Spark - Resilient Distributed Datasets (RDDs)介绍
什么是RDD
Resilient Distributed DataSets,弹性分布式数据集,可以把RDD看作是一种集合类型。
Scala中的集合类型,比如Array、List都可以通过RDD的赖加载函数转换成RDD类型。
我们可以把RDD理解成:它是spark提供的一个特殊集合类。诸如普通的集合类型,如传统的Array:(1,2,3,4,5)是一个整体,但转换成RDD后,我们可以对数据进行Partition(分区)处理,这样做的目的就是为了分布式计算。另外Spark中的RDD除具有分区机制(可以并行的处理RDD数据)外,还具有容错机制(即数据丢失,可以恢复)
Shell模式下如何创建RDD
首先Shell客户端启动Spark,以单机模式启动为例: sh spark-shell --master local

注意日志中的sc为Spark的上下文起的别名
http://yangjjhost:4040 为可视化管理台地址
Array、List普通集合类型,通过sc.parallelize转变为RDD

将Array、List普通集合类型,通过sc.makeRDD转变为RDD

从本地磁盘读取数据文件,转变为RDD

从分布式文件系统HDFS读取数据文件,转变为RDD

RDD提供的函数
RDD的Transformation(变换)操作属于懒操作(算子),不会真正触发RDD的处理计算。Actions(执行)操作才会真正触发。
Transformation操作提供的懒加载函数
- map(func):
参数是函数,函数应用于RDD每一个元素,每个输入项只能映射到一个输出项,返回值是新的RDD
- flatMap(func):
参数是函数,函数应用于RDD每一个元素,每个输入项可以映射到0个或更多的输出项,返回值是新的RDD
- filter(func):
参数是函数,函数应用于RDD的每一个元素,会过滤掉不符合条件的元素,返回值是新的RDD
- mapPartitions(func):
参数是函数,函数应用于RDD的每一个分区迭代器,返回MapPartitionsRDD
scala> val r3 = sc.makeRDD(List(9,8,7,3,2,1,5,4,6,0),3)
r3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:24

- mapPartitionsWithIndex(func):
作用同mapPartitions,不过提供了两个参数,第一个参数为分区的索引

- union(otherDataset):
并集 -- 也可以用++实现
- intersection(otherDataset):
交集 -- 也可以用&实现
- subtract(otherDataset):
差集-也可以用&~实现
- Distinct:
没有参数,将RDD里的元素进行去重操作
- groupByKey([numTasks]):
groupByKey对于数据格式是有要求的,即操作的元素必须是一个二元tuple,
tuple._1 是key, tuple._2是value。

- reduceByKey(func, [numTasks]) 统计单词频次

- sortByKey([ascending], [numTasks]):

- join(otherDataset, [numTasks]):按相同Key合并值

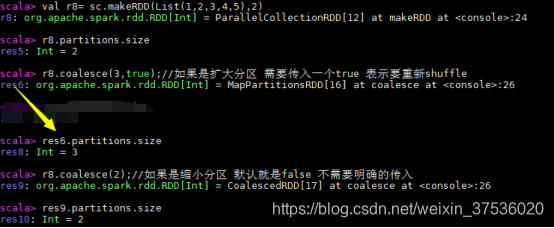
- coalesce(numPartitions):扩大或缩小分区
Actions操作提供的函数
- reduce(func):并行整合所有RDD数据,例如求和操作
- collect():返回RDD所有元素,将rdd分布式存储在集群中不同分区的数据 ,收集到一台机器上,组成一个数组返回。
- count():统计RDD里元素个数
- first():类似于take(1)
- take(n):获取前几个数据
- takeOrdered(n, [ordering]): 先将rdd中的数据进行升序排序 然后取前n个
- top(n):先将rdd中的数据进行降序排序 然后取前n个
- countByKey():只在类型(K, V)的RDD上可用。返回(K, Int)对的hashmap,并记录每个键的计数。
- foreach(func):对数据集的每个元素运行函数
- saveAsTextFile(path): 按照文本方式保存分区数据

scala> r8.savaAsTextFile("hdfs://yangjjhost:9000/sparkdata")

- spark 笔记 2: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
- spark学习笔记:Resilient Distributed Datasets
- Apache Spark 2.2.0 中文文档 - Spark RDD(Resilient Distributed Datasets)论文 | ApacheCN
- Apache Spark RDD(Resilient Distributed Datasets)论文
- Spark学习笔记10-RDD(Resilient Distributed Datasets)
- Spark的核心RDD(Resilient Distributed Datasets弹性分布式数据集)
- Apache Spark 2.2.0 中文文档 - Spark RDD(Resilient Distributed Datasets)论文 | ApacheCN
- 浅谈对于RDD的认识 RDD(Resilient Distributed Datasets)弹性分布式数据集,是在集群应用中分享数据的一种高效,通用,容错的抽象,是Spark提供的最重要的抽象的概念
- Apache Spark APIs 的三剑客,RDDs, DataFrames, and Datasets
- Spark Datasets介绍
- 理解Spark - RDD(Resilient Distriuted Datasets)
- Scala当中什么是RDD(Resilient Distributed Datasets)弹性分布式数据集
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
- JX8NET 教你用 Spark Resilient Distributed Dataset
- Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
- Spark RDD(Resilient Distributed Datasets)论文 | ApacheCN
- 一步一步学习openfire+spark(2)——介绍几个概念
- Spark Streaming基本使用介绍
- Spark介绍
- Spark 介绍(基于内存计算的大数据并行计算框架)