Spark基本术语表+基本架构+基本提交运行模式
2017-10-25 17:20
381 查看
一、Spark基本术语表
转载自:http://blog.csdn.net/simple_the_best/article/details/70843756以下内容来自 http://spark.apache.org/docs/2.1.0/cluster-overview.html#glossary ,
需要对 spark 的整个运行过程有所了解才能真正理解这些术语的涵义.
可以先看一下 http://dblab.xmu.edu.cn/blog/972-2 了解一下概况.
| 术语 | 术语简译 | 涵义 |
|---|---|---|
| application | 应用 | 基于 Spark 构建的用户程序. 一般包括了集群上的一个 driver 程序与多个 executor |
| application jar | 应用的 jar 包 | 包含了用户的 Spark application 的一个 jar 包. 在某些情况下用户可能想要创建一个囊括了应用及其依赖的 “超级” jar 包. 但实际上, 用户的 jar 不应该包括 Hadoop 或是 Spark 的库, 这些库会在运行时被进行加载. |
| driver program | 驱动程序 | 运行 application 的 main() 函数和创建 SparkContext 的进程. |
| cluster manager | 集群管理器 | 获取集群资源的一个外部服务, 比如 standalone 管理器, Mesos 和 YARN. |
| deploy mode | 部署模式 | 区分 driver 进程在何处运行. 在 “cluster” 模式下, 框架在集群内部运行 driver. 在 “client” 模式下, 提交者在集群外部运行 driver. |
| worker node | 工作节点 | 集群内任一能够运行 application 代码的节点 |
| executor | 执行者 | 在 worker node 上 application 启动的一个进程, 该进程运行 task 并在内存或磁盘上保存数据. 每个 application 都有其独有的 executor. |
| task | 任务 | 发送到一个 executor 的一系列工作 |
| job | 作业 | 由多个 task 组成的一个并行计算, 这些 task 产生自一个 Spark action (比如, save, collect) 操作. 在 driver 的日志中可以看到 job 这个术语. |
| stage | 阶段 | 每个 job 被分解为多个 stage, 每个 stage 其实就是一些 task 的集合, 这些 stage 之间相互依赖 (与 MapReduce 中的 map 与 reduce stage 类似). 在 driver 的日志中可以看到 stage 这个术语. |
Spark
内部术语解释
Application:基于 Spark 的用户程序,包含了 driver 程序和集群上的 executor;Driver Program:运行 main 函数并且新建 SparkContext 的程序;
Cluster Manager:在集群上获取资源的外部服务 (例如:standalone,Mesos,Yarn);
Worker Node:集群中任何可以运行应用代码的节点;
Executor:是在一个 worker node 上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应用都有各自独立的 executors;
Task:被送到某个 executor 上的工作单元;
Job:包含很多任务的并行计算,可以与 Spark 的 action 对应;
Stage:一个 Job 会被拆分很多组任务,每组任务被称为 Stage(就像 Mapreduce 分 map 任务和 reduce 任务一样)。
二、Spark基本架构

Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:一是利用多线程来执行具体的任务(Hadoop MapReduce采用的是进程模型),减少任务的启动开销;二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到HDFS等文件系统里,因而有效减少了IO开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写IO性能。
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster
Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
三、Spark基本提交(submit)运行模式
1、client mode(本地模式)
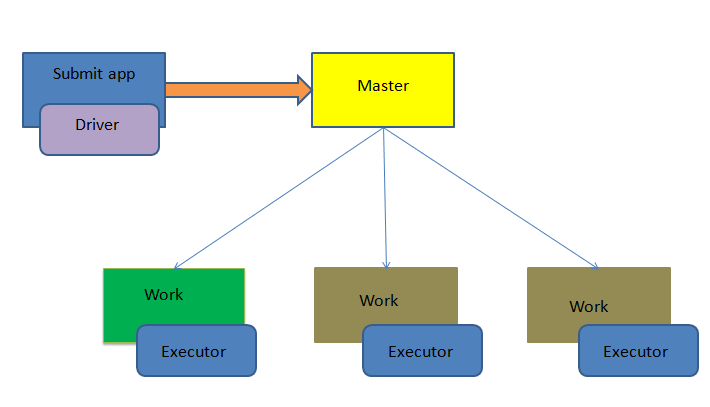
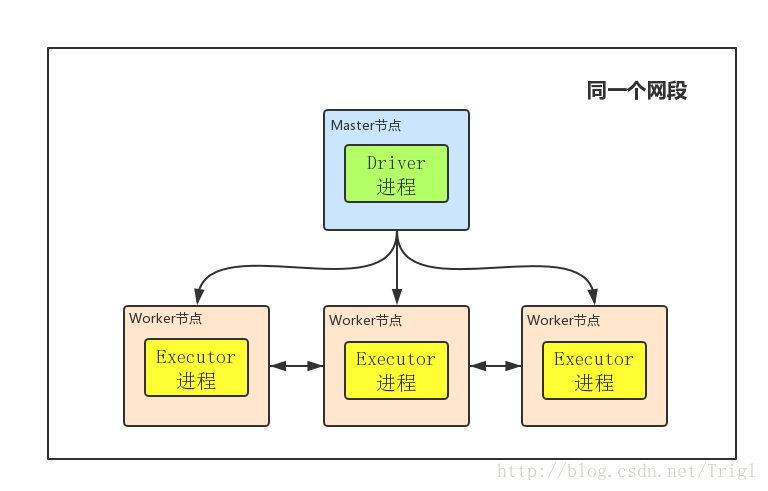
首先明白几个基本概念:Master节点就是你用来提交任务,即执行bin/spark-submit命令所在的那个节点;Driver进程就是开始执行你Spark程序的那个Main函数,虽然这里边画的Driver进程在Master节点上,但注意Driver进程不一定在Master节点上,它可以在任何节点;Worker就是Slave节点,Executor进程必然在Worker节点上,用来进行实际的计算
①client mode下Driver进程运行在Master节点上,不在Worker节点上,所以相对于参与实际计算的Worker集群而言,Driver就相当于是一个第三方的“client”
②正由于Driver进程不在Worker节点上,所以其是独立的,不会消耗Worker集群的资源
③client mode下Master和Worker节点必须处于同一片局域网内,因为Drive要和Executorr通信,例如Drive需要将Jar包通过Netty HTTP分发到Executor,Driver要给Executor分配任务等
④client mode下没有监督重启机制,Driver进程如果挂了,需要额外的程序重启。
2、cluster mode(集群模式)
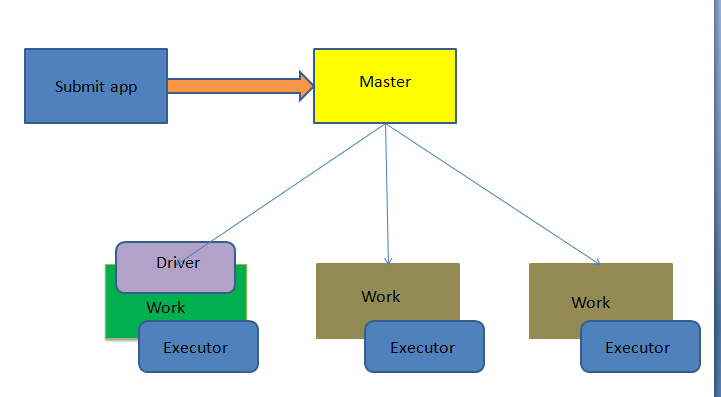
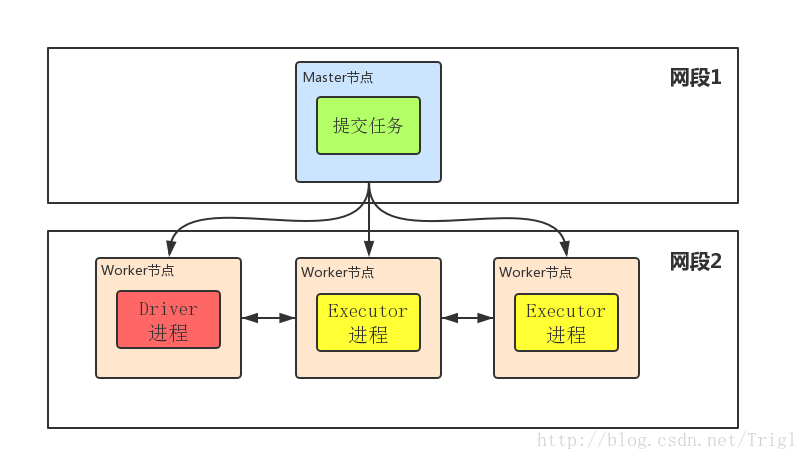
①Driver程序在worker集群中某个节点,而非Master节点,但是这个节点由Master指定
②Driver程序占据Worker的资源
③cluster mode下Master可以使用–supervise对Driver进行监控,如果Driver挂了可以自动重启
④cluster mode下Master节点和Worker节点一般不在同一局域网,因此就无法将Jar包分发到各个Worker,所以cluster mode要求必须提前把Jar包放到各个Worker几点对应的目录下面。

相关文章推荐
- Spark1.0.0 运行架构基本概念
- Spark1.0.0 运行架构基本概念
- Spark1.0.0 运行架构基本概念
- Spark2.x学习笔记:4、Spark程序架构与运行模式
- Spark的运行架构分析(二)之运行模式详解
- Spark1.0.0 运行架构基本概念
- Intellij IDEA开发(local模式)提交运行Spark代码
- 转:Spark的运行架构分析(二)之运行模式详解
- Spark1.0.0 运行架构基本概念
- 【Spark深入学习-11】Spark基本概念和运行模式
- Spark的运行架构分析(二)之运行模式详解
- IDEA【基本配置1】配置SBT 和 scala 并在spark环境中进行wordcount测试(spark集群运行模式)
- spark运行模式及集群架构
- Spark开发-运行架构基本概念
- Spark入门实战系列--4.Spark运行架构
- Spark运行架构-简要版
- Spark(一): 基本架构及原理
- 地球气候系统模式cesm的基本运行流程
- Spark简述及基本架构
- spark 提交jar包到集群运行报异常 java.net.UnknownHostException: mycluster