Hulu机器学习问题与解答系列 | 第八弹:强化学习 (二)
2018-02-27 19:27
288 查看
答应你们的解答部分来啦!
“视频游戏里的强化学习”
场景描述
游戏是强化学习最有代表性也是最合适的应用领域之一,其几乎涵盖了强化学习所有的要素,例如环境:游戏本身的状态,动作:用户操作,机器人:程序,回馈:得分、输赢等。通过输入原始像素来玩视频游戏,是人工智能成熟的标志之一。雅达利(Atari)是20世纪七八十年代红极一时的电脑游戏,类似于国内的红白机游戏,但是画面元素要更简单一些。它的模拟器相对成熟简单,使用雅达利游戏来测试强化学习,是非常合适的。应用场景可以描述为:在离散的时间轴上,每个时刻你可以得到当前的游戏画面,选择向游戏机发出一个指令(上下左右,开火等),然后得到一个回馈(reward)。由于基于原始像素的强化学习对应的状态空间巨大,没有办法直接使用传统的方法。于是,2013年DeepMind提出了深度强化学习模型,开始了深度学习和强化学习的结合[1]。
传统的强化学习主要使用Q-learning,而深度强化学习也使用Q-learning为基本框架,把Q-learning的对应步骤改为深度形式,并引入了一些技巧,例如经验重放(experience replay)来加快收敛以及提高泛化能力。
问题描述
什么是深度强化学习,它和传统的强化学习有什么不同,如何用它来玩视频游戏?
背景知识:强化学习,Q-learning
解答与分析

先来看看经典的Q-learning:

为了能与Deep Q-learning作对比,我们把最后一步换成下面等价的描述:

深度的Q-learning(其中红色部分为和传统Q-learning不同的部分):


不同点主要在子步骤的细节上:
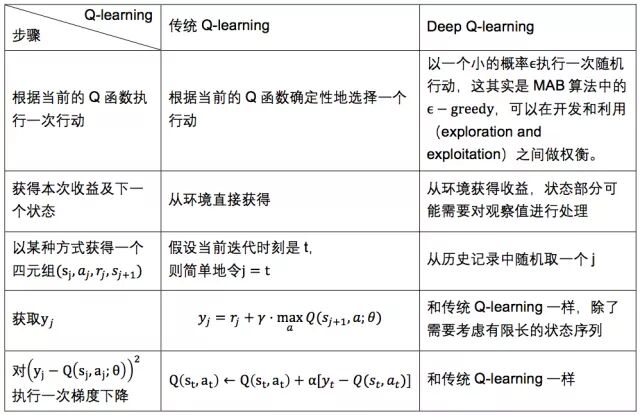
需要注意的是,传统的Q-learning直接从环境观测获得当前状态,而在Deep Q-learning中,往往需要对观测的结果进行某些处理来获得Q函数的输入状态。在用Deep Q-learning玩Atari游戏中,是这样对观察值进行处理的。

