Apache Hadoop 分布式集群环境安装配置详细步骤
2018-02-08 10:36
976 查看
案例基于centos6.5安装hadoop2.6.4集群部署,使用两个节点作为集群环境,一个为Master节点,IP为192.168.168.139;另一个作为Slave1节点,IP为192.168.168.141一、准备工作(所有机器)1、创建hadoop用户,并修改/etc/sudoers文件赋予用户root权限 (直接用root用户也可以)
2、修改机器名称 # vi/etc/sysconfig/network hostname
3、关闭防火墙及其开机启动 # service iptables stop # chkconfigiptables off
查看状态# service iptablesstatus
关闭SELinux: vi /etc/selinux/config SELINUX=disabled
# 如果是非root用户操作,应优先对一些配置文件权限开放,linux的一些操作就不细讲。#
4、卸载原有openjdk;安装jdk1.7或1.8并配置环境变量
注意:安装一些常用服务及依赖,例如ssh、perl、psmisc等,根据个人不同机器情况,有些系统是最小化安装的,需要添加服务及依赖!
5、修改所有节点的名称与IP映射 # vim /etc/hosts
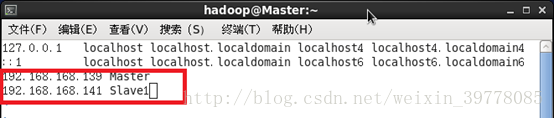
(注意:此处配置包含本节点及所有其他节点的IP主机映射,集群所有机器都要配置相同一份!)
测试互ping一下
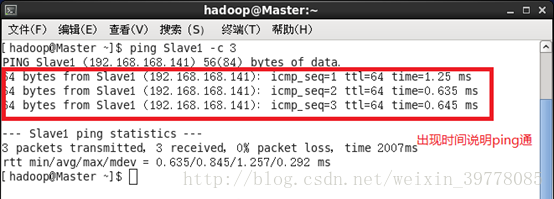
6、ssh无密登录(主要是master无密登录到其他节点)
首先:编辑sshd_config文件,去掉3个注释。(所有节点)
# vi /etc/ssh/sshd_config
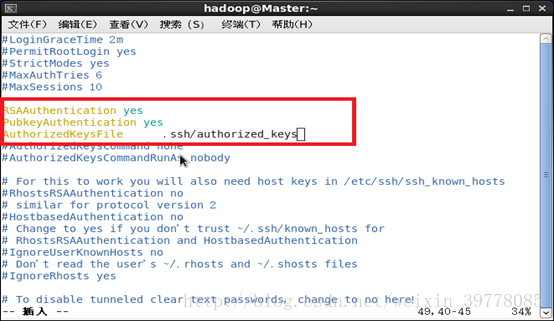
重启ssh服务:# service sshd restart
在Master机器上操作:
# cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
# rm ./id_rsa* # 删除之前生成的公匙(如果有)
在用户目录下: # cd /home/hadoop
# ssh-keygen -t rsa # 一直按回车就可以(3个回车)
# cat ./id_rsa.pub >>./authorized_keys #让Master节点无密登录本机(如果非当前用户操作,还需要对该文件赋予权限600)
# ssh Master #验证无密登录本地
(如果失败过或者进行过公钥删除等操作,有可能会报错:Agent admitted failure to sign using the key ,解决方法是通过ssh-add命令将私钥加进来。# ssh-add ~/.ssh/id_rsa)在 Master节点将上公匙传输到 Slave1节点:
# scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop
(或者在.ssh目录下执行: ssh-copy-id slave1 直接复制公钥到slave1,该操作之后在slave1上就不需要再进行认证。)
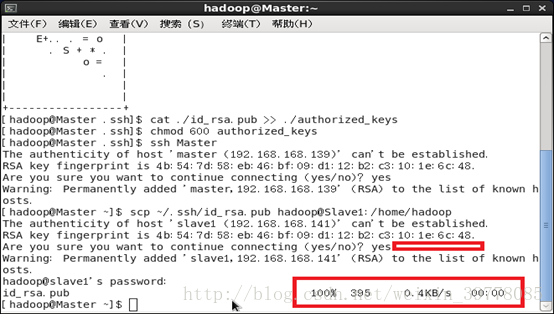
如果有多台几点,都要分发到所有节点。
在Slave1节点上操作:将ssh公钥加入授权认证文件(如果有多个Slave节点,都要进行远程传输和加入授权这两步操作!)
# mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略# cd /home/hadoop/ #进入传送文件所在目录# cat id_rsa.pub >>.ssh/authorized_keys #把公钥加入认证(注意,可以用复制方法进行操作,先把文件都放在一个文件夹下,通过cp命令覆盖。要在Slave上对认证文件进行权限处理,否则Master登录Slave需要密码!)# cd ~/.ssh # chmod 600 authorized_keys# rm ~/id_rsa.pub # 用完可以删掉

hadoop的安装包 hadoop-2.6.4.tar.gz 放在/home/hadoop/下载
# cd /home/hadoop/下载
# tar -zxf hadoop-2.6.4.tar.gz-C /usr/local # 解压复制到local路径下
# cd /usr/local # 进入安装路径
# mv ./hadoop-2.6.4/ ./hadoop #更改文件夹名称
# chown -R hadoop:hadoop ./hadoop #为用户赋权限
最后为方便启动命令,配置PATH变量:
将 Hadoop安装目录加入 PATH变量中,这样就可以在任意目录中直接使用 hadoo、hdfs等命令了,需要在 Master节点上进行配置。首先执行 vim ~/.bashrc,加入一行:
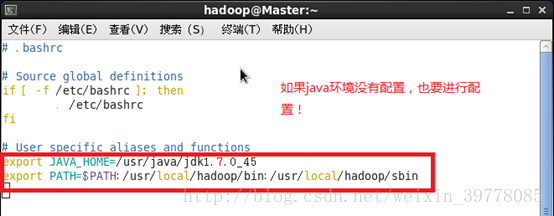
保存后重新加载文件: # source ~/.bashrc
二、配置集群/分布式环境:集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop中的5个配置文件,更多设置项参考网络,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
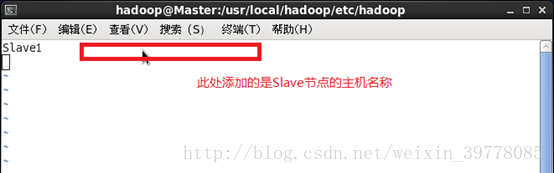
1、文件 slaves,将作为 DataNode的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master节点仅作为 NameNode使用。本案例让 Master节点仅作为 NameNode使用,因此将文件中原来的 localhost删除,只添加一行内容:Slave1。
2、修改文件core-site.xml配置

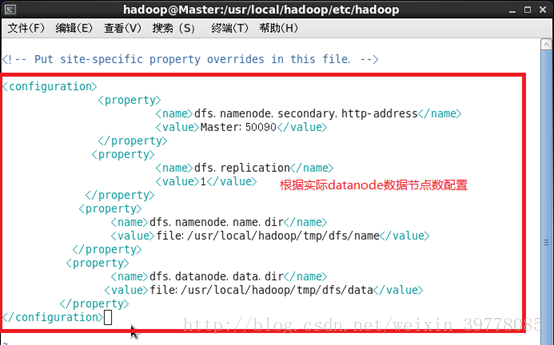
3、文件 hdfs-site.xml,dfs.replication一般设为 3,但本例只有一个 Slave节点,所以 dfs.replication的值还是设为 1(设定副本的数量,每个数据节点datanode只能存放一个副本,一般副本数量不超过节点数):
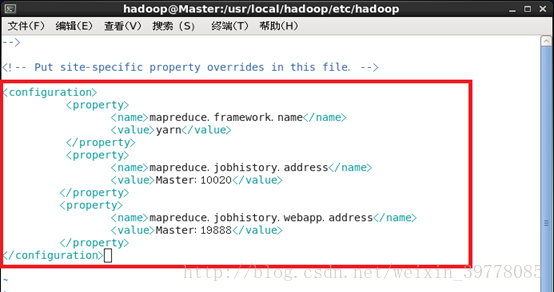
4、文件 mapred-site.xml (需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
# mv mapred-site.xml.template mapred-site.xml #在当前文件目录下执行
5、修改文件 yarn-site.xml:
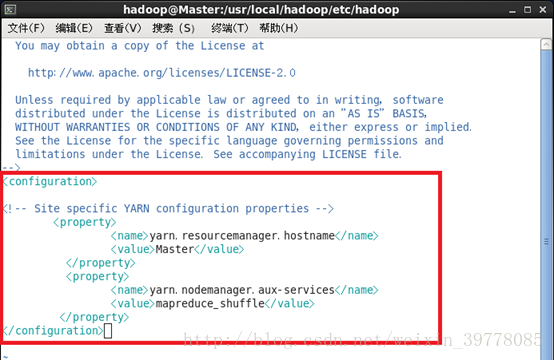
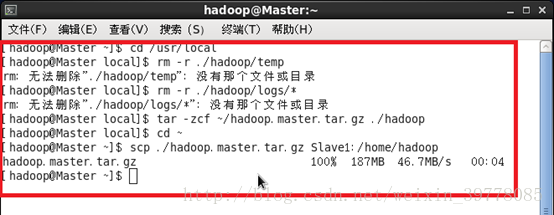
配置好后,(在master)将 Master上的 /usr/local/Hadoop文件夹复制到各个节点上。如果之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master节点上执行:
# cd /usr/local
# rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
# rm -r ./hadoop/logs/* # 删除日志文件
# tar -zcf~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
# cd ~
# scp ./hadoop.master.tar.gzSlave1:/home/hadoop # 传输复制
在 Slave1节点上执行:
