python爬虫——爬取b站APP视频信息(通过fiddler抓包工具)
2019-04-16 20:35
387 查看
版权声明:转载需注明来源 https://blog.csdn.net/weixin_44024393/article/details/89341389
1. 先看效果图,随便抓的信息
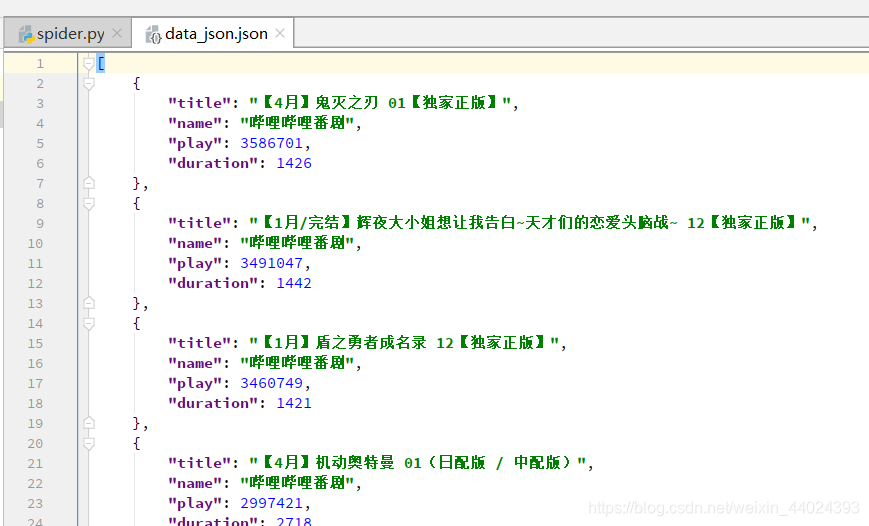
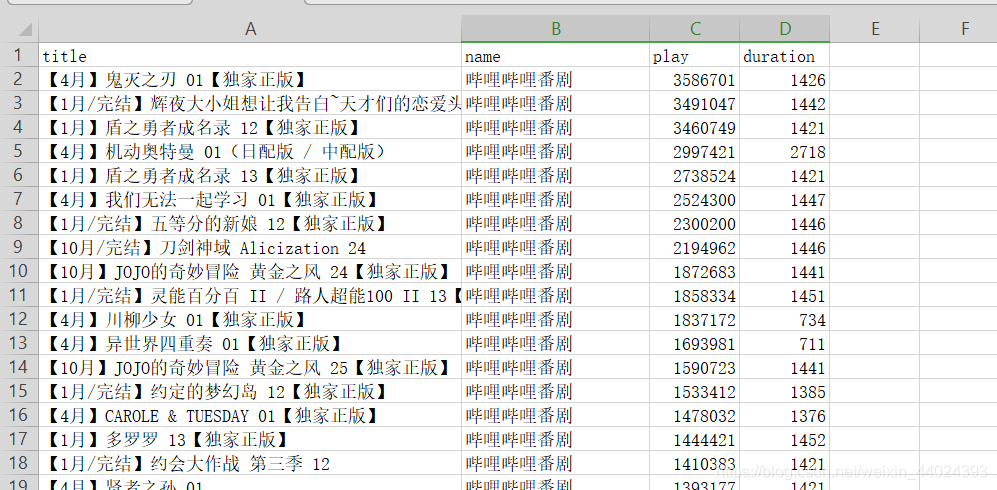
2. 解析 ,fiddler抓包工具的配置大家自己百度吧,教程都很详细
3. 打开fiddler和模拟器,在模拟器打开哔哩哔哩软件,fiddler我是通过查找分析之后之后过滤的域名

4. 我们通过打开b站的相应版块,然后进行往下翻页之后,fiddler就会根据我之前选择过滤的域名给我标黑
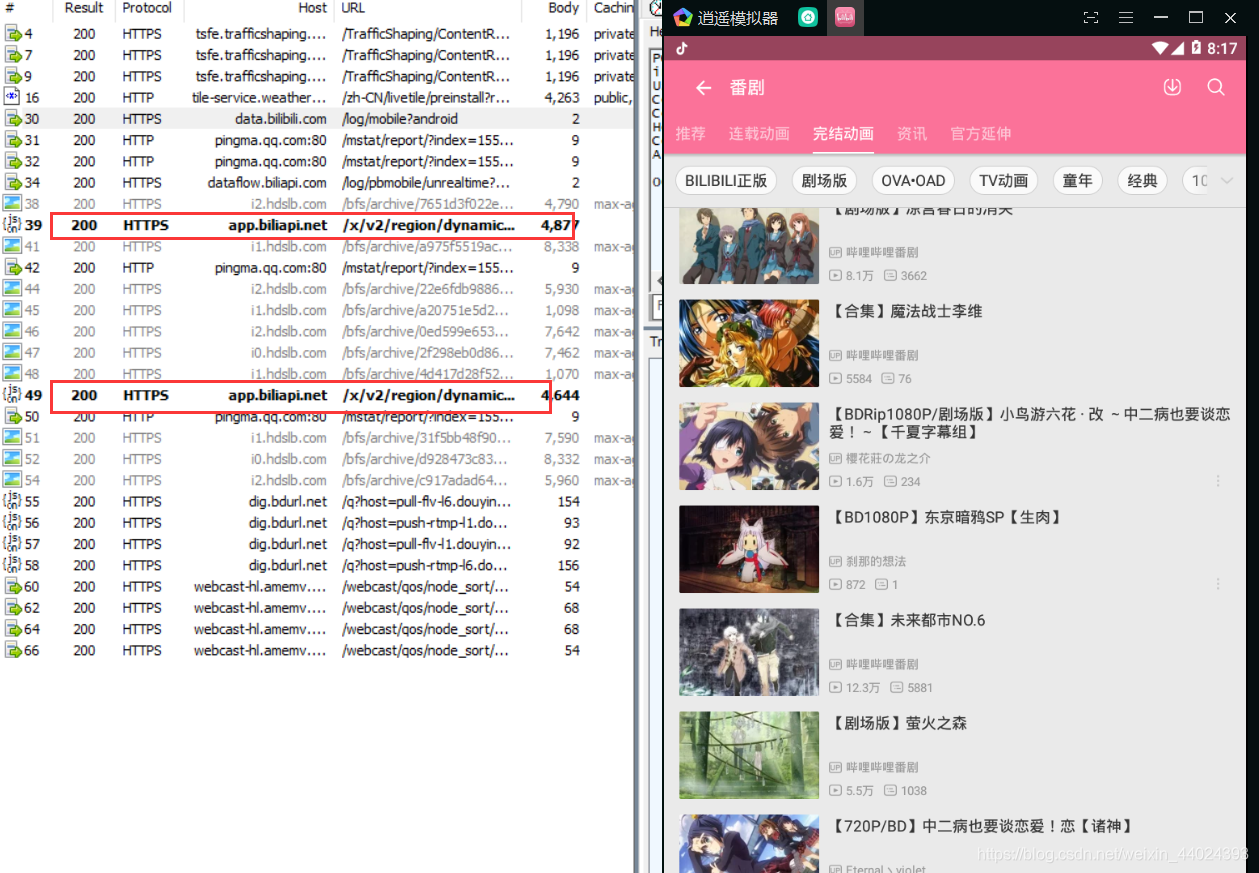
5. 我们点开其中一条标黑的url,然后和b站软件的进行对比,发现我们需要的信息都可以抓取出来
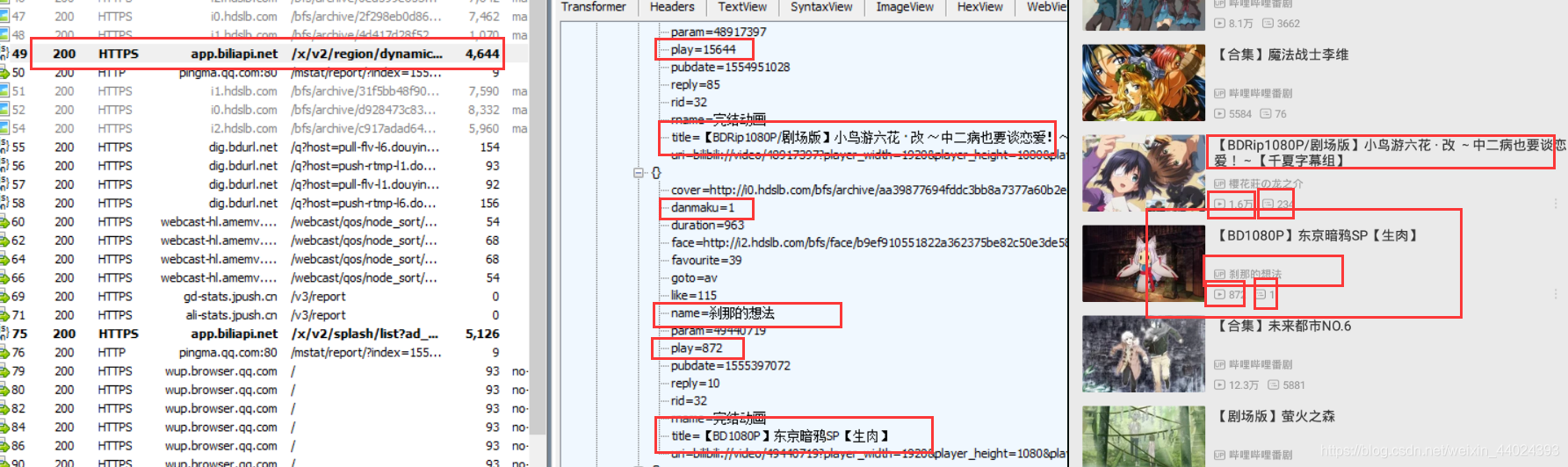
6. 我们可以通过这两条url的对比,查找出不同的地方,经过我的测试,pn代表的是页码,后面红框打叉的地方我们可以不要,这样我们就可以实现翻页了

7. 需要注意的是我们需要无视ssl安全证书,也就是在requests那里加一个verify=False,这个很重要,不加的话就访问不了url的,返回的数据是json格式,所以大家都懂怎么操作了

8. 大家想要什么数据自己去找,当然其中的数据代表什么也需要大家自己去想了
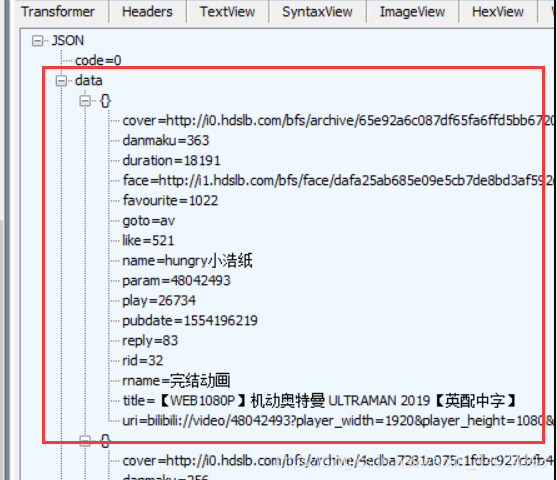
