Hadoop2.6.4 HA 高可用分布式集群安装配置详细步骤
2018-02-28 08:30
931 查看
zookeeper在hadoop HA中的应用,zookeeper监控NN和RM,当发现有服务挂掉时,会通过选举服务选出一个active状态的节点继续运行。
(已完成的准备工作:1、安装jdk并配置环境变量;2、关闭防火墙;3、ssh无密登录;4、安装zookeeper集群服务)
所用环境与安装zookeeper环境一样,可参考。
《centos6.5 zookeeper 集群服务安装》
5台机器的集群配置如下
192.168.168.116 master1 (第一名称节点)
192.168.168.117 master2 (第二名称节点)
192.168.168.118 slaver1
192.168.168.119 slaver2
192.168.168.120 slaver3
都是用root用户,hadoop-2.6.4.tar.gz 放在下载文件夹下
一、开始搭建HA环境
在master1机器上操作
# cd /root/下载
# tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
# mv /usr/local/hadoop-2.6.4 /usr/local/hadoop #更改文件夹名称
1、修改环境变量:
# vi /etc/profile 新增以下配置,并重载配置文件
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
在根目录直接执行查看,出现版本信息说明安装及环境配置完成。

2、修改hadoop启动环境变量配置
# vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
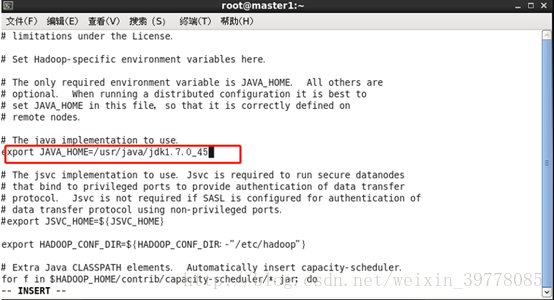
重载配置文件
# source /usr/local/hadoop/etc/hadoop/hadoop-env.sh
============================华丽的分割线,修改配置文件==================
1、修改core-site.xml 配置文件
<configuration>
<!-- 指定hdfs的namenode集群为mycluster,不是单独的namenode名称,与hdfs-site.xml的HA配置相同 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定缓存文件存储的路径,默认的一般会删除,请自定义创建! -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hdfile</value>
</property>
<!-- 配置hdfs文件被永久删除前保留的时间(单位:分钟),默认值为0表明垃圾回收站功能关闭 ,一般选择默认,不用设置-->
<!--
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
-->
<!-- 指定zookeeper地址,配置HA时需要,zookeeper的ip地址和端口 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
</configuration>
2、修改hdfs-site.xml 配置文件
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfile/dfs/name</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfile/dfs/data</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //////////////以下为HDFS HA的配置////////////// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 指定mycluster的两个namenode的名称分别为 master1,master2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>master1,master2</value>
</property>
<!-- 配置master1,master2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.master1</name>
<value>master1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.master2</name>
<value>master2:9000</value>
</property>
<!-- 配置 master1,master2 的http通信端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.master2</name>
<value>master2:50070</value>
</property>
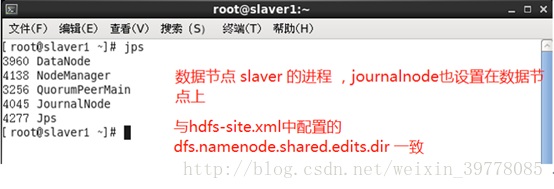
<!-- 指定namenode元数据存储在journalnode中的路径;一般此处配置在相应的datanode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slaver1:8485;slaver2:8485;slaver3:8485/mycluster</value>
</property>
