python爬虫——使用bs4爬取链家网的房源信息
2019-04-12 14:30
369 查看
版权声明:转载需注明来源 https://blog.csdn.net/weixin_44024393/article/details/89237757
1. 先看效果


2. 进入链家网,这里我选择的是海口市点击跳转到链家网

3. 先看网页的结构,这些房子的信息都在li标签,而li标签再ul标签,所以怎么做大家都懂
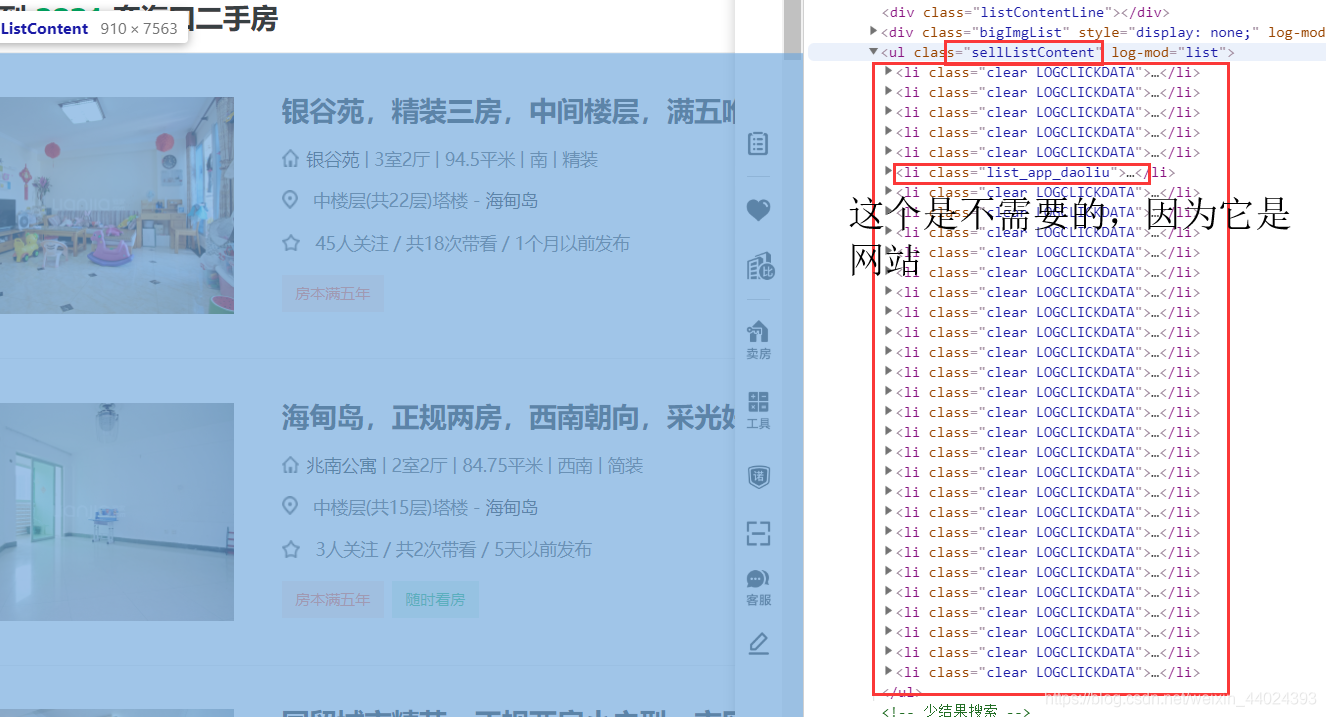
4. 代码如下,url的链接大家可以自己翻页看看就找到规律了,这里就不多说了
url = 'https://hk.lianjia.com/ershoufang/pg{}/'.format(page)
# 请求url
resp = requests.get(url, headers=headers)
# 讲返回体转换成Beautiful
soup = BeautifulSoup(resp.content, 'lxml')
# 筛选全部的li标签
sellListContent = soup.select('.sellListContent li.LOGCLICKDATA')
5. 再看看我们需要提取信息的结构
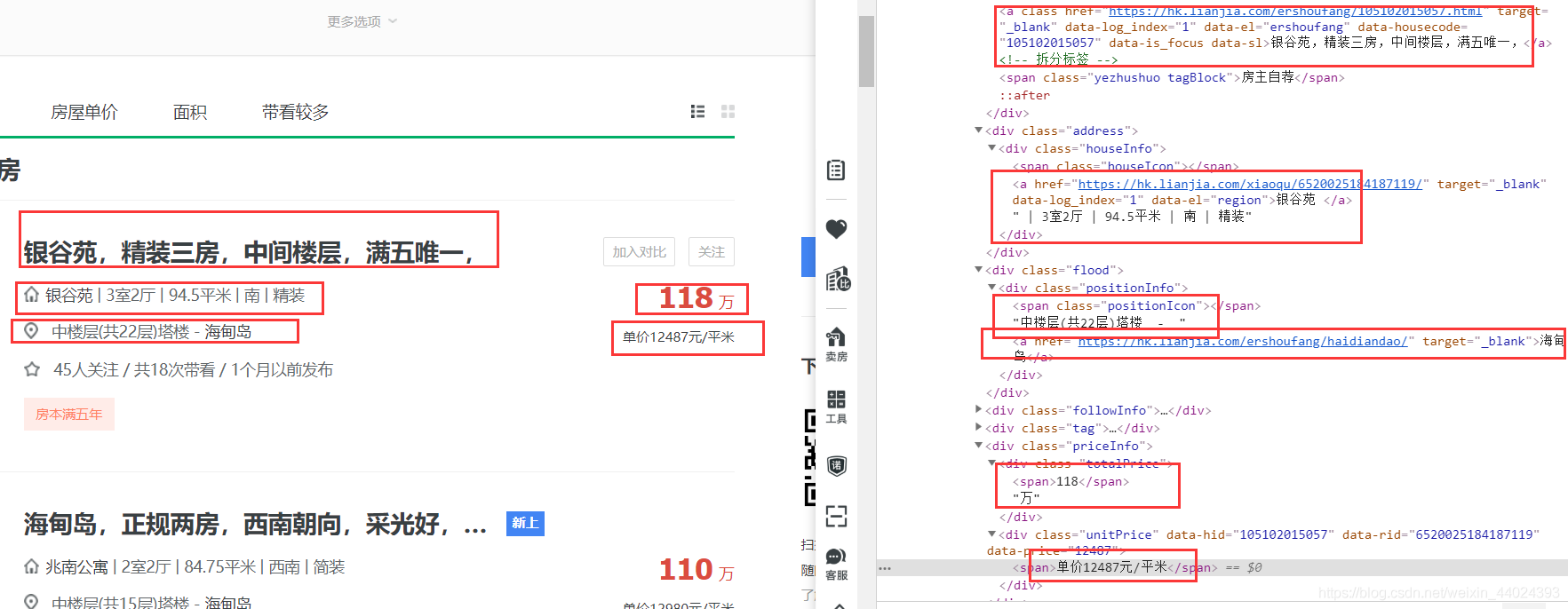
6. 代码附上,其中会做一些数据清洗,大家爬的时候就知道了,对了,其中stripped_strings返回来的是一个迭代器,所以需要转换成list
# 循环遍历
for sell in sellListContent:
try:
# 题目
title = sell.select('div.title a')[0].string
# 先抓取全部的div信息,再针对每一条进行提取
houseInfo = list(sell.select('div.houseInfo')[0].stripped_strings)
# 楼盘名字
loupan = houseInfo[0]
# 对剩下的信息进行分割
info = houseInfo[1].split('|')
# 房子类型
house_type = info[1].strip()
# 面积
area = info[2].strip()
# 朝向
toward = info[3].strip()
# 装修类型
renovation = info[4].strip()
# 地址
positionInfo = ''.join(list(sell.select('div.positionInfo')[0].stripped_strings))
# 总价
totalPrice = ''.join(list(sell.select('div.totalPrice')[0].stripped_strings))
# 单价
unitPrice = list(sell.select('div.unitPrice')[0].stripped_strings)[0]
# 声明一个字典存储数据
data_dict = {}
data_dict['title'] = title
data_dict['loupan'] = loupan
data_dict['house_type'] = house_type