9. 再说一下,翻页到什么时候就到底了呢,通过观察我发现,当到底部的时候,json数据里面的data为空,所以我们只要判断json里面的data是否为空做为判断是否到达底部

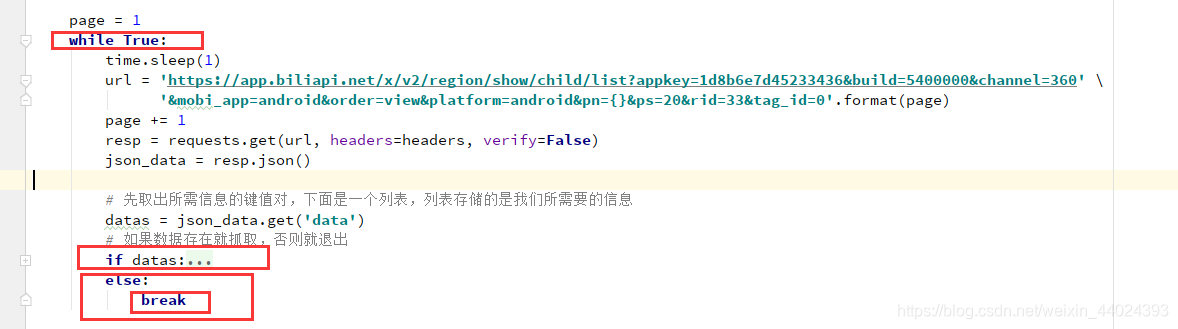
10. 完整代码附上
import requests
import json
import csv
import time
# 构建请求头
headers = {
# 'Buvid': 'XZ512D1509193D98B13705F88F4266CFF9B32',
'User-Agent': 'Mozilla/5.0 BiliDroid/5.40.0 (bbcallen@gmail.com)',
# 'Device-ID': 'Lk16QnVEfRt_TnxEOEQ4DDgNPQw9Dzo',
'Host': 'app.biliapi.net',
'Connection': 'Keep-Alive',
# 'Accept-Encoding': 'gzip',
}
# 声明一个列表存储字典
data_list = []
def start_spider():
page = 1
while True:
time.sleep(1)
url = 'https://app.biliapi.net/x/v2/region/show/child/list?appkey=1d8b6e7d45233436&build=5400000&channel=360' \
'&mobi_app=android&order=view&platform=android&pn={}&ps=20&rid=33&tag_id=0'.format(page)
page += 1
resp = requests.get(url, headers=headers, verify=False)