<!--指定该集群在故障时是否自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
<!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/data/journal</value>
</property>
<!-- 指定HDFS客户端连接active namenode的java类,在故障时自动切换 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启自动故障转移 -->
<!--<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
-->
<!--connect-timeout连接超时 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
3、修改mapred-site.xml 配置文件
<configuration>
<!-- 指定为mr框架为yarn框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>
e91c
mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
<!-- 开启uber模式(针对小作业的优化) -->
<!--
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
-->
<!-- 配置启动uber模式的最大map数 -->
<!--
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
-->
<!-- 配置启动uber模式的最大reduce数 -->
<!--
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
-->
</configuration>
4、修改yarn-site.xml 配置文件
<configuration>
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!--开启resourcemanagerHA,默认为false-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--配置resourcemanager-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- zookeeper集群地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
<!--开启故障自动切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<!--
在master1上配置为rm1,在master2上配置为rm2,
注意:一般都喜欢把配置好的文件远程复制到其它机器上,但这个在YARN的另一个机器上一定要修改
-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node,we need this configuration</description>
<!-- 在nn2上面此处需要修改-->
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 开启yarn nodemanager restart -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置nodemanager IPC的通信端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
<!--配置与zookeeper的连接地址-->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster-yarn</value>
</property>
<!--schelduler失联等待连接时间-->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--配置rm1-->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master1:23142</value>
</property>
<!--配置rm2-->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>master2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>master2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>master2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>master2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>master2:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop/yarn</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/usr/local/hadoop/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!--故障处理类-->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
