Hulu机器学习问题与解答系列 | 第七弹:非监督学习算法与评估
2018-02-27 19:24
477 查看
听说,Hulu机器学习与冬日的周末更配噢~
你可以点击菜单栏的“机器学习”,回顾本系列前几期的全部内容,并留言发表你的感悟与想法。
同时,为使大家更好地了解Hulu,菜单“关于Hulu”也做了相应调整,好奇宝宝们,牌子翻起来吧!
今天的内容是
【非监督学习算法与评估】
场景描述
人具有很强的归纳思考能力,善于从一大堆碎片似的事实或者数据中寻找普遍规律,并得到具有逻辑性的结论。以用户观看视频的行为为例,可以存在多种直观的归纳方式,比如从观看内容的角度看,有喜欢看动画片的,有喜欢看偶像剧的,有喜欢看科幻片的等等;从使用设备的角度看,有喜欢在台式电脑上观看的,有喜欢手机或者平板便携式设备上观看的,还有喜欢在电视等大屏幕上观看的;从使用习惯上看,有喜欢傍晚观看的,有喜欢中午时段观看的,有每天都观看的用户,也有只在周末观看的用户,等等。对所有用户进行有效的分组对于理解用户并推荐给用户合适的内容是重要的。通常这类问题没有观测数据的标签或者分组信息,需要通过算法模型来寻求数据内在的结构和模式 。
问题
以聚类算法为例,假设没有外部标签数据,如何区分两个无监督学习(聚类)算法性的优劣呢?
背景知识:非监督学习,常见聚类算法
解答与分析
场景描述中的例子就是一个典型的聚类问题,从中可以看出,数据的聚类依赖于需求的定义,同时也依赖于分类数据的特征度量以及数据相似性的方法。相比于监督式学习,非监督学习通常没有正确答案,算法模型的设计直接影响最终的输出和性能,需要通过多次迭代的方法寻找模型的最优的参数。因此了解常见数据簇的特点和常见聚类算法的特点,对寻求评估不同聚类算法性能的方法有很大的帮助。
常见数据簇的特点:
以中心定义的数据簇:这类数据集合倾向于球形分布,通常中心被定义为质心,即此数据簇中所有点的平均值。集合中的数据到中心的距离相比到其它簇中心的距离更近;
以密度定义的数据簇:这类数据集合呈现和周围数据簇明显不同的密度,或稠密或稀疏。当数据簇不规则或互相盘绕,并且有噪声和离群点时,常常使用基于密度的簇定义;
以连通定义的数据簇:这类数据集合中的数据点和数据点之间有连接关系,整个数据簇表现为图结构,该定义对不规则形状或者缠绕的的数据簇有效;
以概念定义的数据簇:这类数据集合中的所有数据点具有某种共同性质。
常见的聚类算法的特点:
划分聚类:将数据对象划分成互不重叠的数据簇,其中每个数据点恰在一个数据簇中;
层次聚类:数据簇可以具有子簇,具有多个(嵌套)子簇的数据簇可以表示为树状结构;
模糊聚类:每个数据点均以0~1的隶属权值属于某个数据簇;
完全/不完全聚类:是否对所有数据点都指派一个数据簇。
由于数据以及需求的多样性,没有一种算法能够适应所有的数据类型、簇和应用,似乎每种情况都可能需要一种不同的评估度量。例如,K均值聚类通常需要用SSE (Sum of Square Error) 来评估,但是基于密度的数据簇可以不必是球形,SSE则完全失效。在许多情况下,判断聚类算法结果的好坏最终强烈依赖主观解释。尽管如此,聚类算法的评估还是必须的,它是聚类分析中重要部分之一 。
对聚类算法优劣的评估通常可以总结为对以下五个方面的分析:
辨识数据中是否存在非随机簇结构的能力;
辨识数据中正确数据簇的能力;
评估数据被正确聚类的能力;
辨识两个数据簇之间优劣的能力;
