Python利用SVM进行实例建模
2018-03-19 19:25
453 查看
一、建立时间预测器
1.准备工作
我们所获得的数据集主要来源于课本配套网站,我们首先看building_event_binary.txt文件中6个字符串数据的排序:
星期、日期、时间、离开大楼的人数、进入大楼的人数、是否有活动
前5个字段组成输入数据,我们的任务是预测大楼是否举行活动。
building_event_multiclass.txt文件星期、日期、时间、离开大楼的人数、进入大楼的人数、活动类型
2.详细步骤
首先将数据全部加在X中:import numpy as np
from sklearn import preprocessing
from sklearn.svm import SVC
input_file = 'building_event_binary.txt'
#读取数据
X = []
count = 0
with open(input_file,'r') as f:
for line in f.readlines():
data = line[:-1].split(',')
X.append([data[0]] + data[2:])
X = np.array(X)下面将字符串格式转换成数值格式label_encoder = []
X_encoder = np.empty(X.shape)
for i,item in enumerate(X[0]):
if item.isdigit():
X_encoder[:,i] = X[:,i]
else:
label_encoder.append(preprocessing.LabelEncoder())
X_encoder[:,i] = label_encoder[-1].fit_transform(X[:,i])
X = X_encoder[:,:-1].astype(int)
y = X_encoder[:,-1].astype(int)用径向基函数、概率输出和类型平衡方法训练SVM分类器并进行交叉验证params = {'kernel':'rbf','probability':True}
classifier = SVC(**params)
classifier.fit(X,y)
#交叉验证
from sklearn import cross_validation
accuracy = cross_validation.cross_val_score(classifier,
X,y,scoring = 'accuracy',cv = 3)
print("Accuracy of the classifier:" + str(round(100*accuracy.mean(),2))+"%")用一个新的数据点测试SVMinput_data = ['Tuesday', '12:30:00','21','23']
input_data_encoded = [-1] * len(input_data)
count = 0
for i,item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform(input_data[i]))
count = count + 1
input_data_encoded = np.array(input_data_encoded)为特定数据点预测并打印输出结果output_class = classifier.predict(input_data_encoded)
print("Output class:", label_encoder[-1].inverse_transform(output_class)[0])结果如下:

准确率达到93%
二、估算交通流量
1.traffuc_data.txt文件包含以下字段:
星期、时间、对手球队、棒球比赛是否继续、通行汽车数量
2.代码步骤
数据加载import numpy as np
from sklearn import preprocessing
from sklearn.svm import SVR
input_file = 'traffic_data.txt'
# Reading the data
X = []
count = 0
with open(input_file, 'r') as f:
for line in f.readlines():
data = line[:-1].split(',')
X.append(data)
X = np.array(X)把数据进行编码label_encoder = []
X_encoded = np.empty(X.shape)
for i,item in enumerate(X[0]):
if item.isdigit():
X_encoded[:, i] = X[:, i]
else:
label_encoder.append(preprocessing.LabelEncoder())
X_encoded[:, i] = label_encoder[-1].fit_transform(X[:, i])
X = X_encoded[:, :-1].astype(int)
y = X_encoded[:, -1].astype(int)用径向基函数创建并训练SVM回归器,参数C指定了对错误分类的惩罚,参数epsilon指定了不使用惩罚的限制params = {'kernel': 'rbf', 'C': 10.0, 'epsilon': 0.2}
regressor = SVR(**params)
regressor.fit(X, y)用交叉验证来检查回归器的性能import sklearn.metrics as sm
y_pred = regressor.predict(X)
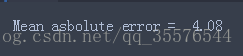
print("Mean asbolute error = ",round(sm.mean_absolute_error(y,y_pred),2)在一个数据点上进行测试input_data = ['Tuesday', '13:35', 'San Francisco', 'yes']
input_data_encoded = [-1] * len(input_data)
count = 0
for i,item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform(input_data[i]))
count = count + 1
input_data_encoded = np.array(input_data_encoded)
# Predict and print output for a particular datapoint
print("Predicted traffic:", int(regressor.predict(input_data_encoded)[0]))结果如下:
1.准备工作
我们所获得的数据集主要来源于课本配套网站,我们首先看building_event_binary.txt文件中6个字符串数据的排序:
星期、日期、时间、离开大楼的人数、进入大楼的人数、是否有活动
前5个字段组成输入数据,我们的任务是预测大楼是否举行活动。
building_event_multiclass.txt文件星期、日期、时间、离开大楼的人数、进入大楼的人数、活动类型
2.详细步骤
首先将数据全部加在X中:import numpy as np
from sklearn import preprocessing
from sklearn.svm import SVC
input_file = 'building_event_binary.txt'