<description>Optionalsetting.Thedefaultvalueis/yarn-leader-election</description>
</property>
</configuration>
5、修改slaves配置文件
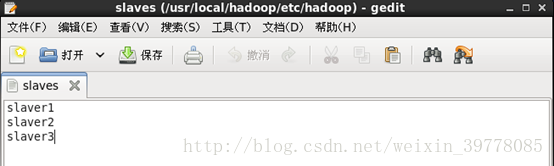
分发到其他节点,并修改环境变量
# scp –r /usr/local/hadoop/ root@master2:/usr/local
======================高能分割线,HA集群初始化启动=====================
二、HA集群初始化
1、启动zookeeper集群(每台zookeeper机器)
# cd /usr/local/zookeeper/bin
# ./zkServer.sh start
# zkServer.sh start (如果配置了环境变量,直接执行)
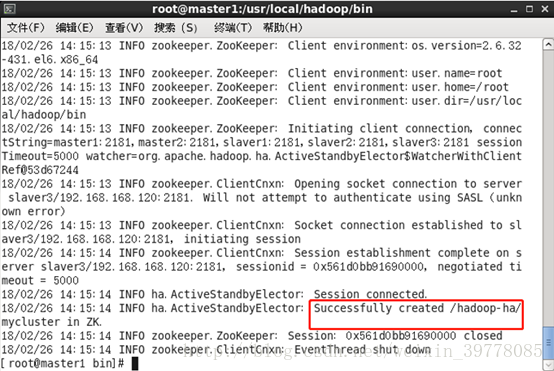
2、在master1上格式化zkfc
我已经配置了 环境变量,不指定为什么每次都要重载才生效(很惆怅,下面都是直接到命令目录下执行……)
# cd /usr/local/hadoop/bin
# ./hdfs zkfc -formatZK
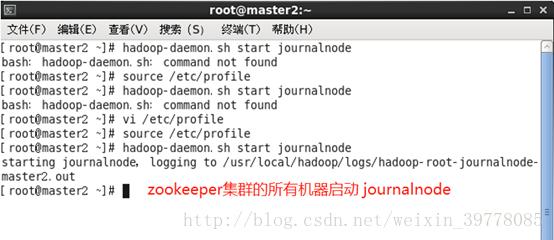
3、在zookeeper集群(所有zookeeper机器)启动journalnode
(第一次初始化时启动,后面由hdfs带起,不需要单独启动)
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh start journalnode
4、在master1上格式化HDFS(需先执行第三步)
# cd /usr/local/hadoop/bin
# ./hdfs namenode -format
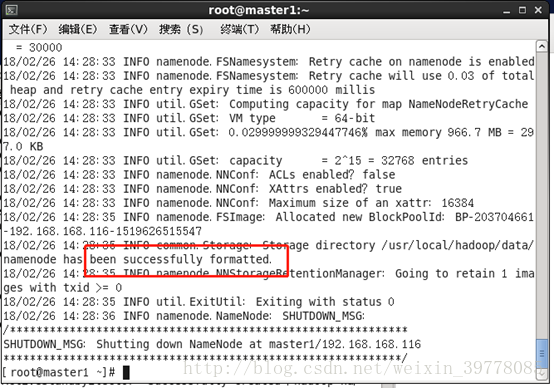
5、复制元数据目录到master2的相应路径 (即core-site.xml配置的hadoop.tmp.dir的目录)
# scp –r /usr/local/hadoop/hdfile root@master2:/usr/local/hadoop
完毕后先关闭zookeeper集群的journalnode(因为启动hdfs时会自动带起journalnode进程)
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh stop journalnode
6、启动hadop集群
# cd /usr/local/hadoop/sbin
# ./start-dfs.sh
# ./start-yarn.sh
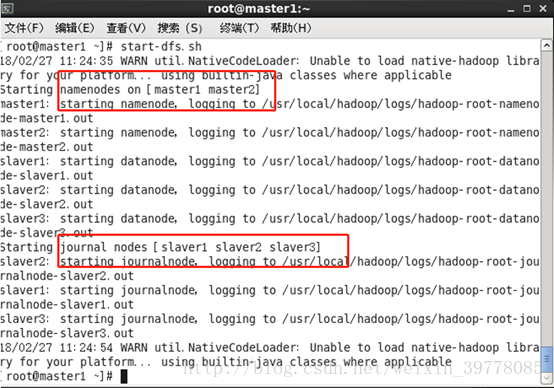
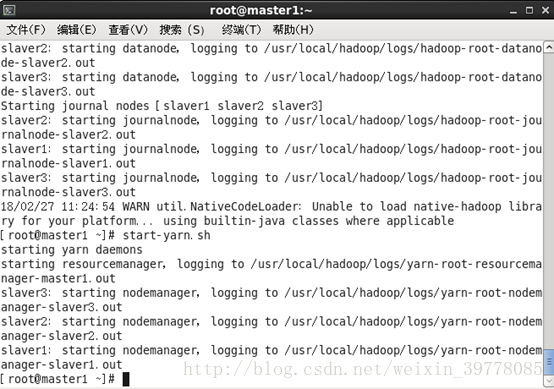
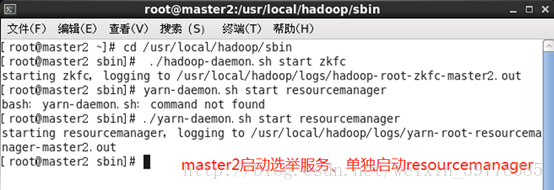
7、master1和master2启动选举服务,否则两个namenode都会是standby状态
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh start zkfc
另外,master2需单独启动resourcemanager
# cd /usr/local/hadoop/sbin
# ./yarn-daemon.sh start resourcemanager
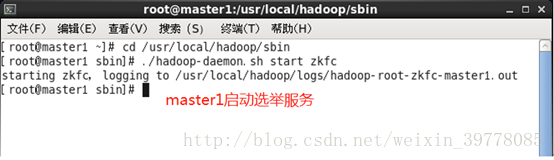
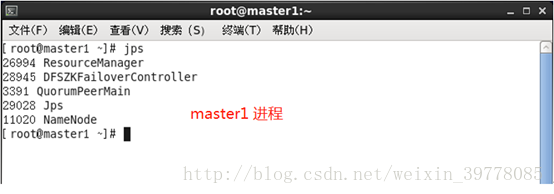
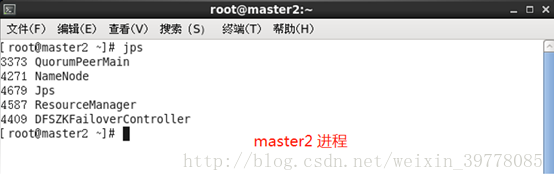
jps 查看相应进程
最后,登录hadoop界面查看校验。
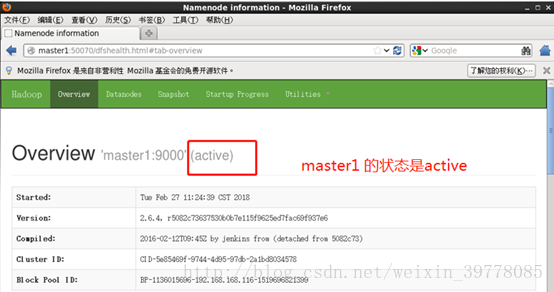
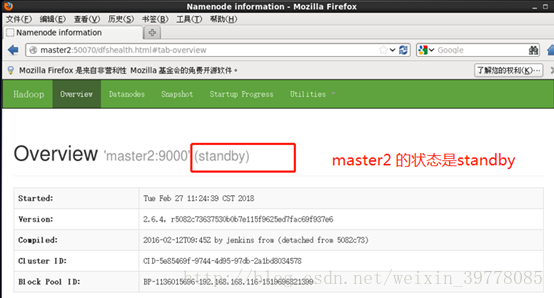
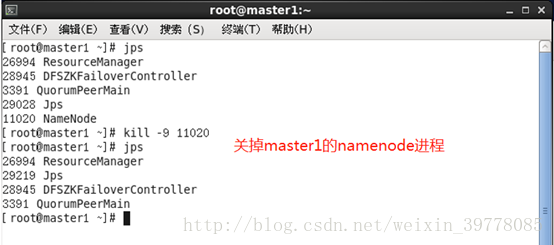
Kill掉master的namenode进程,然后会看到master的状态变成active,HA高可用自动切换部署成功!
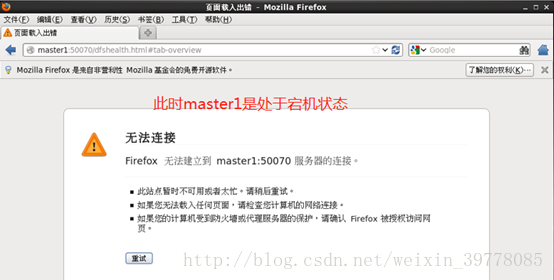
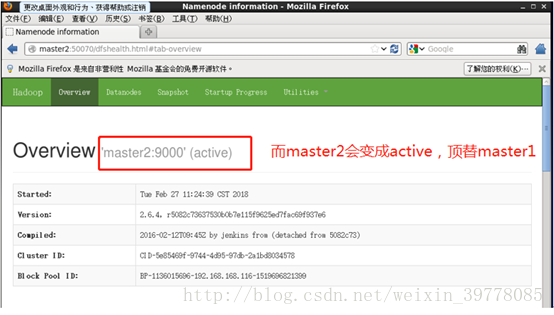
完成!

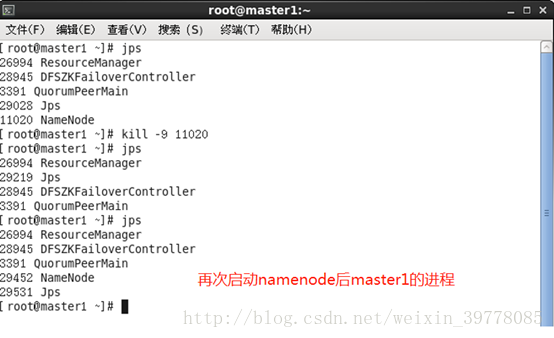
此时再启动master1的namenode,会是待命standby状态。
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh start namenode
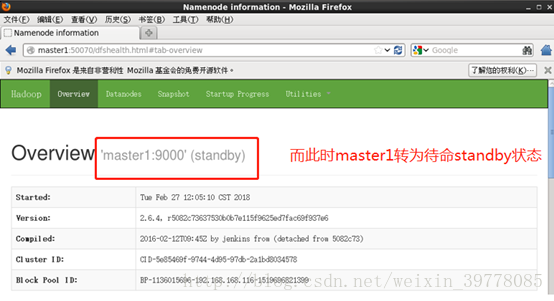

至此,hadoop 高可用HA集群安装部署完成。
最后,关于集群的启停顺序
启动:zookeeper——dfs——yarn
停止:yarn——dfs——zookeeper
关闭整个集群后的启动,必须在master1和master2上启动选举服务
# hadoop-daemon.sh start zkfc
master2单独启动rm
# yarn-daemon.sh start resourcemanager
其他补充:
# hadoop-daemon.sh start namenode #单独启动名称节点
# hadoop-daemon.sh start datanode #单独启动数据节点
关于hadoop HA 的配置不尽相同,欢迎留言交流
(已完成的准备工作:1、安装jdk并配置环境变量;2、关闭防火墙;3、ssh无密登录;4、安装zookeeper集群服务)
