Hulu机器学习问题与解答系列 | 第一弹:模型评估
2018-02-27 19:15
225 查看
昨天的序言引发了许多关注
今天我们就推出第一题
【模型评估】
引言
“没有测量,就没有科学。”这是科学家门捷列夫的名言。在计算机科学中,特别是在机器学习的领域,对模型的测量和评估同样至关重要。只有选择与问题相匹配的评估方法,我们才能够快速的发现在模型选择和训练过程中可能出现的问题,迭代地对模型进行优化。
模型评估主要分为离线评估和在线评估两个阶段,针对分类、排序、回归、序列预测等不同类型的机器学习问题,评价指标的选择也有所不同,是否知道每种评估指标的精确定义,如何有针对性的选择合适的评估指标,是否能够根据评估指标的反馈进行模型调整,是机器学习模型评估阶段的关键问题,也是一名合格的算法工程师应具备的基本功。
在所有的模型评估指标中,ROC曲线和AUC值无疑是最常用的指标之一,我们模型评估的第一道面试题也是基于ROC曲线提出的。
问题
在一个二值分类问题中,
如何绘制模型的ROC曲线并计算相应的AUC值?
ROC曲线相比PR(Precision-Recall)曲线有什么优点?
【问题背景】
二值分类器(binaryclassifier)是机器学习领域中最常见也是应用最为广泛的分类器。评价二值分类器的指标很多,比如precision,recall,F-score,PR曲线等,相比较而言,基于ROC曲线的AUC值有很多突出的优点(本题第二问会做相关解释),经常作为评估二值分类器最重要的指标之一。下面我们详细解答一下这道面试题。
【解答】
ROC曲线的全称是theReceiver Operating Characteristic曲线,中文名为“受试者工作特征曲线”。AUC全称是Area under the Curve,曲线下面积,这里的“曲线”一般就是指ROC曲线。所以这道面试题第一问的重点就绘制出ROC曲线,基于ROC曲线计算面积的方法是显然的。
ROC曲线的横坐标为falsepositive rate(FPR),中文一般称为假阳性率,纵坐标为truepositive rate(TPR),中文一般称为真阳性率。FPR和TPR的计算方法如下:
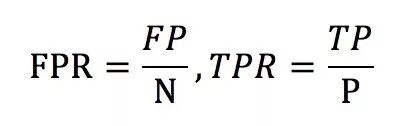
上式中,P指的是所有样本中,真正的正样本的数量,N指的是真正的负样本的数量。TP指的是P个正样本中,分类器把其中TP个预测为正。FP指的是,N个负样本中,分类器把其中FP个样本误判成了正样本。
只看定义确实有点绕,为了更直观的说明这个问题,我们举一个医院诊断病人的例子。假设有10位疑似癌症患者,其中有3位很不幸确实患了癌症(P=3),另外7位不是癌症患者(N=7)。医院对这10位疑似患者做了诊断,也确实发现了3位患了癌症,但这3位患者中,只有2位是真正的患者(TP=2)。那么真阳性率TPR=TP/P=2/3。而对于7位非癌症患者来说,有一位很不幸被误诊为癌症患者(FP=1),那么假阳性率FPR=FP/N=1/7。对于“医院”这个分类器来说,这组分类结果就对应ROC曲线上的一个点(1/7,2/3)。那么ROC曲线上的其他点都是怎样生成的呢?