#读取数据
X = []
count = 0
with open(input_file,'r') as f:
for line in f.readlines():
data = line[:-1].split(',')
X.append([data[0]] + data[2:])
X = np.array(X)下面将字符串格式转换成数值格式label_encoder = []
X_encoder = np.empty(X.shape)
for i,item in enumerate(X[0]):
if item.isdigit():
X_encoder[:,i] = X[:,i]
else:
label_encoder.append(preprocessing.LabelEncoder())
X_encoder[:,i] = label_encoder[-1].fit_transform(X[:,i])
X = X_encoder[:,:-1].astype(int)
y = X_encoder[:,-1].astype(int)用径向基函数、概率输出和类型平衡方法训练SVM分类器并进行交叉验证params = {'kernel':'rbf','probability':True}
classifier = SVC(**params)
classifier.fit(X,y)
#交叉验证
from sklearn import cross_validation
accuracy = cross_validation.cross_val_score(classifier,
X,y,scoring = 'accuracy',cv = 3)
print("Accuracy of the classifier:" + str(round(100*accuracy.mean(),2))+"%")用一个新的数据点测试SVMinput_data = ['Tuesday', '12:30:00','21','23']
input_data_encoded = [-1] * len(input_data)
count = 0
for i,item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform(input_data[i]))
count = count + 1
input_data_encoded = np.array(input_data_encoded)为特定数据点预测并打印输出结果output_class = classifier.predict(input_data_encoded)
print("Output class:", label_encoder[-1].inverse_transform(output_class)[0])结果如下:
准确率达到93%
二、估算交通流量
1.traffuc_data.txt文件包含以下字段:
星期、时间、对手球队、棒球比赛是否继续、通行汽车数量
2.代码步骤
数据加载import numpy as np
from sklearn import preprocessing
from sklearn.svm import SVR
input_file = 'traffic_data.txt'
# Reading the data
X = []
count = 0
with open(input_file, 'r') as f:
for line in f.readlines():
data = line[:-1].split(',')
X.append(data)
X = np.array(X)把数据进行编码label_encoder = []
X_encoded = np.empty(X.shape)
for i,item in enumerate(X[0]):
if item.isdigit():
X_encoded[:, i] = X[:, i]
else:
label_encoder.append(preprocessing.LabelEncoder())
X_encoded[:, i] = label_encoder[-1].fit_transform(X[:, i])
X = X_encoded[:, :-1].astype(int)
y = X_encoded[:, -1].astype(int)用径向基函数创建并训练SVM回归器,参数C指定了对错误分类的惩罚,参数epsilon指定了不使用惩罚的限制params = {'kernel': 'rbf', 'C': 10.0, 'epsilon': 0.2}
regressor = SVR(**params)
regressor.fit(X, y)用交叉验证来检查回归器的性能import sklearn.metrics as sm
y_pred = regressor.predict(X)
print("Mean asbolute error = ",round(sm.mean_absolute_error(y,y_pred),2)在一个数据点上进行测试input_data = ['Tuesday', '13:35', 'San Francisco', 'yes']
input_data_encoded = [-1] * len(input_data)
count = 0
for i,item in enumerate(input_data):
if item.isdigit():
input_data_encoded[i] = int(input_data[i])
else:
input_data_encoded[i] = int(label_encoder[count].transform(input_data[i]))
count = count + 1
input_data_encoded = np.array(input_data_encoded)
# Predict and print output for a particular datapoint
print("Predicted traffic:", int(regressor.predict(input_data_encoded)[0]))结果如下:

相关文章推荐
- 数据挖掘(Python)——利用sklearn进行数据挖掘,实现算法:svm、knn、C5.0、NaiveBayes
- python利用urlib2进行简单爬虫实例
- python利用装饰器进行运算的实例分析
- 利用Python进行异常值分析实例代码
- python-利用pyaudio进行声音录制及简单实例代码分享
- Python中利用Scipy包的SIFT方法进行图片识别的实例教程
- Python中利用Scipy包的SIFT方法进行图片识别的实例教程
- 利用Python sklearn的SVM对AT&T人脸数据进行人脸识别
- python利用装饰器进行运算的实例分析
- 利用Python进行数据分析_python3实现_pandas入门_相关系数与协方差
- python利用cookie登录网站进行访问
- 利用Python对二进制数据进行按位处理
- python对app页面元素进行封装并设置查找时间操作实例
- 利用python进行数据分析(四):数据加载、存储
- python 利用库sklearn 中的 grid_search对svm 参数寻优(借鉴)
- 利用Python【Orange】结合DNA序列进行人种预测
- 利用python进行数据分析(六):绘图和可视化
- 利用python进行微信好友数据分析
- python 利用pexpect进行多机远程命令执行
- 利用class、id对元素进行分类、标识实例