所用环境与安装zookeeper环境一样,可参考。
《centos6.5 zookeeper 集群服务安装》
5台机器的集群配置如下
192.168.168.116 master1 (第一名称节点)
192.168.168.117 master2 (第二名称节点)
192.168.168.118 slaver1
192.168.168.119 slaver2
192.168.168.120 slaver3
都是用root用户,hadoop-2.6.4.tar.gz 放在下载文件夹下
一、开始搭建HA环境
在master1机器上操作
# cd /root/下载
# tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
# mv /usr/local/hadoop-2.6.4 /usr/local/hadoop #更改文件夹名称
1、修改环境变量:
# vi /etc/profile 新增以下配置,并重载配置文件
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
在根目录直接执行查看,出现版本信息说明安装及环境配置完成。
2、修改hadoop启动环境变量配置
# vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
重载配置文件
# source /usr/local/hadoop/etc/hadoop/hadoop-env.sh
============================华丽的分割线,修改配置文件==================
1、修改core-site.xml 配置文件
<configuration>
<!-- 指定hdfs的namenode集群为mycluster,不是单独的namenode名称,与hdfs-site.xml的HA配置相同 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定缓存文件存储的路径,默认的一般会删除,请自定义创建! -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hdfile</value>
</property>
<!-- 配置hdfs文件被永久删除前保留的时间(单位:分钟),默认值为0表明垃圾回收站功能关闭 ,一般选择默认,不用设置-->
<!--
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
-->
<!-- 指定zookeeper地址,配置HA时需要,zookeeper的ip地址和端口 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
</configuration>
2、修改hdfs-site.xml 配置文件
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfile/dfs/name</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfile/dfs/data</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //////////////以下为HDFS HA的配置////////////// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 指定mycluster的两个namenode的名称分别为 master1,master2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>master1,master2</value>
</property>
<!-- 配置master1,master2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.master1</name>
<value>master1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.master2</name>
<value>master2:9000</value>
</property>
<!-- 配置 master1,master2 的http通信端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.master2</name>
<value>master2:50070</value>
</property>
<!-- 指定namenode元数据存储在journalnode中的路径;一般此处配置在相应的datanode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slaver1:8485;slaver2:8485;slaver3:8485/mycluster</value>
</property>
<!--指定该集群在故障时是否自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
<!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/data/journal</value>
</property>
<!-- 指定HDFS客户端连接active namenode的java类,在故障时自动切换 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启自动故障转移 -->
