Standalone-Client提交任务方式下-Spark程序运行架构图
Spark程序运行架构图
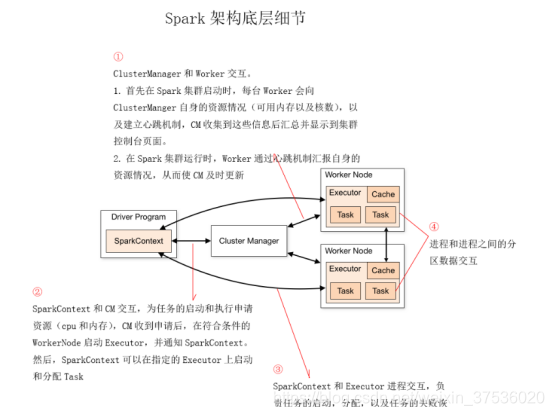
一个Spark程序的运行由Driver Program、SparkContext对象、WorkNode、Work进程、Executor执行器、Task任务和Cluster Manager集群管理器七个组件协同工作。可以把Cluster Manager看作Master结点

-
Driver Program
用户编写的Spark程序称为Driver Program。每个Driver程序包含一个代表运行环境的SparkContext对象。程序的执行从Driver程序开始,所有操作执行结束后回到Driver程序中。
-
SparkContext对象
①每个Driver Program里都有一个SparkContext对象
SparkContext对象联系 cluster manager(集群管理器),从 cluster manager申请任务执行需要的内存和CPU资源;
②和Executor进程交互,完成任务的启动、分配和监控
-
Worker Node
集群上的计算节点,对应一台物理机器
-
Worker进程
①用于和cluster manager进程交互,向cluster manager注册和汇报自身节点的资源使用情况
②管理和启动Executor进程
-
Executor执行器
一个JVM进程,用于运行和计算Task,并将计算结果回传到Driver中
-
Task任务
执行器上执行的最小单元。比如RDD Transformation操作时对RDD内每个分区的计算都会对应一个Task。它会被SparkContxt送到某个Executor上去执行
-
cluster manager 集群管理器
对应Master进程, 接收Driver的资源申请,从收集的资源池中,寻找满足资源条件的worker结点,并告诉Driver,哪台worker结点可以执行当前任务
程序运行调度图
-
SparkContext的调度
Sc的任务调度主要分为DAGScheduler 和 TaskScheduler
调度过程,如下图:
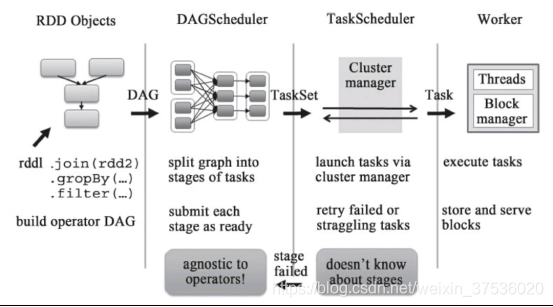
RDD Objects可以理解为用户实际代码中创建的RDD,这些代码逻辑上组成了一个DAG。
DAGScheduler主要负责分析依赖关系,然后将DAG划分为不同的Stage(阶段),其中每个Stage由可以并发执行的一组Task构成
TaskScheduler从DAGScheduler接收Task任务,向cluster Manager 申请资源。集群管理器收到申请后,在集群中寻找满足资源的Worker Node,并启动专属的Executor;
SchedulerBackend与Executor交互,完成Task任务的分配和资源调度,并将结果回传到Driver
-
Spark任务调度代码实现细节
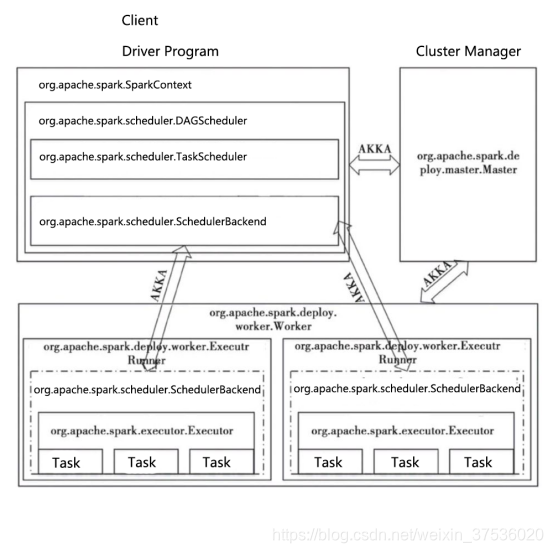
org.apache.spark.scheduler.DAGScheduler
将一个DAG划分为一个一个的Stage阶段(每个Stage是一组Task的集合)
然后把Task Set 交给TaskScheduler模块。
org.apache.spark.scheduler.TaskScheduler
从DAGScheduler接收不同Stage的任务。向Cluster Manager 申请资源。然后Cluster Manager收到资源请求之后,寻找符合条件的Worker,并在该Worker上启动Executor
org.apache.spark.scheduler.SchedulerBackend
向当前等待分配计算资源的Task分配Executor,并且在分配的Executor上启动Task,完成计算的资源调度
AKKA
一个网络通信框架,类似于Netty,在Spark1.8之后已全部替换成Netty

- Spark on yarn--几种提交集群运行spark程序的方式
- spark-submit提交任务的方式
- win10下将spark的程序提交给远程集群中运行
- Spark学习之第一个程序打包、提交任务到集群
- Spark(五)Spark任务提交方式和执行流程
- 在Eclipse上运行Spark(Standalone,Yarn-Client)
- yarn架构 及 client提交任务过程讲解
- 27课 :SPARK 运行在yarn资源调度框架 client 、cluster方式 !!
- Spark的环境搭建以及简单的eclipse的两种运行方式--standalone和yarn
- 编写Spark程序并提交到集群上运行
- Spark任务提交方式和执行流程
- spark 的俩种 任务提交方式
- Spark通过YARN提交任务不成功(包含YARN cluster和YARN client)
- 使用linux提交pbs任务:运行matlab或perl程序
- spark源码解析-从提交任务到jar的加载运行(基于2.1.0版本)
- 用oozie命令行的方式在yarn上运行spark任务
- spark用程序提交任务到yarn Spark自定义分区(Partitioner) textfile使用小技巧 createDirectStream
- spark-2.0.0提交jar任务的几种方式
- Spark任务提交方式和执行流程
- Spark基本术语表+基本架构+基本提交运行模式