python爬虫——如何爬取ajax网页之爬取雪球网文章
2019-04-28 13:01
513 查看
版权声明:转载需注明来源 https://blog.csdn.net/weixin_44024393/article/details/89636023
-
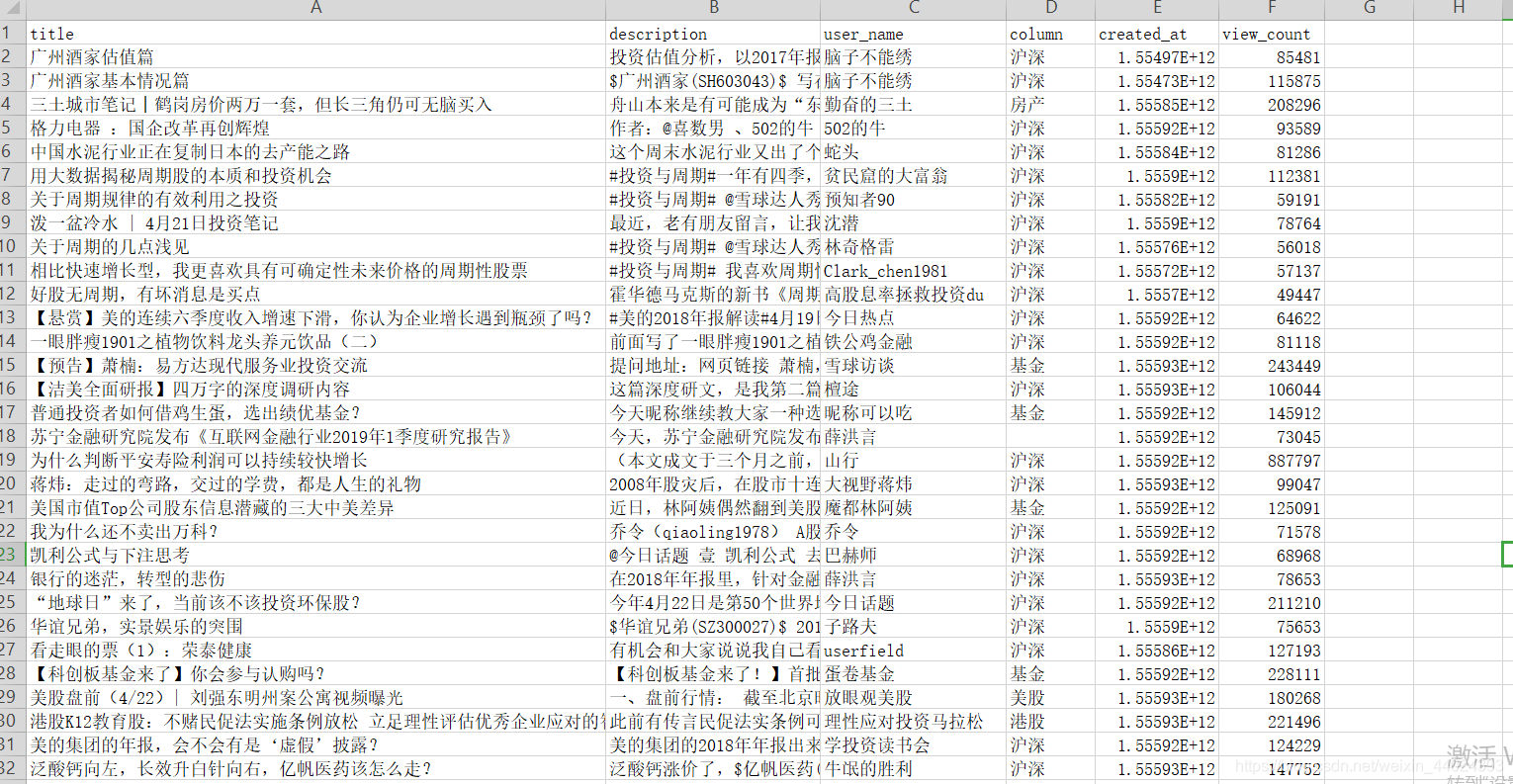
效果图
-
传送门点击传送门
-
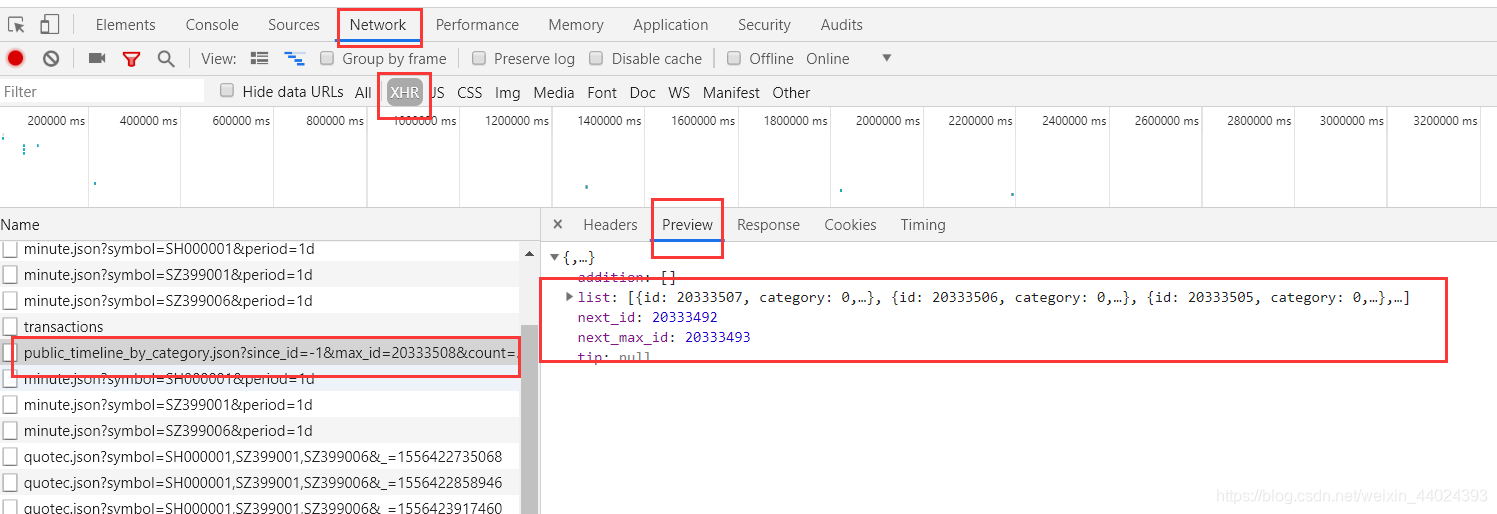
进入网站之后我们打开开发工具之后,往下滑时会出现一个接口(当然滑的越多接口越多)
-
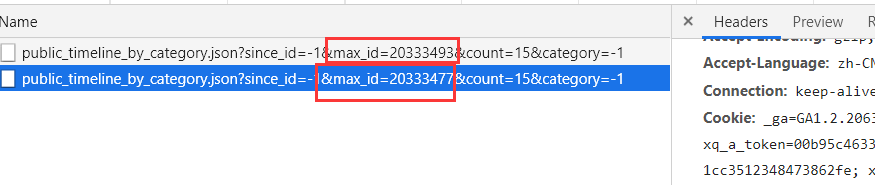
我们通过对比两个及以上的接口进行分析它们的不同之处(这叫找规律)
可以发现max_id是在变化的,其他都是不变的,而且count是返回的文章数目有15个,所以max_id只要自增15就可以实现翻页了,是不是很简单
-
我们可以这么写代码实现翻页(这代码只是举例子怎么写翻页,不代表最终的代码),这里我取max_id开始的地方是20333000(小伙伴们可以自己去找一下max_id的有效范围),如下
max_id = 20333000
while True:
# 请求的url
url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id={}&count=15&category=-1'.format(max_id)
# 返回来的数据是json格式
resp = requests.get(url, headers=headers).json()
max_id += 15
- 接下来分析一下返回来的数据,以便我们进行抓取,通过下图我们可以发现每一篇文章都是存储在列表这个键当中的,所以我们先取出list这个键
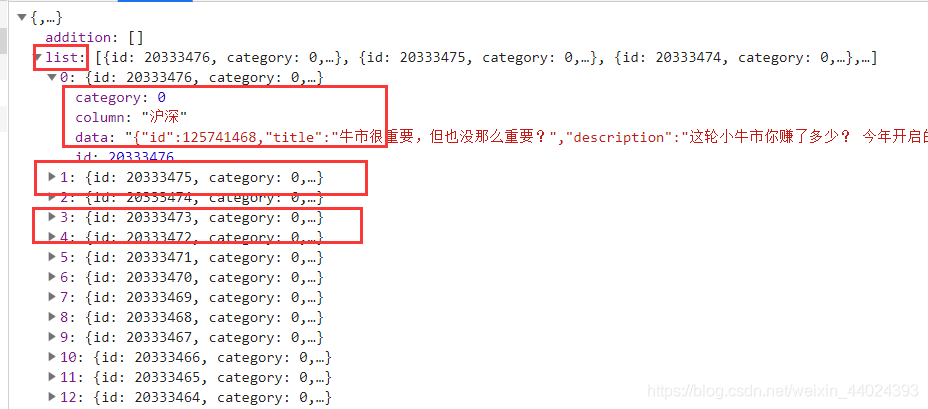
代码如下:
# 我们需要的数据存在一个列表之中,先取出这个列表
lists = resp.get('list')
- 再看每一篇文章的信息,将data的信息复制粘贴到json.cn这个网站去查看json的信息,可以发在data中取出我们需要的信息
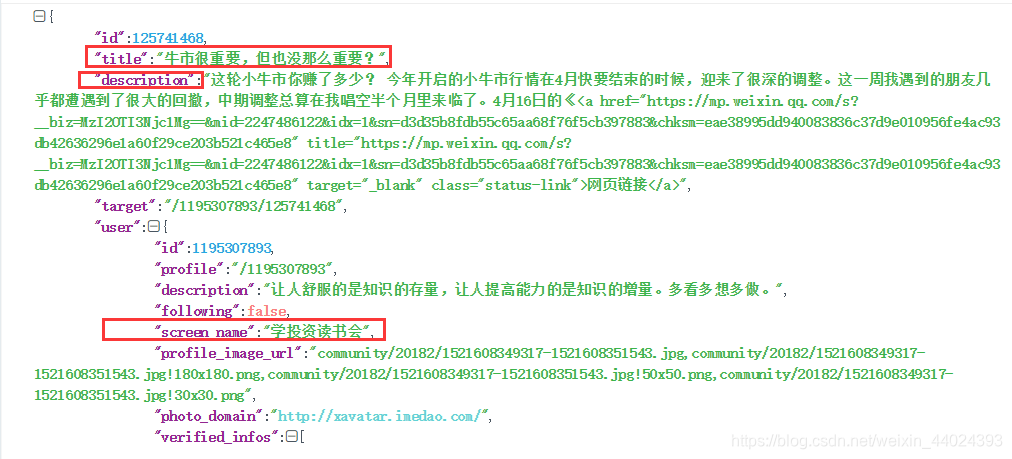
for temp in lists:
# 数据在每一个元素中的data键中,取出data
data = temp.get('data')
# 取出来的data是一个str类型,我们需要将其转换成dict的类型方可操作
data = json.loads(data)
# 判断data是否存在
if data:
# 获取文章的题目
title = data.get('title')
# 如果没有题目,就continue,因为通过我的观察,没有title的一般是广告之类的
if not title:
continue
# 获取摘要
description = data.get('description')
# 数据清洗,使用正则表达式的sub方法
description = re.sub(r'<a.*?>|</a>|<img.*?/>', '', description)