data_dict['area'] = area
data_dict['toward'] = toward
data_dict['renovation'] = renovation
data_dict['positionInfo'] = positionInfo
data_dict['totalPrice'] = totalPrice
data_dict['unitPrice'] = unitPrice
data_list.append(data_dict)
print(data_dict)
7. 完整代码附上
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
import json
import csv
import time
# 构建请求头
ua = UserAgent()
headers = {
'user-agent': ua.Chrome
}
# 声明一个列表存储字典
data_list = []
def start_spider(page):
url = 'https://hk.lianjia.com/ershoufang/pg{}/'.format(page)
# 请求url
resp = requests.get(url, headers=headers)
# 讲返回体转换成Beautiful
soup = BeautifulSoup(resp.content, 'lxml')
# 筛选全部的li标签
sellListContent = soup.select('.sellListContent li.LOGCLICKDATA')# 循环遍历
for sell in sellListContent:
try:
# 题目
title = sell.select('div.title a')[0].string
# 先抓取全部的div信息,再针对每一条进行提取
houseInfo = list(sell.select('div.houseInfo')[0].stripped_strings)
# 楼盘名字
loupan = houseInfo[0]
# 对剩下的信息进行分割
info = houseInfo[1].split('|')
# 房子类型
house_type = info[1].strip()
# 面积
area = info[2].strip()
# 朝向
toward = info[3].strip()
# 装修类型
renovation = info[4].strip()
# 地址
positionInfo = ''.join(list(sell.select('div.positionInfo')[0].stripped_strings))
# 总价
totalPrice = ''.join(list(sell.select('div.totalPrice')[0].stripped_strings))
# 单价
unitPrice = list(sell.select('div.unitPrice')[0].stripped_strings)[0]
# 声明一个字典存储数据
data_dict = {}
data_dict['title'] = title
data_dict['loupan'] = loupan
