TF(1): 基础理论
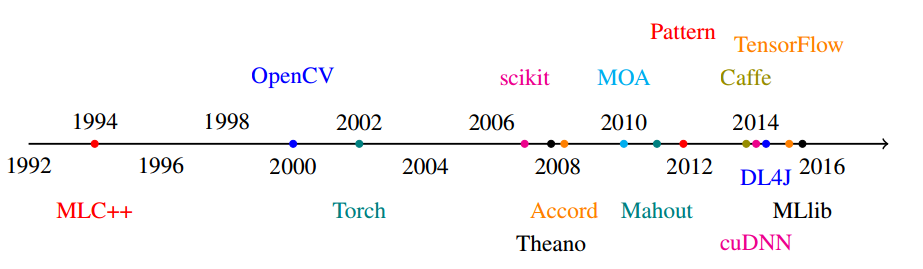
TensorFlow最初由Google大脑的研究员和工程师开发出来,用于机器学习和神经网络方面的研究,于2015.10宣布开源,在众多深度学习框架中脱颖而出,在Github上获得了最多的Star量。TensorFlow最早由Google Brain研究组发起。TensorFlow在历史上机器学习时间线如下:
-
- 官网:http://www.tersorflow.org
- Github网址:https://github.com/tensorflow/tensorflow
- 模型仓库网址:https://github.com/tensorflow/models
TensorFlow的计算可以表示为一种有向图(directed graph),或者称计算图(computation graph)。图中每一个运算操作(operation)是一个节点(node),节点之间的连接线称为边(edge)。计算图中的节点可以有任意多个输入和任意多个输出,每个节点都只有一个运算操作。在计算图中流动(flow)的数据被称为张量(tensor),故得名TensorFlow。计算图示例 如下:

TensorFlow关键版本发布历史
- 2015.11.09 在Github上开源(Ver0.5.0)
- 2015.12.10 支持Python3.3+,GPU性能提升...(Ver0.6.0)
- 2016.02.17 支持GPU使用Cuda7.0+、cuDNN R2+、cuDNN R4等运算加速库...(Ver0.7.0)
- 2016.04.30 通过gRPC实现分布式计算...(Ver0.8.0)
- 2016.06.28 支持Python3.5,支持iOS,支持Mac电脑上的GPU计算...(Ver0.9.0)
- 2016.09.13 添加C++ shape inference,添加graph-construction C/C++(大部分) Api...(Ver0.10.0)
- 2016.11.11 支持cuDNN 5、Cuda8.0,HDFS...(Ver0.11.0)
- 2016.12.21 支持Windows环境运行,cuDNN 5.1...(Ver0.12.0)
- 2017.02.16 发布正式版(Ver1.0.0)
- 2017.04.27 支持Windows下的Java Api...(Ver1.1.0)
- 2017.06.15 支持Windows下的Python 3.6...(Ver1.2.0)
前端API支持语言
- Python (推荐使用,API最全面)
- C++
- Go
- Java
- Rust
- Haskell
- 非官方(Julia、Javascript、R)
基本使用
- 使用Tensor表示数据
- 通过变量(Variable)输入训练数据,维护状态