# 获取用户的信息,用户的信息在data里边的user键中
user_name = data.get('user').get('screen_name')
# 获取是什么类型的文章
column = temp.get('column')
# 获取发表的时间戳
created_at = data.get('created_at')
# 获取阅读人数
view_count = data.get('view_count')
# 声明一个字典存储数据
data_dict = {}
data_dict['title'] = title
data_dict['description'] = description
data_dict['user_name'] = user_name
data_dict['column'] = column
data_dict['created_at'] = created_at
data_dict['view_count'] = view_count
print(data_dict)
- 最后就是将数据保存到文件中,其中data_list是我在前面一开始就声明的了
# 将数据写入json文件
with open('data_json.json', 'a+', encoding='utf-8-sig') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件写入完成')
# 将数据写入csv文件
with open('data_csv.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
- 完整代码附上,记得要设置延迟噢,我们是一只文明的爬虫~~~
(忘了说了,cookie会过期,需要及时更新cookie)
import requests
import json
import csv
import re
import time
# 构建请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'Cookie': '_ga=GA1.2.2063358900.1556201729; device_id=6d3728c68639d27b0fa92464193777de; aliyungf_tc=AQAAAHOchwegLwsA1isrcGvAfZFXtOkL; xq_a_token=00b95c4633c43046f85b3a7b2a2956be42f6d389; xq_a_token.sig=MDZUHkBzCj9ftXUmZOXkubKQpEY; xq_r_token=f65e4a63ac53b23a3cea151cc3512348473862fe; xq_r_token.sig=leaWaFTPqUYvoGQEw23wvaagwmc; _gid=GA1.2.1611213571.1556421100; u=971556421100822; Hm_lvt_1db88642e346389874251b5a1eded6e3=1556202024,1556289894,1556421101,1556421135; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1556421135'
}