<!--<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
-->
<!--connect-timeout连接超时 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
3、修改mapred-site.xml 配置文件
<configuration>
<!-- 指定为mr框架为yarn框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>
e91c
mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
<!-- 开启uber模式(针对小作业的优化) -->
<!--
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
-->
<!-- 配置启动uber模式的最大map数 -->
<!--
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
-->
<!-- 配置启动uber模式的最大reduce数 -->
<!--
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
-->
</configuration>
4、修改yarn-site.xml 配置文件
<configuration>
<!--rm失联后重新链接的时间-->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!--开启resourcemanagerHA,默认为false-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--配置resourcemanager-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- zookeeper集群地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
<!--开启故障自动切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<!--
在master1上配置为rm1,在master2上配置为rm2,
注意:一般都喜欢把配置好的文件远程复制到其它机器上,但这个在YARN的另一个机器上一定要修改
-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node,we need this configuration</description>
<!-- 在nn2上面此处需要修改-->
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 开启yarn nodemanager restart -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置nodemanager IPC的通信端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
<!--配置与zookeeper的连接地址-->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1:2181,master2:2181,slaver1:2181,slaver2:2181,slaver3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster-yarn</value>
</property>
<!--schelduler失联等待连接时间-->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--配置rm1-->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>master1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>master1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>master1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>master1:23142</value>
</property>
<!--配置rm2-->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>master2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>master2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>master2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>master2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>master2:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop/yarn</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/usr/local/hadoop/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!--故障处理类-->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
