初级算法梳理课程___第二次学习笔记
逻辑回归
逻辑回归与线性回归得联系与区别
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。 这种函数是一个或多个称为回归系数的模型参数的线性组合(自变量都是一次方)。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。(转载参考https://blog.csdn.net/lc013/article/details/55002463 https://blog.csdn.net/chibangyuxun/article/details/53148005)
逻辑回归算法基于Sigmoid函数,或者说Sigmoid就是逻辑回归函数。 Sigmoid函数定义如下:
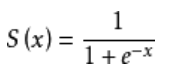
逻辑回归与线性回归的联系与区别
逻辑回归的模型 是一个非线性模型,sigmoid函数,又称逻辑回归函数。但是它本质上又是一个线性回归模型,因为除去sigmoid映射函数关系,其他的步骤,算法都是线性回归的。可以说,逻辑回归,都是以线性回归为理论支持的。
只不过,线性模型,无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。如是否垃圾邮件分类?是否金融欺诈?
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalizedlinear model)。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
- 如果是连续的,就是多重线性回归
- 如果是二项分布,就是Logistic回归
- 如果是Poisson分布,就是Poisson回归
- 如果是负二项分布,就是负二项回归
正则化与模型评估指标
为防止过度拟合的模型出现(过于复杂的模型),在损失函数里增加一个每个特征的惩罚因子。这个就是正则化。
由于我们追求损失函数的最小值,让模型在训练集上表现最优,可能会引发另一个问题:如果模型在训练集上表优秀,却在测试集上表现糟糕,模型就会过拟合,因此需要控制过拟合的技术来调整模型,对逻辑回归中过拟合的控制,通过正则化来实现。
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数量θ \thetaθ的L1范式和L2范式的倍数来实现,这个增加的范式,被称为"正则项",也被称为"惩罚项",由于损失函数的最优化来求解的参数取值必然发生改变,以此来调节模型拟合的程度,其中L1范数的每个参数的绝对值之和,L2范数表现为参数向量中的每个参数的平方和的开方值。
样本不均衡问题解决办法
不均衡问题指的是,在分类中,不同类别下的样本数目相差巨大,比如在逻辑回归中,训练集中标签1的样本数比上标签2的样本数的比值为60:1。使用逻辑回归进行分类,最后结果是其忽略了标签2,将所有的训练样本都分类为标签1。
解决办法:
1.过采样:将稀有类别的样本进行复制,通过增加此稀有类样本的数量来平衡数据集。该方法适用于数据量较小的情况。
2.欠抽样:从丰富类别的样本中随机选取和稀有类别相同数目的样本,通过减少丰富类的样本量啦平衡数据集。该方法适用于数据量较大的情况。
3.也可以将过采样和欠采样结合在一起使用。
改变正负类别样本在模型中的权重。使用代价函数学习得到每个类的权值,大类的权值小,小类的权值大。刚开始,可以设置每个类别的权值与样本个数比例的倒数,然后可以使用过采样进行调优。
(转载参考https://blog.csdn.net/cf1169983240/article/details/88933895 )
sklearn参数







(转载参考https://blog.csdn.net/loveliuzz/article/details/78708359)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
#乳腺癌分类案例
import sklearn
from sklearn.linear_model import LogisticRegressionCV,LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model.coordinate_descent import ConvergenceWarning
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import warnings
#解决中文显示问题
mpl.rcParams["font.sans-serif"] = [u"SimHei"]
mpl.rcParams["axes.unicode_minus"] = False
#拦截异常
warnings.filterwarnings(action='ignore',category=ConvergenceWarning)
#导入数据并对异常数据进行清除
path = "datas/breast-cancer-wisconsin.data"
names = ["id","Clump Thickness","Uniformity of Cell Size","Uniformity of Cell Shape"
,"Marginal Adhesion","Single Epithelial Cell Size","Bare Nuclei","Bland Chromatin"
,"Normal Nucleoli","Mitoses","Class"]
df = pd.read_csv(path,header=None,names=names)
datas = df.replace("?",np.nan).dropna(how="any") #只要列中有nan值,进行行删除操作
#print(datas.head()) #默认显示前五行
#数据提取与数据分割
X = datas[names[1:10]]
Y = datas[names[10]]
#划分训练集与测试集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.1,random_state=0)
#对数据的训练集进行标准化