- 使用计算图(computational graph)来表示计算任务
- 在会话(Session)的上下文(Context)来执行计算图
TensorFlow依赖视图
-

-
TF托管在github平台,有google groups和contributors共同维护。
-
TF提供了丰富的深度学习相关的API,如上一小节。
-
TF提供了可视化分析工具Tensorboard,方便分析和调整模型。
-
TF支持Linux平台,Windows平台,Mac平台,甚至手机移动设备等各种平台。
TF系统架构
TF的系统架构,从底向上分为设备管理和通信层、数据操作层、图计算层、API接口层、应用层。其中设备管理和通信层、数据操作层、图计算层是TF的核心层。如下图:
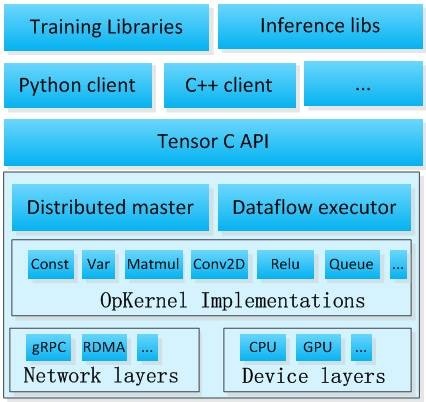
- 底层设备通信层负责网络通信和设备管理。设备管理可以实现TF设备异构的特性,支持CPU、GPU、Mobile等不同设备。网络通信依赖gRPC通信协议实现不同设备间的数据传输和更新。
- 第二层是Tensor的OpKernels实现。这些OpKernels以Tensor为处理对象,依赖网络通信和设备内存分配,实现了各种Tensor操作或计算。Opkernels不仅包含MatMul等计算操作,还包含Queue等非计算操作。
- 第三层是图计算层(Graph),包含本地计算流图和分布式计算流图的实现。Graph模块包含Graph的创建、编译、优化和执行等部分,Graph中每个节点都是OpKernels类型表示。
- 第四层是API接口层。Tensor C API是对TF功能模块的接口封装,便于其他语言平台调用。
- 第四层以上是应用层。不同编程语言在应用层通过API接口层调用TF核心功能实现相关实验和应用。
详细点的层次及功能划分,可以描述如下:

- 最底层是硬件计算资源,支持CPU、GPU;
- 支持两种通信协议;
- 数值计算层提供最基础的计算,有线性计算、卷积计算;
- 数据的计算都是以数组的形式参与计算;
- 计算图层用来设计神经网络的结构;
- 工作流层提供轻量级的框架调用
- 最后构造的深度学习网络可以通过TensorBoard服务端可视化
架构详解:
TensorFlow的系统结构以C API为界,将整个系统分为「前端」和「后端」两个子系统:
-
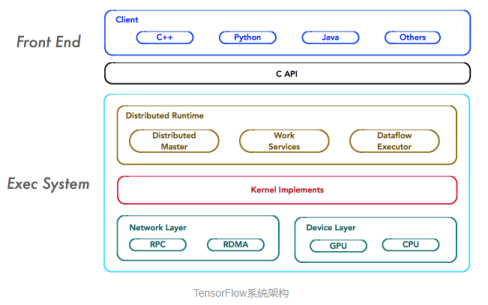
- 前端系统:提供编程模型,负责构造计算图;
- 后端系统:提供运行时环境,负责执行计算图。
如上图所示,重点关注系统中如下4个基本组件,它们是系统分布式运行机制的核心。
Client:
-
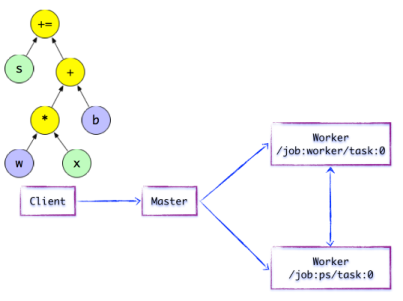
Client是前端系统的主要组成部分,它是一个支持多语言的编程环境。它提供基于计算图的编程模型,方便用户构造各种复杂的计算图,实现各种形式的模型设计。