# rm -r /usr/local/hadoop # 删掉旧的(如果存在)
# tar -zxf~/hadoop.master.tar.gz -C /usr/local # 解压复制到/usr/local
# chown -R hadoop:hadoop/usr/local/hadoop #为hadoop用户赋予文件夹权限
(如果有其他 Slave 节点,也要执行将hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。)
三、启动集群首次启动需要先在 Master节点执行 NameNode的格式化:# hdfs namenode -format # 首次运行需要执行初始化,之后不需要
出现以下状态说明成功。
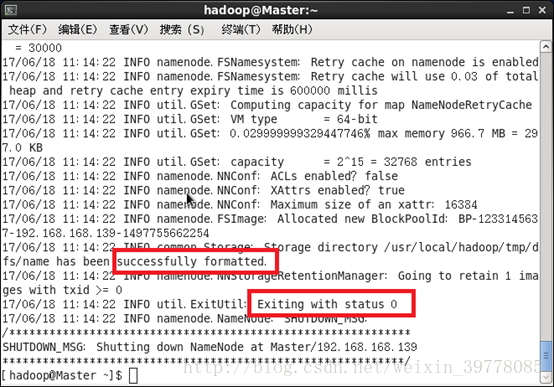
(需要在准备工作里关闭防火墙)
CentOS系统默认开启了防火墙,在开启 Hadoop集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping得通但 telnet端口不通,从而导致 DataNode启动了,但 Live datanodes为 0的情况
(注意:这里需要# vi/usr/local/hadoop/etc/hadoop/Hadoop-env.sh里的java路径该为绝对路径,所有节点都要改!否则会报错找不到java路径)初始化成功后接着可以启动 hadoop了,启动需要在 Master节点上进行:
# start-dfs.sh
# start-yarn.sh
# mr-jobhistory-daemon.shstart historyserver
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer进程:
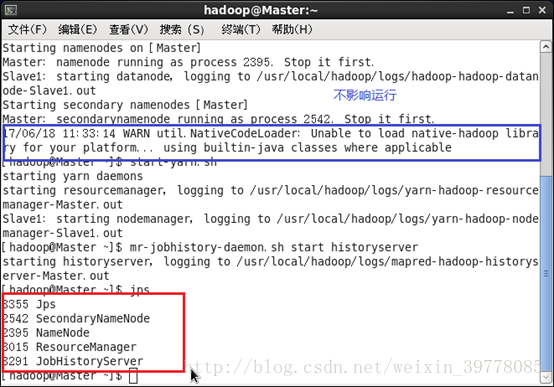
在 Slave节点可以看到 DataNode和 NodeManager进程:
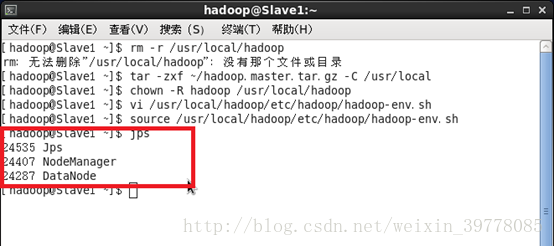
缺少任一进程都表示出错。另外还需要在 Master节点上通过命令 hdfs dfsadmin -report 查看 DataNode是否正常启动,如果 Live datanodes不为 0,则说明集群启动成功。例如我这边一共有 1个 Datanodes:
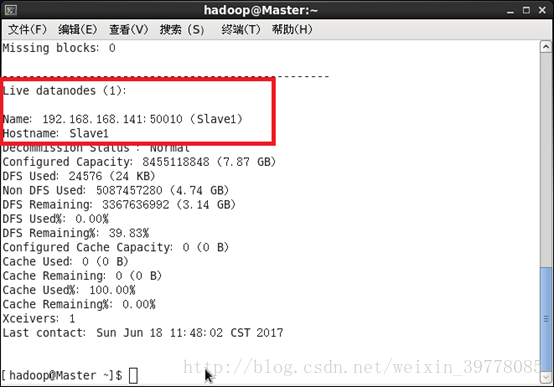
也可以通过 Web页面看到查看 DataNode和 NameNode 的状态:http://master:50070/。如果不成功,可以通过启动日志排查原因。
关闭 Hadoop集群也是在 Master节点上执行的:
# stop-yarn.sh
# stop-dfs.sh
# mr-jobhistory-daemon.sh stophistoryserver
至此,完成了 Hadoop的集群搭建与基本使用。

2、修改机器名称 # vi/etc/sysconfig/network hostname
3、关闭防火墙及其开机启动 # service iptables stop # chkconfigiptables off
查看状态# service iptablesstatus
关闭SELinux: vi /etc/selinux/config SELINUX=disabled
# 如果是非root用户操作,应优先对一些配置文件权限开放,linux的一些操作就不细讲。#
4、卸载原有openjdk;安装jdk1.7或1.8并配置环境变量
注意:安装一些常用服务及依赖,例如ssh、perl、psmisc等,根据个人不同机器情况,有些系统是最小化安装的,需要添加服务及依赖!
5、修改所有节点的名称与IP映射 # vim /etc/hosts
(注意:此处配置包含本节点及所有其他节点的IP主机映射,集群所有机器都要配置相同一份!)
测试互ping一下
6、ssh无密登录(主要是master无密登录到其他节点)
首先:编辑sshd_config文件,去掉3个注释。(所有节点)
# vi /etc/ssh/sshd_config
重启ssh服务:# service sshd restart
在Master机器上操作:
# cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
# rm ./id_rsa* # 删除之前生成的公匙(如果有)
在用户目录下: # cd /home/hadoop