ss = StandardScaler()
X_train = ss.fit_transform(X_train) #先拟合数据在进行标准化
#构建并训练模型
## multi_class:分类方式选择参数,有"ovr(默认)"和"multinomial"两个值可选择,在二元逻辑回归中无区别
## cv:几折交叉验证
## solver:优化算法选择参数,当penalty为"l1"时,参数只能是"liblinear(坐标轴下降法)"
## "lbfgs"和"cg"都是关于目标函数的二阶泰勒展开
## 当penalty为"l2"时,参数可以是"lbfgs(拟牛顿法)","newton_cg(牛顿法变种)","seg(minibactch随机平均梯度下降)"
## 维度<10000时,选择"lbfgs"法,维度>10000时,选择"cs"法比较好,显卡计算的时候,lbfgs"和"cs"都比"seg"快
## penalty:正则化选择参数,用于解决过拟合,可选"l1","l2"
## tol:当目标函数下降到该值是就停止,叫:容忍度,防止计算的过多
lr = LogisticRegressionCV(multi_class="ovr",fit_intercept=True,Cs=np.logspace(-2,2,20),cv=2,penalty="l2",solver="lbfgs",tol=0.01)
re = lr.fit(X_train,Y_train)
#模型效果获取
r = re.score(X_train,Y_train)
print("R值(准确率):",r)
print("参数:",re.coef_)
print("截距:",re.intercept_)
print("稀疏化特征比率:%.2f%%" %(np.mean(lr.coef_.ravel()==0)*100))
print("=========sigmoid函数转化的值,即:概率p=========")
print(re.predict_proba(X_test)) #sigmoid函数转化的值,即:概率p
#模型的保存与持久化
from sklearn.externals import joblib
joblib.dump(ss,"logistic_ss.model") #将标准化模型保存
joblib.dump(lr,"logistic_lr.model") #将训练后的线性模型保存
joblib.load("logistic_ss.model") #加载模型,会保存该model文件
joblib.load("logistic_lr.model")
#预测
X_test = ss.transform(X_test) #数据标准化
Y_predict = lr.predict(X_test) #预测
#画图对预测值和实际值进行比较
x = range(len(X_test))
plt.figure(figsize=(14,7),facecolor="w")
plt.ylim(0,6)
plt.plot(x,Y_test,"ro",markersize=8,zorder=3,label=u"真实值")
plt.plot(x,Y_predict,"go",markersize=14,zorder=2,label=u"预测值,$R^2$=%.3f" %lr.score(X_test,Y_test))
plt.legend(loc="upper left")
plt.xlabel(u"数据编号",fontsize=18)
plt.ylabel(u"乳癌类型",fontsize=18)
plt.title(u"Logistic算法对数据进行分类",fontsize=20)
plt.savefig("Logistic算法对数据进行分类.png")
plt.show()
print("=============Y_test==============")
print(Y_test.ravel())
print("============Y_predict============")
print(Y_predict)
逻辑回归的优缺点
优点:
1、实现简单,适合二分类问题;
2、分类时计算量非常小,速度很快,存储资源低;
3、简单易于理解,直接看到各个特征的权重;
4、能容易地更新模型吸收新的数据 。
缺点:
1、对数据和场景的适应能力有局限性,不如决策树算法适应性那么强;
2、只能处理二分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
适用数据类型:数值型和标称型数据。
类别:分类算法。
试用场景:解决二分类问题。

- 《深度学习Ng》课程学习笔记02week2——优化算法
- 台大林轩田机器学习课程笔记1----机器学习初探及PLA算法
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-2)-- 优化算法
- 「初级算法学习小组」任务1——线性回归算法梳理
- Hinton Neural Networks课程笔记3a:线性神经元的学习算法
- 台大基础课程学习笔记——PLA算法1
- 吴恩达神经网络和深度学习课程自学笔记(六)之优化算法
- C++ primer第二次阅读学习笔记(第11章:泛型算法)
- (斯坦福机器学习课程笔记)牛顿法算法学习
- 学习内容:KNN算法实现-阿里云人工智能课程笔记
- 数据挖掘算法之时间序列算法(平稳时间序列模型,AR(p),MA(q),(平稳时间序列模型,AR(p),MA(q),ARMA(p,q)模型和非平稳时间序列模型,ARIMA(p,d,q)模型)学习笔记梳理
- Hinton Neural Networks课程笔记2d:为什么感知机的学习算法可以收敛
- 【机器学习 吴恩达】CS229课程笔记notes2翻译-Part IV生成学习算法
- 算法第四版学习笔记之初级排序算法
- C++ primer第二次阅读学习笔记(第11章:泛型算法)
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-2)-- 优化算法
- 数据结构与算法学习笔记之高效、简洁的编码技巧“递归”
- 2016年3月22日数据库学习笔记[初级]
- 算法学习笔记之一阶低通滤波算法
- 《深度学习Ng》课程学习笔记03week2——机器学习(ML)策略(2)