评估与客观数据集之间的差异;
假设存在外部标注数据的支持,那么第5点将转化为监督学习的问题,直接度量聚类算法发现的聚类结构与标注数据的结构匹配程度即可。假设不存在外部标注数据,基于以上所列1~4点,可以如下图1~5所示,测试聚类算法对不同类型数据簇的聚类能力:
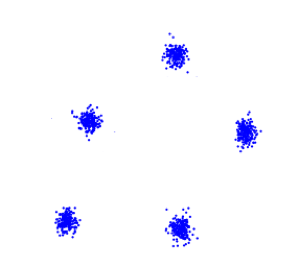
图1. 观察误差是否随聚类类别数量的增加而单调变化
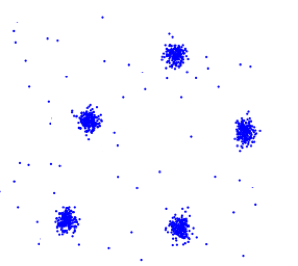
图2. 观察误差对聚类结果的影响
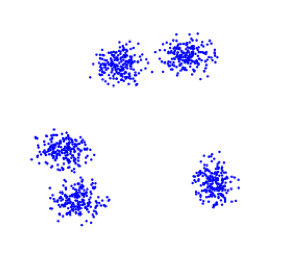
图3. 观察近邻数据簇的聚类准确性
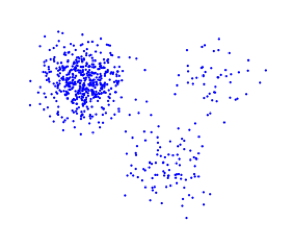
图4. 观察聚类算法在处理较大的数据密度差异时的性能
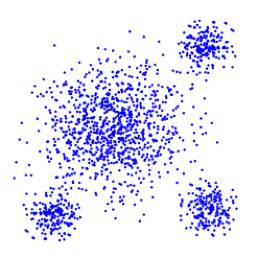
图5. 观察处理不同大小数据种类时的聚类准确度
扩展问题
在以上的回答中介绍了五种评估两个聚类算法性能优劣的,那么具体而言有哪些常见的指标可以用来计算和辨识聚类算法优劣呢?给出几种可能的数据簇形态,定义评估指标可以展现面试者实际解决和分析问题的能力。事实上测量指标可以有很多种,以下列出了三个在数据紧凑性或数据簇可分离程度上的度量,更多指标则请参考文献[1],具体描述如下:
均方根标准偏差 (RMSSTD),衡量聚类同质性:
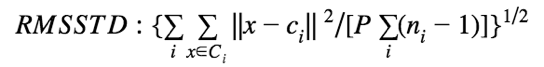
R方 (R-Square),衡量聚类差异度:
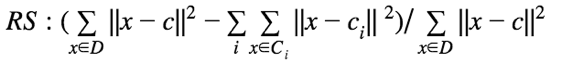
改进的Hubert Γ统计,通过数据对的不一致性来评估聚类的差异:
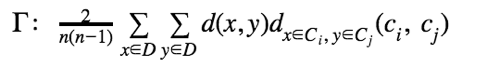
这其中:
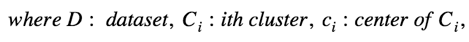
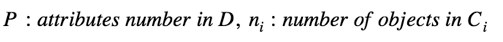
下一题预告
【强化学习】
场景描述
游戏是强化学习最有代表性也是最合适的应用领域之一,其几乎涵盖了强化学习所有的要素,例如环境:游戏本身的状态,动作:用户操作,机器人:程序,回馈:得分、输赢等。通过输入原始像素来玩视频游戏,是人工智能成熟的标志之一。雅达利(Atari)是20世纪七八十年代红极一时的电脑游戏,类似于国内的红白机游戏,但是画面元素要更简单一些。它的模拟器相对成熟简单,使用雅达利游戏来测试强化学习,是非常合适的。应用场景可以描述为:在离散的时间轴上,每个时刻你可以得到当前的游戏画面,选择向游戏机发出一个指令(上下左右,开火等),然后得到一个回馈(reward)。由于基于原始像素的强化学习对应的状态空间巨大,没有办法直接使用传统的方法。于是,2013年DeepMind提出了深度强化学习模型,开始了深度学习和强化学习的结合[2]。
传统的强化学习主要使用Q-learning,而深度强化学习也使用Q-learning为基本框架,把Q-learning的对应步骤改为深度形式,并引入了一些技巧,例如经验重放(experience replay)来加快收敛以及提高泛化能力。
问题描述
什么是深度强化学习,它和传统的强化学习有什么不同,如何用它来玩视频游戏?