事实上,ROC曲线是通过不断移动分类器的“截断点”来生成所有关键点的,我们通过下面的例子来解释“截断点”的概念。
在一个二值分类问题中,我们构建的模型输出一般都是预测样本为正例的概率。假设我们的测试集中有20个样本,模型的输出如下图所示,图中第一列为样本序号,Class为样本的真实标签,Score为模型输出的样本为正的预测概率,样本按照预测概率从高到低排序。
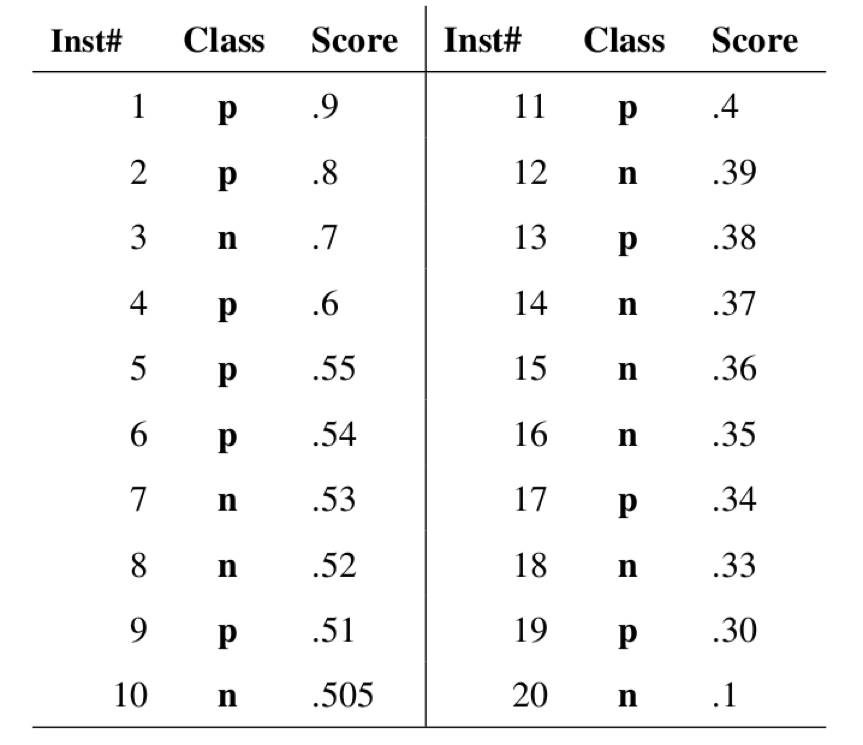
图片来自Fawcett,Tom. "An introduction to ROC analysis." Pattern recognition letters27.8 (2006): 861-874.
在预测样本为正负例的时候,我们需要指定一个阈值。大于等于这个阈值的样本都会预测为正样本。比如指定0.9为阈值,那么只有第一个样本会被预测为正例,其他全部都是负例。上面所说的“截断点”指的就是区分正负预测结果的阈值。我们动态调整这个截断点,从最高的得分开始(实际是从正无穷开始开始,对应着ROC曲线的零点),逐渐调整到最低得分,每一个截断点都会对应一个FPR和TPR,在ROC图上绘制出每个截断点对应的位置,再连接每个点即得到最终的ROC曲线。
就本例来说,当截断点选择为正无穷时,模型把全部样本预测为负例,那么FP和TP必然都为0,FPR和TPR也都为0,显然,曲线的第一个点就是(0,0)。当把截断点调整为0.9时,模型预测1号样本为正样本,并且该样本确实是正样本,因此,TP=1,20个样本中,所有正例数量为P=10,故TPR=TP/P=1/10;这里没有预测错的正样本,即FP=0,负样本总数N=10,故FPR=FP/N=0/10=0。对应着ROC图上的点(0,0.1),依次调整截断点,直到画出全部的关键点,再连接关键点即得到了下图所示的ROC曲线。
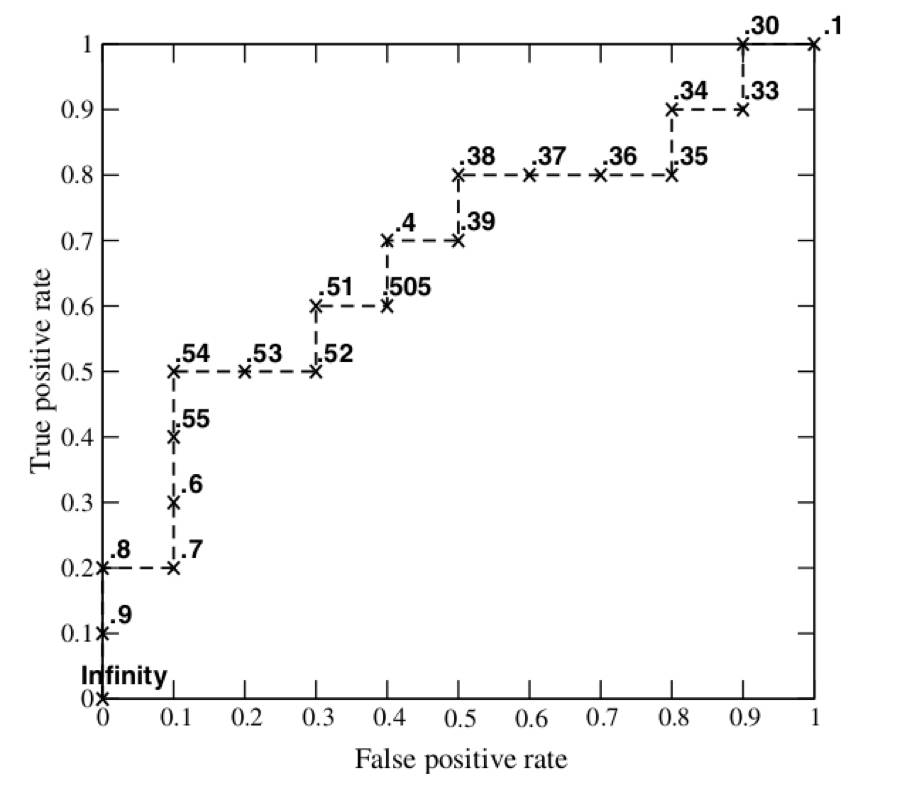