# 声明一个全局列表存储字典
data_list = []
def get_index(max_id):
# 请求的url
url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id={}&count=15&category=-1'.format(max_id)
# 返回来的数据是json格式
resp = requests.get(url, headers=headers).json()
if resp:
return resp
else:
return None
def start_spider(resp):
# 判断数据是否存在
if resp:
# 我们需要的数据存在一个列表之中,先取出这个列表
lists = resp.get('list')# 判断列表是否存在,然后遍历
if lists:
for temp in lists:
# 数据在每一个元素中的data键中,取出data
data = temp.get('data')
# 取出来的data是一个str类型,我们需要将其转换成dict的类型方可操作
data = json.loads(data)
# 判断data是否存在
if data:
# 获取文章的题目
title = data.get('title')
# 如果没有题目,就continue,因为通过我的观察,没有title的一般是广告之类的
if not title:
continue
# 获取摘要
description = data.get('description')
# 数据清洗,使用正则表达式的sub方法
description = re.sub(r'<a.*?>|</a>|<img.*?/>', '', description)
# 获取用户的信息,用户的信息在data里边的user键中
user_name = data.get('user').get('screen_name')
# 获取是什么类型的文章
column = temp.get('column')
# 获取发表的时间戳
created_at = data.get('created_at')
# 获取阅读人数
view_count = data.get('view_count')
# 声明一个字典存储数据
data_dict = {}
data_dict['title'] = title
data_dict['description'] = description
data_dict['user_name'] = user_name
data_dict['column'] = column
data_dict['created_at'] = created_at
data_dict['view_count'] = view_count
# 判断字典数据是否以及存在了列表,相当于是去重,将字典存入列表中
if data_dict not in data_list:
data_list.append(data_dict)