参考文献:
[1] Liu Y C, Li Z M, Xiong H, et al. Understanding of internal clustering validation measures. In: Proceedings of IEEE ICDM'10, Sydney, 2010. 911-916.
[2] Antonoglou, I., Graves, A., Kavukcuoglu, K., Mnih, V., Riedmiller, M.A., Silver, D., & Wierstra, D. (2013). Playing Atari with Deep Reinforcement Learning. CoRR, abs/1312.5602.
你可以点击菜单栏的“机器学习”,回顾本系列前几期的全部内容,并留言发表你的感悟与想法。
同时,为使大家更好地了解Hulu,菜单“关于Hulu”也做了相应调整,好奇宝宝们,牌子翻起来吧!
今天的内容是
【非监督学习算法与评估】
场景描述
人具有很强的归纳思考能力,善于从一大堆碎片似的事实或者数据中寻找普遍规律,并得到具有逻辑性的结论。以用户观看视频的行为为例,可以存在多种直观的归纳方式,比如从观看内容的角度看,有喜欢看动画片的,有喜欢看偶像剧的,有喜欢看科幻片的等等;从使用设备的角度看,有喜欢在台式电脑上观看的,有喜欢手机或者平板便携式设备上观看的,还有喜欢在电视等大屏幕上观看的;从使用习惯上看,有喜欢傍晚观看的,有喜欢中午时段观看的,有每天都观看的用户,也有只在周末观看的用户,等等。对所有用户进行有效的分组对于理解用户并推荐给用户合适的内容是重要的。通常这类问题没有观测数据的标签或者分组信息,需要通过算法模型来寻求数据内在的结构和模式 。
问题
以聚类算法为例,假设没有外部标签数据,如何区分两个无监督学习(聚类)算法性的优劣呢?
背景知识:非监督学习,常见聚类算法
解答与分析
场景描述中的例子就是一个典型的聚类问题,从中可以看出,数据的聚类依赖于需求的定义,同时也依赖于分类数据的特征度量以及数据相似性的方法。相比于监督式学习,非监督学习通常没有正确答案,算法模型的设计直接影响最终的输出和性能,需要通过多次迭代的方法寻找模型的最优的参数。因此了解常见数据簇的特点和常见聚类算法的特点,对寻求评估不同聚类算法性能的方法有很大的帮助。
常见数据簇的特点:
以中心定义的数据簇:这类数据集合倾向于球形分布,通常中心被定义为质心,即此数据簇中所有点的平均值。集合中的数据到中心的距离相比到其它簇中心的距离更近;
以密度定义的数据簇:这类数据集合呈现和周围数据簇明显不同的密度,或稠密或稀疏。当数据簇不规则或互相盘绕,并且有噪声和离群点时,常常使用基于密度的簇定义;
以连通定义的数据簇:这类数据集合中的数据点和数据点之间有连接关系,整个数据簇表现为图结构,该定义对不规则形状或者缠绕的的数据簇有效;
以概念定义的数据簇:这类数据集合中的所有数据点具有某种共同性质。
常见的聚类算法的特点:
划分聚类:将数据对象划分成互不重叠的数据簇,其中每个数据点恰在一个数据簇中;
层次聚类:数据簇可以具有子簇,具有多个(嵌套)子簇的数据簇可以表示为树状结构;
模糊聚类:每个数据点均以0~1的隶属权值属于某个数据簇;
完全/不完全聚类:是否对所有数据点都指派一个数据簇。
由于数据以及需求的多样性,没有一种算法能够适应所有的数据类型、簇和应用,似乎每种情况都可能需要一种不同的评估度量。例如,K均值聚类通常需要用SSE (Sum of Square Error) 来评估,但是基于密度的数据簇可以不必是球形,SSE则完全失效。在许多情况下,判断聚类算法结果的好坏最终强烈依赖主观解释。尽管如此,聚类算法的评估还是必须的,它是聚类分析中重要部分之一 。