图片来自Fawcett, Tom. "An introduction to ROCanalysis." Pattern recognition letters 27.8 (2006): 861-874.
其实,绘制ROC曲线有一个更直观的方法,我们首先根据样本标签统计出正负样本的数量,假设正样本数量为P,负样本数量为N。下一步就把横轴的刻度间隔设置为1/N,纵轴的刻度间隔设置为1/P。再根据模型预测结果将样本进行排序后,从高到低遍历样本,与此同时从零点开始绘制ROC曲线,每遇到一个正样本就沿纵轴正方向绘制一个单位长度的曲线,每遇到一个负样本就延横轴正方向绘制一个单位长度的曲线,直到遍历完所有样本,曲线也最终终结在(1,1)这个点。
有了ROC曲线,计算AUC只要沿着横轴做积分就可以了。由于ROC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成1-p就可以得到一个更好的分类器),所以AUC的取值一般在0.5和1之间。显然,AUC越大,分类器越可能把真正的正样本排在前面,分类器性能越好。
ROC曲线相比PR(Precision-Recall)曲线有什么优点?
除了ROC曲线外,还有很多评估分类模型的指标,PR曲线也是经常使用的指标之一。与ROC曲线不同的是,PR曲线的横坐标是Recall,纵坐标是Precision。
ROC曲线相比PR曲线有一个非常好的特性:就是当正负样本分布发生变化的时候,ROC曲线的形状能够基本保持不变。而PR曲线的形状会发生较剧烈的变化。
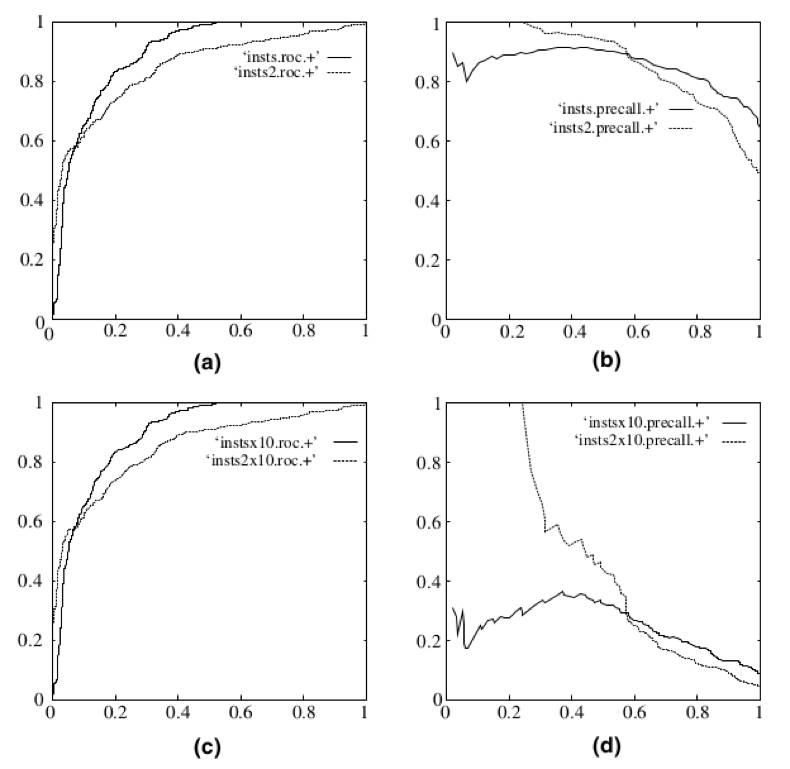
图片来自Fawcett, Tom. "An introduction to ROCanalysis." Pattern recognition letters 27.8 (2006): 861-874.