- 如下图:Client构建了一个简单计算图。它首先将w与x进行矩阵相乘,再与截距b按位相加,最后更新至s。
-
-
Client基于TensorFlow的编程接口,构造计算图。
-
此时,TensorFlow并未执行任何计算。直至建立Session会话,并以Session为桥梁,建立Client与后端运行时的通道,将Protobuf格式的GraphDef发送至Distributed Master。也就是说,当Client对OP结果进行求值时,将触发Distributed Master的计算图的执行过程。
Distributed Master:
-
在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的「最小子图」。
-
然后,Distributed Master负责将该「子图」再次分裂为多个「子图片段」,以便在不同的进程和设备上运行这些「子图片段」。
-
最后,Distributed Master将这些「子图片段」派发给Work Service;随后Work Service启动「子图片段」的执行过程。
-
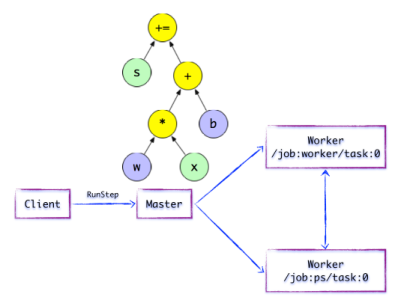
- 如上图所示,Distributed Master开始执行计算子图。在执行之前,Distributed Master会实施一系列优化技术,例如「公共表达式消除」,「常量折叠」等。随后,Distributed Master负责任务集的协同,执行优化后的计算子图。
子片段图:
-
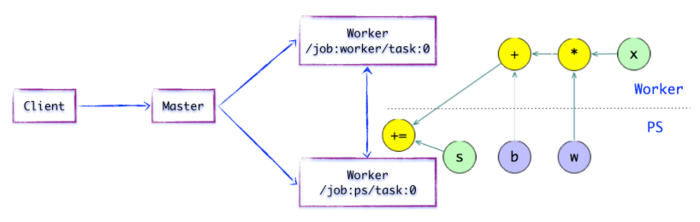
- 如上图所示,存在一种合理的「子图片段」划分算法。Distributed Master将模型参数相关的OP进行分组,并放置在PS任务上。其他OP则划分为另外一组,放置在Worker任务上执行。
SEND/RECV节点:
-
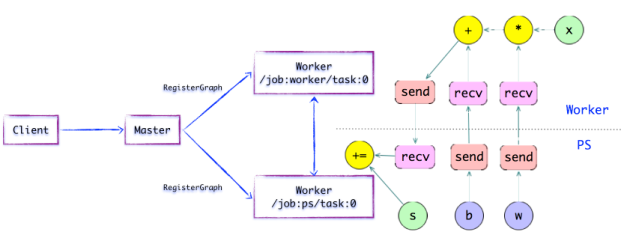
-
如上图所示,如果计算图的边被任务节点分割,Distributed Master将负责将该边进行分裂,在两个分布式任务之间插入SEND和RECV节点,实现数据的传递。
-
随后,Distributed Master将「子图片段」派发给相应的任务中执行,在Worker Service成为「本地子图」,它负责执行该子图的上的OP。
Worker Service:
-
对于每个任务,都将存在相应的Worker Service,它主要负责如下3个方面的职责:
- [li]处理来自Master的请求;
- 调度OP的Kernel实现,执行本地子图;
- 协同任务之间的数据通信。
-
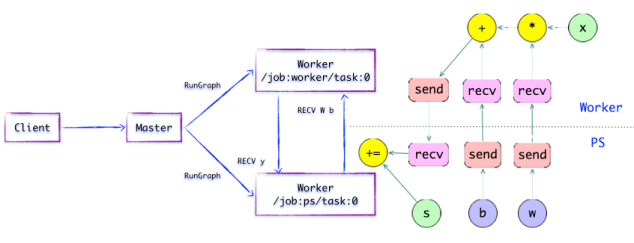
-