print(data_dict)
# 设置一个flag并返回来判断是否没有数据了
return True
else:
return None
def save_file():
# 将数据写入json文件
with open('data_json.json', 'a+', encoding='utf-8-sig') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件写入完成')
# 将数据写入csv文件
with open('data_csv.csv', 'w', encoding='utf-8-sig', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
def main():
max_id = 20333000
while True:
resp = get_index(max_id)
flag = start_spider(resp)
# 如果需要爬取全部,可以把下面的注释去掉,这里我为了方便就只爬一部分
# if not flag:
# break
# 把上面的注释去掉就把下面的if语句注释
if max_id > 20333100:
break
max_id += 15
time.sleep(1)
save_file()
if __name__ == '__main__':
main()

相关文章推荐
- python python 入门学习之网页数据爬虫cnbeta文章保存
- 【Python3.6爬虫学习记录】(二)使用BeautifulSoup爬取简单静态网页文章
- Python爬虫之处理带Ajax、Js的网页
- Python网络爬虫实训:如何下载韩寒博客文章
- Python爬虫从入门到上瘾(包含如何观察ajax数据源的详细图解)
- 看我如何利用python爬虫爬取freebuf文章
- [python爬虫]如何爬取特定网页的图片
- Python 网络爬虫 004 (编程) 如何编写一个网络爬虫,来下载(或叫:爬取)一个站点里的所有网页
- Python 网络爬虫 004 (编程) 如何编写一个网络爬虫,来下载(或叫:爬取)一个站点里的所有网页
- Python 网络爬虫 005 (编程) 如何编写一个可以 下载(或叫:爬取)一个网页 的网络爬虫
- Python 网络爬虫 005 (编程) 如何编写一个可以 下载(或叫:爬取)一个网页 的网络爬虫
- Python 爬虫文章
- Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
- python爬虫教程(4)-正则表达式解析网页
- 如何用Python,C#等语言去实现抓取静态网页+抓取动态网页+模拟登陆网站
- python 每天如何定时启动爬虫任务(实现方法分享)
- python_windows下PySpider敲的代码在哪里?以及如何重新执行已经完成的爬虫项目
- 如何用 Python 爬取网页制作电子书
- 【python爬虫】利用selenium和Chrome浏览器进行自动化网页搜索与浏览
- Python3 爬虫 1 - 下载网页