举例来说,上图是ROC曲线和PR曲线的一张对比图,左边两幅是ROC曲线,右边两幅是PR曲线。下面两幅图是将测试集的负样本数量增加10倍后的结果。可以明显看出,PR曲线发生了明显的变化,而ROC曲线形状基本不变。这就让ROC曲线能够尽量屏蔽测试集选择带来的干扰,更加客观的衡量模型本身的性能。
这样的优点有什么实际意义呢?因为在很多实际问题中,正负样本数量往往很不均衡,比如计算广告领域经常涉及的转化率模型,正样本的数量往往是负样本数量的1/1000甚至1/10000,这个时候选择不同的测试集,PR曲线的变化就会非常大,这显然不利于评估模型本身的性能。而ROC曲线则能够更加稳定的反应模型本身的好坏,适用的场景更多,广泛适用于排序、推荐、广告等领域。
下一题预告
【SVM模型】
引言
SVM(Support Vector Machine, 支持向量机)是众多监督式学习方法中十分出色的一种,几乎所有的讲述经典机器学习方法的教材都会介绍。以它为模型,可以考察机器学习各个方面的知识,也是面试题目中常见的模型,SVM的第一道面试题就是考察模型推导的基础知识。
问题
在空间上线性可分的两类点,分别向SVM分类的超平面上做投影,这些点在超平面上的投影仍然是线性可分的吗?能否证明你的观点?
今天我们就推出第一题
【模型评估】
引言
“没有测量,就没有科学。”这是科学家门捷列夫的名言。在计算机科学中,特别是在机器学习的领域,对模型的测量和评估同样至关重要。只有选择与问题相匹配的评估方法,我们才能够快速的发现在模型选择和训练过程中可能出现的问题,迭代地对模型进行优化。
模型评估主要分为离线评估和在线评估两个阶段,针对分类、排序、回归、序列预测等不同类型的机器学习问题,评价指标的选择也有所不同,是否知道每种评估指标的精确定义,如何有针对性的选择合适的评估指标,是否能够根据评估指标的反馈进行模型调整,是机器学习模型评估阶段的关键问题,也是一名合格的算法工程师应具备的基本功。
在所有的模型评估指标中,ROC曲线和AUC值无疑是最常用的指标之一,我们模型评估的第一道面试题也是基于ROC曲线提出的。
问题
在一个二值分类问题中,
如何绘制模型的ROC曲线并计算相应的AUC值?
ROC曲线相比PR(Precision-Recall)曲线有什么优点?