# ssh-keygen -t rsa # 一直按回车就可以(3个回车)
# cat ./id_rsa.pub >>./authorized_keys #让Master节点无密登录本机(如果非当前用户操作,还需要对该文件赋予权限600)
# ssh Master #验证无密登录本地
(如果失败过或者进行过公钥删除等操作,有可能会报错:Agent admitted failure to sign using the key ,解决方法是通过ssh-add命令将私钥加进来。# ssh-add ~/.ssh/id_rsa)在 Master节点将上公匙传输到 Slave1节点:
# scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop
(或者在.ssh目录下执行: ssh-copy-id slave1 直接复制公钥到slave1,该操作之后在slave1上就不需要再进行认证。)
如果有多台几点,都要分发到所有节点。
在Slave1节点上操作:将ssh公钥加入授权认证文件(如果有多个Slave节点,都要进行远程传输和加入授权这两步操作!)
# mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略# cd /home/hadoop/ #进入传送文件所在目录# cat id_rsa.pub >>.ssh/authorized_keys #把公钥加入认证(注意,可以用复制方法进行操作,先把文件都放在一个文件夹下,通过cp命令覆盖。要在Slave上对认证文件进行权限处理,否则Master登录Slave需要密码!)# cd ~/.ssh # chmod 600 authorized_keys# rm ~/id_rsa.pub # 用完可以删掉
hadoop的安装包 hadoop-2.6.4.tar.gz 放在/home/hadoop/下载
# cd /home/hadoop/下载
# tar -zxf hadoop-2.6.4.tar.gz-C /usr/local # 解压复制到local路径下
# cd /usr/local # 进入安装路径
# mv ./hadoop-2.6.4/ ./hadoop #更改文件夹名称
# chown -R hadoop:hadoop ./hadoop #为用户赋权限
最后为方便启动命令,配置PATH变量:
将 Hadoop安装目录加入 PATH变量中,这样就可以在任意目录中直接使用 hadoo、hdfs等命令了,需要在 Master节点上进行配置。首先执行 vim ~/.bashrc,加入一行:
保存后重新加载文件: # source ~/.bashrc
二、配置集群/分布式环境:集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop中的5个配置文件,更多设置项参考网络,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
1、文件 slaves,将作为 DataNode的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master节点仅作为 NameNode使用。本案例让 Master节点仅作为 NameNode使用,因此将文件中原来的 localhost删除,只添加一行内容:Slave1。
2、修改文件core-site.xml配置
3、文件 hdfs-site.xml,dfs.replication一般设为 3,但本例只有一个 Slave节点,所以 dfs.replication的值还是设为 1(设定副本的数量,每个数据节点datanode只能存放一个副本,一般副本数量不超过节点数):
4、文件 mapred-site.xml (需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
# mv mapred-site.xml.template mapred-site.xml #在当前文件目录下执行
5、修改文件 yarn-site.xml:
配置好后,(在master)将 Master上的 /usr/local/Hadoop文件夹复制到各个节点上。如果之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master节点上执行:
# cd /usr/local
# rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
# rm -r ./hadoop/logs/* # 删除日志文件
# tar -zcf~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
# cd ~
# scp ./hadoop.master.tar.gzSlave1:/home/hadoop # 传输复制
在 Slave1节点上执行:
# rm -r /usr/local/hadoop # 删掉旧的(如果存在)
# tar -zxf~/hadoop.master.tar.gz -C /usr/local # 解压复制到/usr/local
# chown -R hadoop:hadoop/usr/local/hadoop #为hadoop用户赋予文件夹权限
(如果有其他 Slave 节点,也要执行将hadoop.master.tar.gz 传输到 Slave 节点、在 Slave 节点解压文件的操作。)
三、启动集群首次启动需要先在 Master节点执行 NameNode的格式化:# hdfs namenode -format # 首次运行需要执行初始化,之后不需要
出现以下状态说明成功。
(需要在准备工作里关闭防火墙)
CentOS系统默认开启了防火墙,在开启 Hadoop集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping得通但 telnet端口不通,从而导致 DataNode启动了,但 Live datanodes为 0的情况
(注意:这里需要# vi/usr/local/hadoop/etc/hadoop/Hadoop-env.sh里的java路径该为绝对路径,所有节点都要改!否则会报错找不到java路径)初始化成功后接着可以启动 hadoop了,启动需要在 Master节点上进行:
# start-dfs.sh
# start-yarn.sh
# mr-jobhistory-daemon.shstart historyserver
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer进程:
在 Slave节点可以看到 DataNode和 NodeManager进程:
缺少任一进程都表示出错。另外还需要在 Master节点上通过命令 hdfs dfsadmin -report 查看 DataNode是否正常启动,如果 Live datanodes不为 0,则说明集群启动成功。例如我这边一共有 1个 Datanodes:
也可以通过 Web页面看到查看 DataNode和 NameNode 的状态:http://master:50070/。如果不成功,可以通过启动日志排查原因。
关闭 Hadoop集群也是在 Master节点上执行的:
# stop-yarn.sh
# stop-dfs.sh
# mr-jobhistory-daemon.sh stophistoryserver
至此,完成了 Hadoop的集群搭建与基本使用。

相关文章推荐
- Hadoop2.6.4 HA 高可用分布式集群安装配置详细步骤
- 详细虚拟机hadoop集群环境安装步骤
- 从VMware虚拟机安装到hadoop集群环境配置详细说明
- hadoop-2.2.0伪分布式与(全分布集群安装于配置续,很详细的哦~)
- Hadoop 2.6 集群搭建从零开始之4 Hadoop的安装与配置(完全分布式环境)
- Linux中安装配置hadoop集群详细步骤
- 集群分布式 Hadoop安装详细步骤
- linux环境下安装redis详细步骤以及配置redis集群详细步骤
- Hadoop2.7.2 Centos 完全分布式集群环境搭建 (2) - Hadoop安装与配置(完全分布式)
- Hadoop分布式集群安装配置步骤
- Hadoop 2.6 集群搭建从零开始之3 Hadoop的安装与配置(伪分布式环境)
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
- hadoop - hadoop2.6 分布式 - 集群环境搭建 - JDK安装配置和SSH安装配置与免密码登陆(集群中)
- hadoop - hadoop2.6 分布式 - 集群环境搭建 - Hadoop 2.6 分布式安装配置与启动
- (超详细)从零开始安装与配置hadoop完全分布式环境
- Hadoop集群安装详细步骤|Hadoop安装配置
- 在虚拟机上安装5节点Hadoop分布式集群(HA)-环境准备
- Linux下Hadoop集群安装详细步骤
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~) .
- 安装java 配置java环境 超级详细步骤有图有真相