data_dict['house_type'] = house_type
data_dict['area'] = area
data_dict['toward'] = toward
data_dict['renovation'] = renovation
data_dict['positionInfo'] = positionInfo
data_dict['totalPrice'] = totalPrice
data_dict['unitPrice'] = unitPrice
data_list.append(data_dict)
print(data_dict)except Exception as e:
continue
def main():
# 只爬取10页
for page in range(1, 10):
start_spider(page)
time.sleep(3)
# 将数据写入json文件
with open('data_json.json', 'a+', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件写入完成')
# 将数据写入csv文件
with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f:
# 表头
title = data_list[0].keys()
# 创建writer对象
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
if __name__ == '__main__':
main()

相关文章推荐
- 使用Python爬取学校学生信息!(简单爬虫)
- Python爬虫 - 使用requests和re模块爬取慕课网课程信息
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
- Python爬虫——4.6使用requests和正则表达式、随机代理爬取淘宝网商品信息
- Python 使用selenium爬取房天下网站,房源动态信息
- Python爬虫使用脚本登录Github并查看信息
- python爬虫使用selenium爬取动态网页信息——以智联招聘网站为例
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
- python爬虫小练习之一:bs4库基础爬信息
- Python爬虫1----房源信息
- python爬虫使用代理池爬取拉勾网python招聘信息
- python requests爬虫使用lxml解析HTML获取信息不对等的问题
- python爬虫学习-scrapy爬取链家房源信息并存储(翻页)
- Python爬虫项目--爬取自如网房源信息
- Python爬虫小实践:使用BeautifulSoup+Request爬取CSDN博客的个人基本信息
- 使用简单的python语句编写爬虫 定时拿取信息并存入txt
- Python爬虫实战一之使用Beautiful Soup抓取百度招聘信息并存储excel文件
- Python爬虫(十五)_案例:使用bs4的爬虫
- 使用python爬虫实现网络股票信息爬取的demo
- python3 简单爬虫实战|使用selenium来模拟浏览器抓取选股宝网站信息里面的股票