python爬虫——如何爬取js渲染的网页之爬取知乎的问题及作者信息
2019-04-10 16:14
183 查看
版权声明:转载需注明来源 https://blog.csdn.net/weixin_44024393/article/details/89186248
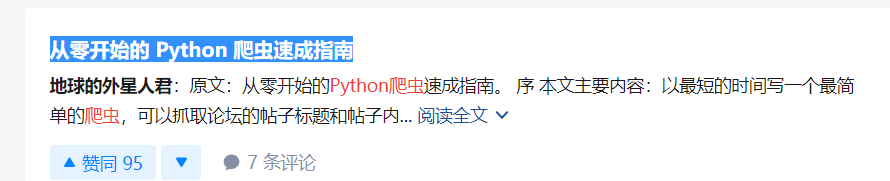
1. 访问知乎话题搜索python爬虫关键字

2. 往下翻页后的再查看源代码是加载不出来的,只能加载第一页的代码
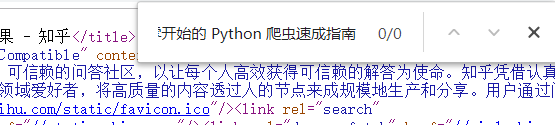
3. 右键检查刷新之后可以看到下图有这么一个网址,通过这个接口就可以爬取那些渲染后的信息了

4. 随便打开一个,我们需要的信息在这里可以找到,顺便提一下,这个网址返回来的数据是json格式的,也就是可以像字典那样操作
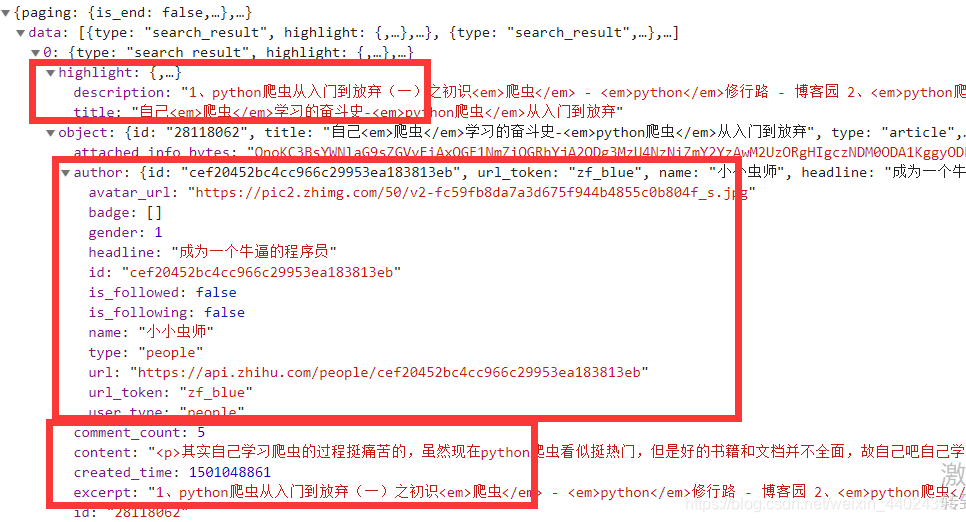
5. 话不多说,代码附上,如果想要爬取多的话,建议弄个代理,闲速度慢的可以写线程,但是我们的目的是提取数据,而不是攻击服务器,所以速度不要太快了
import requests
import json
import csv
from fake_useragent import UserAgent
from urllib.parse import urlencode
import time
ua = UserAgent()
# 构建请求头
headers = {
'user-agent': ua.Chrome
}
# 声明一个列表存储字典
data_list = []
def parse_url(page):
# 构建url参数
data = {
'q': 'python爬虫',
'offset': page,
'limit': '20'
}
url = 'https://www.zhihu.com/api/v4/search_v3?' + urlencode(data)
# 请求url
resp = requests.get(url, headers=headers)
# 返回来的是json数据
data_json = resp.json()
# 获取数据存储的key,获取的data是一个列表
data_json = data_json.get('data')
# 遍历
for data in data_json:
# 判断数据是否存在
if data.get('object') and data.get('object').get('author'):
# 获取题目并清洗数据
title = data.get('highlight').get('title').replace('<em>', '').replace('</em>', '').replace('\n', '')
# 摘要并清洗数据
description = data.get('highlight').get('description').replace('<em>', '').replace('</em>', '').replace('\n', '')
# 作者的信息存储再'author'这个关键字,所以先提取这个关键字的值
author = data.get('object').get('author')
# 作者名字
name = author.get('name').replace('<em>', '').replace('</em>', '').replace('\n', '')
# 作者性别
gender = author.get('gender')
# 评论数
comment_count = data.get('object').get('comment_count')
# 点赞数
voteup_count = data.get('object').get('voteup_count')
# 声明一个字典存储数据
data_dict = {}
data_dict['title'] = title
data_dict['description'] = description
data_dict['name'] = name
data_dict['gender'] = gender
data_dict['comment_count'] = comment_count
data_dict['voteup_count'] = voteup_count
# 数据去重
if data_dict not in data_list:
data_list.append(data_dict)
print(data_dict)
def main():
for page in range(0, 10):
parse_url(page * 20)
# 延迟2秒,我们不是在攻击人家的服务器
time.sleep(2)
if __name__ == '__main__':
main()
# 将数据写入json文件
with open('data_json.json', 'a+', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=4)
print('json文件写入完成')
# 将数据写入csv文件
# 表头
title = data_list[0].keys()
with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')

相关文章推荐
- python爬虫 爬取知乎用户的用户信息
- Phantomjs抓取渲染JS后的网页(Python代码)
- python爬虫解析网页编码问题
- python爬虫——爬取知乎上自己关注的问题
- Python爬虫实现网页信息抓取功能示例【URL与正则模块】
- 如何制作知乎话题信息爬虫
- 知乎:你是如何开始能写python爬虫?
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
- Python 爬虫 —— 获取js渲染的内容
- 网页爬虫抓取js动态渲染数据
- 爬虫基础 --selenium库(解决JS渲染问题)
- python爬虫——如何爬取ajax网页之爬取雪球网文章
- python爬虫如何爬知乎的话题?
- [python](爬虫)如何使用正确的姿势欣赏知乎的“长得好看是怎样一种体验呢?”问答中的相片
- C++和python如何获取百度搜索结果页面下信息对应的真实链接(百度搜索爬虫,可指定页数)
- python爬虫解决网页重定向问题
- Python爬虫学习——使用selenium和phantomjs爬取js动态加载的网页
- Python爬虫爬取知乎用户信息+寻找潜在客户
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
- Python爬虫之处理带Ajax、Js的网页