【问题背景】
二值分类器(binaryclassifier)是机器学习领域中最常见也是应用最为广泛的分类器。评价二值分类器的指标很多,比如precision,recall,F-score,PR曲线等,相比较而言,基于ROC曲线的AUC值有很多突出的优点(本题第二问会做相关解释),经常作为评估二值分类器最重要的指标之一。下面我们详细解答一下这道面试题。
【解答】
ROC曲线的全称是theReceiver Operating Characteristic曲线,中文名为“受试者工作特征曲线”。AUC全称是Area under the Curve,曲线下面积,这里的“曲线”一般就是指ROC曲线。所以这道面试题第一问的重点就绘制出ROC曲线,基于ROC曲线计算面积的方法是显然的。
ROC曲线的横坐标为falsepositive rate(FPR),中文一般称为假阳性率,纵坐标为truepositive rate(TPR),中文一般称为真阳性率。FPR和TPR的计算方法如下:
上式中,P指的是所有样本中,真正的正样本的数量,N指的是真正的负样本的数量。TP指的是P个正样本中,分类器把其中TP个预测为正。FP指的是,N个负样本中,分类器把其中FP个样本误判成了正样本。
只看定义确实有点绕,为了更直观的说明这个问题,我们举一个医院诊断病人的例子。假设有10位疑似癌症患者,其中有3位很不幸确实患了癌症(P=3),另外7位不是癌症患者(N=7)。医院对这10位疑似患者做了诊断,也确实发现了3位患了癌症,但这3位患者中,只有2位是真正的患者(TP=2)。那么真阳性率TPR=TP/P=2/3。而对于7位非癌症患者来说,有一位很不幸被误诊为癌症患者(FP=1),那么假阳性率FPR=FP/N=1/7。对于“医院”这个分类器来说,这组分类结果就对应ROC曲线上的一个点(1/7,2/3)。那么ROC曲线上的其他点都是怎样生成的呢?
事实上,ROC曲线是通过不断移动分类器的“截断点”来生成所有关键点的,我们通过下面的例子来解释“截断点”的概念。
在一个二值分类问题中,我们构建的模型输出一般都是预测样本为正例的概率。假设我们的测试集中有20个样本,模型的输出如下图所示,图中第一列为样本序号,Class为样本的真实标签,Score为模型输出的样本为正的预测概率,样本按照预测概率从高到低排序。
图片来自Fawcett,Tom. "An introduction to ROC analysis." Pattern recognition letters27.8 (2006): 861-874.
在预测样本为正负例的时候,我们需要指定一个阈值。大于等于这个阈值的样本都会预测为正样本。比如指定0.9为阈值,那么只有第一个样本会被预测为正例,其他全部都是负例。上面所说的“截断点”指的就是区分正负预测结果的阈值。我们动态调整这个截断点,从最高的得分开始(实际是从正无穷开始开始,对应着ROC曲线的零点),逐渐调整到最低得分,每一个截断点都会对应一个FPR和TPR,在ROC图上绘制出每个截断点对应的位置,再连接每个点即得到最终的ROC曲线。
就本例来说,当截断点选择为正无穷时,模型把全部样本预测为负例,那么FP和TP必然都为0,FPR和TPR也都为0,显然,曲线的第一个点就是(0,0)。当把截断点调整为0.9时,模型预测1号样本为正样本,并且该样本确实是正样本,因此,TP=1,20个样本中,所有正例数量为P=10,故TPR=TP/P=1/10;这里没有预测错的正样本,即FP=0,负样本总数N=10,故FPR=FP/N=0/10=0。对应着ROC图上的点(0,0.1),依次调整截断点,直到画出全部的关键点,再连接关键点即得到了下图所示的ROC曲线。
图片来自Fawcett, Tom. "An introduction to ROCanalysis." Pattern recognition letters 27.8 (2006): 861-874.
其实,绘制ROC曲线有一个更直观的方法,我们首先根据样本标签统计出正负样本的数量,假设正样本数量为P,负样本数量为N。下一步就把横轴的刻度间隔设置为1/N,纵轴的刻度间隔设置为1/P。再根据模型预测结果将样本进行排序后,从高到低遍历样本,与此同时从零点开始绘制ROC曲线,每遇到一个正样本就沿纵轴正方向绘制一个单位长度的曲线,每遇到一个负样本就延横轴正方向绘制一个单位长度的曲线,直到遍历完所有样本,曲线也最终终结在(1,1)这个点。
有了ROC曲线,计算AUC只要沿着横轴做积分就可以了。由于ROC曲线一般都处于y=x这条直线的上方(如果不是的话,只要把模型预测的概率反转成1-p就可以得到一个更好的分类器),所以AUC的取值一般在0.5和1之间。显然,AUC越大,分类器越可能把真正的正样本排在前面,分类器性能越好。
ROC曲线相比PR(Precision-Recall)曲线有什么优点?
