓存加速之压力测试。
- 大型网站系统架构实践(二)分布式模块之间的通信
- 【开源】.net 分布式架构之业务消息队列
- 蚂蚁金服架构到底有多强?看完这篇分布式服务架构PDF我跪了