Worker Service派发OP到本地设备,执行Kernel的特定实现。它将尽最大可能地利用多CPU/GPU的处理能力,并发地执行Kernel实现。
-
另外,TensorFlow根据设备类型,对于设备间的SEND/RECV节点进行特化实现:
-
[li]
使用cudaMemcpyAsync的API实现本地CPU与GPU设备的数据传输;
-
对于本地的GPU之间则使用端到端的DMA,避免了跨host CPU昂贵的拷贝过程。
-
对于任务之间的数据传递,TensorFlow支持多协议,主要包括:
-
[li]
gRPC over TCP
-
RDMA over Converged Ethernet
主流框架对比
-
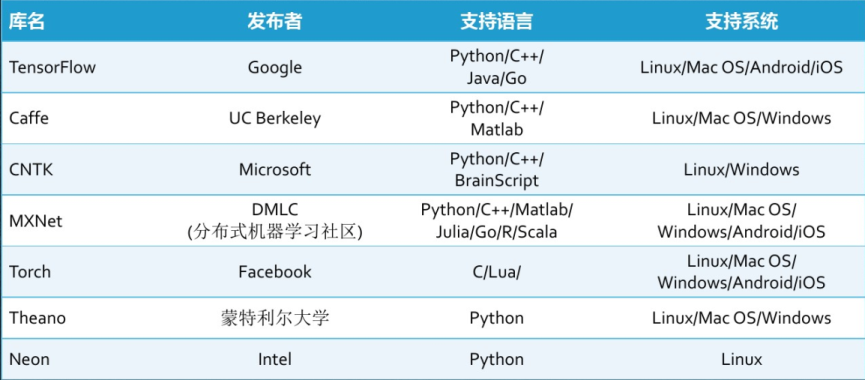
- 对比
-
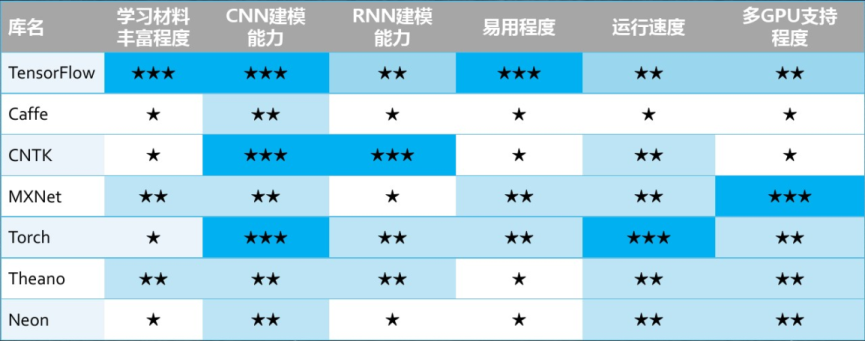
- 社区
-

参考资料:
- https://www.jianshu.com/p/17f368f47de0
- https://www.geek-share.com/detail/2729060843.html
- https://www.leiphone.com/news/201702/n0uj58iHaNpW9RJG.html?viewType=weixin
- http://nooverfit.com/wp/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3tensorflow%E6%A1%86%E6%9E%B6%EF%BC%8C%E7%BC%96%E7%A8%8B%E5%8E%9F%E7%90%86-%E7%AC%AC%E4%B8%80%E8%AE%B2/
- http://blog.chinaunix.net/uid-31460252-id-5769406.html
- https://www.geek-share.com/detail/2696057454.html

- EIGRP基础理论
- ERP之现代物流管理基础理论(1)
- 1.LVS理论基础
- SpringMVC理论基础
- MySQL 基础理论面试题整理
- iptable基础理论和基本使用(1)
- Android系统理论基础
- jQuery的理论基础
- 【SLAM】(二)Cartographer的原理探究——GraphSLAM理论基础
- TCP/IP理论基础
- Mysql数据库理论基础之三 --- 数据类型及SQL结构化查询语句使用
- [置顶] 《机器学习实战》学习笔记(五)之支持向量机(上)基础理论及算法推导
- 算法的性能度量基础理论
- 理论: 二分查找(1):基础样例
- 直销的理论基础一----几何倍增学
- C#函数式程序设计初探——基础理论篇
- 对软件测试的认识(理论基础知识)
- 渲染基础理论的介绍(1)
- orbslam2-基础理论(五)ransac
- 图片理论基础