除了ROC曲线外,还有很多评估分类模型的指标,PR曲线也是经常使用的指标之一。与ROC曲线不同的是,PR曲线的横坐标是Recall,纵坐标是Precision。
ROC曲线相比PR曲线有一个非常好的特性:就是当正负样本分布发生变化的时候,ROC曲线的形状能够基本保持不变。而PR曲线的形状会发生较剧烈的变化。
图片来自Fawcett, Tom. "An introduction to ROCanalysis." Pattern recognition letters 27.8 (2006): 861-874.
举例来说,上图是ROC曲线和PR曲线的一张对比图,左边两幅是ROC曲线,右边两幅是PR曲线。下面两幅图是将测试集的负样本数量增加10倍后的结果。可以明显看出,PR曲线发生了明显的变化,而ROC曲线形状基本不变。这就让ROC曲线能够尽量屏蔽测试集选择带来的干扰,更加客观的衡量模型本身的性能。
这样的优点有什么实际意义呢?因为在很多实际问题中,正负样本数量往往很不均衡,比如计算广告领域经常涉及的转化率模型,正样本的数量往往是负样本数量的1/1000甚至1/10000,这个时候选择不同的测试集,PR曲线的变化就会非常大,这显然不利于评估模型本身的性能。而ROC曲线则能够更加稳定的反应模型本身的好坏,适用的场景更多,广泛适用于排序、推荐、广告等领域。
下一题预告
【SVM模型】
引言
SVM(Support Vector Machine, 支持向量机)是众多监督式学习方法中十分出色的一种,几乎所有的讲述经典机器学习方法的教材都会介绍。以它为模型,可以考察机器学习各个方面的知识,也是面试题目中常见的模型,SVM的第一道面试题就是考察模型推导的基础知识。
问题
在空间上线性可分的两类点,分别向SVM分类的超平面上做投影,这些点在超平面上的投影仍然是线性可分的吗?能否证明你的观点?

相关文章推荐
- Hulu机器学习问题与解答系列 | 二十一:分类、排序、回归模型的评估
- Hulu机器学习问题与解答系列 | 第七弹:非监督学习算法与评估
- Hulu机器学习问题与解答系列 | 十九:主题模型
- Hulu机器学习问题与解答系列 | 第二弹: SVM模型
- Hulu机器学习问题与解答系列 | 第五弹:余弦距离
- Hulu机器学习问题与解答系列 | 十二:注意力机制
- Hulu机器学习问题与解答系列 | 第六弹:PCA算法
- Hulu机器学习问题与解答系列 | 十三:集成学习
- Hulu机器学习问题与解答系列 | 十四:如何对高斯分布进行采样
- 周志华《机器学习》课后习题解答系列(三):Ch2 - 模型评估与选择
- Hulu机器学习问题与解答系列 | 第八弹:强化学习 (一)
- Hulu机器学习问题与解答系列 | 第八弹:强化学习 (二)
- Hulu机器学习问题与解答系列 | 十八:SVM – 核函数与松弛变量
- Hulu机器学习问题与解答系列 | 十六:经典优化算法
- Hulu机器学习问题与解答系列 | 十七:随机梯度下降算法之经典变种
- HuLu机器学习问题与解答系列(1-8)
- Hulu机器学习问题与解答系列 | 二十:PCA 最小平方误差理论
- Hulu机器学习问题与解答系列 | 第九弹:循环神经网络
- Hulu机器学习问题与解答系列 | 二十二:特征工程—结构化数据
- Hulu机器学习问题与解答系列 | 第三弹: 优化简介