总结
本章介绍了强化学习中的三种方法,还有一些其他方法和其类似,但是思想是相同的。
扩展阅读:
[1] Antonoglou, I., Graves, A., Kavukcuoglu, K., Mnih, V., Riedmiller, M.A., Silver, D., & Wierstra, D. (2013). Playing Atari with Deep Reinforcement Learning. CoRR, abs/1312.5602.
下一题预告
【循环神经网络】
场景描述
循环神经网络(Recurrent Neural Network)是一种主流的深度学习模型,最早在20世纪80年代被提出 ,目的是建模序列化的数据。我们知道,传统的前馈神经网络一般的输入都是一个定长的向量,无法处理变长的序列信息,即使通过一些方法把序列处理成定长的向量,模型也很难捕捉序列中的长距离依赖关系。而RNN通过将神经元串行起来处理序列化的数据,比如文本的词序列、音频流和视频流序列等。由于每个神经元能用它的内部变量保存之前输入的序列信息,使得整个序列可以被浓缩成抽象的表示,并可以据此进行分类或生成新的序列。近年来,得益于计算能力的大幅提升和网络设计的改进(LSTM、GRU、Attention机制等),RNN在很多领域取得了突破性的进展。比如机器翻译、序列标注、图像描述、视频推荐、智能聊天机器人、自动作词作曲等,给我们的日常生活带来了不少便利和乐趣。
问题描述
什么是循环神经网络?如何用它产生文本表示?
RNN为什么会出现梯度的消失或爆炸?有什么样的改进方案?
“视频游戏里的强化学习”
场景描述
游戏是强化学习最有代表性也是最合适的应用领域之一,其几乎涵盖了强化学习所有的要素,例如环境:游戏本身的状态,动作:用户操作,机器人:程序,回馈:得分、输赢等。通过输入原始像素来玩视频游戏,是人工智能成熟的标志之一。雅达利(Atari)是20世纪七八十年代红极一时的电脑游戏,类似于国内的红白机游戏,但是画面元素要更简单一些。它的模拟器相对成熟简单,使用雅达利游戏来测试强化学习,是非常合适的。应用场景可以描述为:在离散的时间轴上,每个时刻你可以得到当前的游戏画面,选择向游戏机发出一个指令(上下左右,开火等),然后得到一个回馈(reward)。由于基于原始像素的强化学习对应的状态空间巨大,没有办法直接使用传统的方法。于是,2013年DeepMind提出了深度强化学习模型,开始了深度学习和强化学习的结合[1]。
传统的强化学习主要使用Q-learning,而深度强化学习也使用Q-learning为基本框架,把Q-learning的对应步骤改为深度形式,并引入了一些技巧,例如经验重放(experience replay)来加快收敛以及提高泛化能力。
问题描述
什么是深度强化学习,它和传统的强化学习有什么不同,如何用它来玩视频游戏?
背景知识:强化学习,Q-learning
解答与分析
先来看看经典的Q-learning:
为了能与Deep Q-learning作对比,我们把最后一步换成下面等价的描述:
深度的Q-learning(其中红色部分为和传统Q-learning不同的部分):
不同点主要在子步骤的细节上:
需要注意的是,传统的Q-learning直接从环境观测获得当前状态,而在Deep Q-learning中,往往需要对观测的结果进行某些处理来获得Q函数的输入状态。在用Deep Q-learning玩Atari游戏中,是这样对观察值进行处理的。
总结
本章介绍了强化学习中的三种方法,还有一些其他方法和其类似,但是思想是相同的。
扩展阅读:
[1] Antonoglou, I., Graves, A., Kavukcuoglu, K., Mnih, V., Riedmiller, M.A., Silver, D., & Wierstra, D. (2013). Playing Atari with Deep Reinforcement Learning. CoRR, abs/1312.5602.
下一题预告
【循环神经网络】
场景描述
循环神经网络(Recurrent Neural Network)是一种主流的深度学习模型,最早在20世纪80年代被提出 ,目的是建模序列化的数据。我们知道,传统的前馈神经网络一般的输入都是一个定长的向量,无法处理变长的序列信息,即使通过一些方法把序列处理成定长的向量,模型也很难捕捉序列中的长距离依赖关系。而RNN通过将神经元串行起来处理序列化的数据,比如文本的词序列、音频流和视频流序列等。由于每个神经元能用它的内部变量保存之前输入的序列信息,使得整个序列可以被浓缩成抽象的表示,并可以据此进行分类或生成新的序列。近年来,得益于计算能力的大幅提升和网络设计的改进(LSTM、GRU、Attention机制等),RNN在很多领域取得了突破性的进展。比如机器翻译、序列标注、图像描述、视频推荐、智能聊天机器人、自动作词作曲等,给我们的日常生活带来了不少便利和乐趣。
问题描述
什么是循环神经网络?如何用它产生文本表示?
RNN为什么会出现梯度的消失或爆炸?有什么样的改进方案?

相关文章推荐
- Hulu机器学习问题与解答系列 | 第八弹:强化学习 (一)
- Hulu机器学习问题与解答系列 | 第七弹:非监督学习算法与评估
- Hulu机器学习问题与解答系列 | 第一弹:模型评估
- Hulu机器学习问题与解答系列 | 二十三:神经网络训练中的批量归一化
- Hulu机器学习问题与解答系列 | 第六弹:PCA算法
- Hulu机器学习问题与解答系列 | 十一:Seq2Seq
- Hulu机器学习问题与解答系列 | 第二弹: SVM模型
- Hulu机器学习问题与解答系列 | 十八:SVM – 核函数与松弛变量
- Hulu机器学习问题与解答系列 | 第九弹:循环神经网络
- Hulu机器学习问题与解答系列 | 二十一:分类、排序、回归模型的评估
- Hulu机器学习问题与解答系列 | 十九:主题模型
- Hulu机器学习问题与解答系列 | 二十四:随机梯度下降法
- Hulu机器学习问题与解答系列 | 十六:经典优化算法
- Hulu机器学习问题与解答系列 | 十二:注意力机制
- Hulu机器学习问题与解答系列 | 第五弹:余弦距离
- Hulu机器学习问题与解答系列 | 第四弹:不均衡样本集的处理
- Hulu机器学习问题与解答系列 | 二十:PCA 最小平方误差理论
- Hulu机器学习问题与解答系列 | 十四:如何对高斯分布进行采样
- HuLu机器学习问题与解答系列(1-8)
- Hulu机器学习问题与解答系列 | 十三:集成学习