json_data = resp.json()
# 先取出所需信息的键值对,下面是一个列表,列表存储的是我们所需要的信息
datas = json_data.get('data')
# 如果数据存在就抓取,否则就退出
if datas:
# 遍历
for data in datas:
# 标题
title = data.get('title')
# up主名字
name = data.get('name')
# 播放数
play = data.get('play')
# 评论数
duration = data.get('duration')
# 声明一个字典存储数据
data_json = {}
data_json['title'] = title
data_json['name'] = name
data_json['play'] = play
data_json['duration'] = duration
data_list.append(data_json)
print(data_json)
else:
break
def main():
start_spider()
# 将数据写json文件
with open('data_json.json', 'a+', encoding='utf-8-sig') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件写入完成')
# 将数据写入csv文件
with open('data_csv.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer对象
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
if __name__ == '__main__':
main()

相关文章推荐
- 12Python爬虫---Fiddler抓包工具使用
- 【python爬虫】抓取B站视频相关信息(一)
- Fiddler抓包---手机APP--python爬虫 基本设置和操作
- 【python爬虫】抓取B站视频数据及相关信息(二)
- Python爬虫-02:HTTPS请求与响应,以及抓包工具Fiddler的使用
- 【python爬虫】通过python多线程的抓取新浪新闻的标题时间评论信息
- python爬虫8——下载视频:you-get工具
- python爬虫爬取异步加载网页信息(python抓取网页中无法通过网页标签属性抓取的内容)
- 利用Fiddler手机抓包对ONE·APP网页爬虫实现电影资讯微信Java开发
- Fiddler抓包工具-APP
- Python爬取B站视频信息
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
- 非常详细的Fiddler工具使用说明(包含APP抓包)
- 在Mac OS X 通过抓包、“第三方下载工具”加速下载、安装APP或系统
- 「docker实战篇」python的docker爬虫技术-fiddler分析app抓取(12)
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第二篇)
- Python爬虫入门教程 51-100 Python3爬虫通过m3u8文件下载ts视频-Python爬虫6操作
- J哥---------分享好东西:android抓包工具fiddler使用介绍 抓取 手机APP 中资源。
- 分享好东西:android抓包工具fiddler使用介绍 抓取 手机APP 中资源。
- Android中app的请求抓包工具 Fiddler 详解