<description>Optionalsetting.Thedefaultvalueis/yarn-leader-election</description>
</property>
</configuration>
5、修改slaves配置文件
分发到其他节点,并修改环境变量
# scp –r /usr/local/hadoop/ root@master2:/usr/local
======================高能分割线,HA集群初始化启动=====================
二、HA集群初始化
1、启动zookeeper集群(每台zookeeper机器)
# cd /usr/local/zookeeper/bin
# ./zkServer.sh start
# zkServer.sh start (如果配置了环境变量,直接执行)
2、在master1上格式化zkfc
我已经配置了 环境变量,不指定为什么每次都要重载才生效(很惆怅,下面都是直接到命令目录下执行……)
# cd /usr/local/hadoop/bin
# ./hdfs zkfc -formatZK
3、在zookeeper集群(所有zookeeper机器)启动journalnode
(第一次初始化时启动,后面由hdfs带起,不需要单独启动)
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh start journalnode
4、在master1上格式化HDFS(需先执行第三步)
# cd /usr/local/hadoop/bin
# ./hdfs namenode -format
5、复制元数据目录到master2的相应路径 (即core-site.xml配置的hadoop.tmp.dir的目录)
# scp –r /usr/local/hadoop/hdfile root@master2:/usr/local/hadoop
完毕后先关闭zookeeper集群的journalnode(因为启动hdfs时会自动带起journalnode进程)
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh stop journalnode
6、启动hadop集群
# cd /usr/local/hadoop/sbin
# ./start-dfs.sh
# ./start-yarn.sh
7、master1和master2启动选举服务,否则两个namenode都会是standby状态
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh start zkfc
另外,master2需单独启动resourcemanager
# cd /usr/local/hadoop/sbin
# ./yarn-daemon.sh start resourcemanager
jps 查看相应进程
最后,登录hadoop界面查看校验。
Kill掉master的namenode进程,然后会看到master的状态变成active,HA高可用自动切换部署成功!
完成!
此时再启动master1的namenode,会是待命standby状态。
# cd /usr/local/hadoop/sbin
# ./hadoop-daemon.sh start namenode
至此,hadoop 高可用HA集群安装部署完成。
最后,关于集群的启停顺序
启动:zookeeper——dfs——yarn
停止:yarn——dfs——zookeeper
关闭整个集群后的启动,必须在master1和master2上启动选举服务
# hadoop-daemon.sh start zkfc
master2单独启动rm
# yarn-daemon.sh start resourcemanager
其他补充:
# hadoop-daemon.sh start namenode #单独启动名称节点
# hadoop-daemon.sh start datanode #单独启动数据节点
关于hadoop HA 的配置不尽相同,欢迎留言交流

相关文章推荐
- Apache Hadoop 分布式集群环境安装配置详细步骤
- hadoop-2.2.0伪分布式与(全分布集群安装于配置续,很详细的哦~)
- 最全的hadoop2.4.1版本分布式集群高可用模式安装步骤
- Hadoop集群安装详细步骤|Hadoop安装配置
- 集群分布式 Hadoop安装详细步骤
- Hadoop2.6.2完全分布式集群HA模式安装配置详解
- Hadoop2.6.2完全分布式集群HA模式安装配置详解
- hadoop学习之HDFS(2.2):centOS7安装高可用(HA)完全分布式集群hadoop2.7.2
- Hadoop2.6.2完全分布式集群HA模式安装配置详解
- hadoop2.6.4的HA集群搭建超详细步骤
- Hadoop分布式集群安装配置步骤
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
- Linux中安装配置hadoop集群详细步骤
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
- 国内最全最详细的Hadoop2.2.0集群的HA高可靠的最简单配置
- Hadoop完全分布式安装-高可用(HA)
- hadoop 三节点集群安装配置详细实例
- Hadoop2.2.0 HA高可用分布式集群搭建(hbase,hive,sqoop,spark)
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
- 完全分布式Hadoop集群的安装搭建和配置(4节点)