对聚类算法优劣的评估通常可以总结为对以下五个方面的分析:
辨识数据中是否存在非随机簇结构的能力;
辨识数据中正确数据簇的能力;
评估数据被正确聚类的能力;
辨识两个数据簇之间优劣的能力;
评估与客观数据集之间的差异;
假设存在外部标注数据的支持,那么第5点将转化为监督学习的问题,直接度量聚类算法发现的聚类结构与标注数据的结构匹配程度即可。假设不存在外部标注数据,基于以上所列1~4点,可以如下图1~5所示,测试聚类算法对不同类型数据簇的聚类能力:
图1. 观察误差是否随聚类类别数量的增加而单调变化
图2. 观察误差对聚类结果的影响
图3. 观察近邻数据簇的聚类准确性
图4. 观察聚类算法在处理较大的数据密度差异时的性能
图5. 观察处理不同大小数据种类时的聚类准确度
扩展问题
在以上的回答中介绍了五种评估两个聚类算法性能优劣的,那么具体而言有哪些常见的指标可以用来计算和辨识聚类算法优劣呢?给出几种可能的数据簇形态,定义评估指标可以展现面试者实际解决和分析问题的能力。事实上测量指标可以有很多种,以下列出了三个在数据紧凑性或数据簇可分离程度上的度量,更多指标则请参考文献[1],具体描述如下:
均方根标准偏差 (RMSSTD),衡量聚类同质性:
R方 (R-Square),衡量聚类差异度:
改进的Hubert Γ统计,通过数据对的不一致性来评估聚类的差异:
这其中:
下一题预告
【强化学习】
场景描述
游戏是强化学习最有代表性也是最合适的应用领域之一,其几乎涵盖了强化学习所有的要素,例如环境:游戏本身的状态,动作:用户操作,机器人:程序,回馈:得分、输赢等。通过输入原始像素来玩视频游戏,是人工智能成熟的标志之一。雅达利(Atari)是20世纪七八十年代红极一时的电脑游戏,类似于国内的红白机游戏,但是画面元素要更简单一些。它的模拟器相对成熟简单,使用雅达利游戏来测试强化学习,是非常合适的。应用场景可以描述为:在离散的时间轴上,每个时刻你可以得到当前的游戏画面,选择向游戏机发出一个指令(上下左右,开火等),然后得到一个回馈(reward)。由于基于原始像素的强化学习对应的状态空间巨大,没有办法直接使用传统的方法。于是,2013年DeepMind提出了深度强化学习模型,开始了深度学习和强化学习的结合[2]。
传统的强化学习主要使用Q-learning,而深度强化学习也使用Q-learning为基本框架,把Q-learning的对应步骤改为深度形式,并引入了一些技巧,例如经验重放(experience replay)来加快收敛以及提高泛化能力。
问题描述
什么是深度强化学习,它和传统的强化学习有什么不同,如何用它来玩视频游戏?
参考文献:
[1] Liu Y C, Li Z M, Xiong H, et al. Understanding of internal clustering validation measures. In: Proceedings of IEEE ICDM'10, Sydney, 2010. 911-916.
[2] Antonoglou, I., Graves, A., Kavukcuoglu, K., Mnih, V., Riedmiller, M.A., Silver, D., & Wierstra, D. (2013). Playing Atari with Deep Reinforcement Learning. CoRR, abs/1312.5602.

相关文章推荐
- Hulu机器学习问题与解答系列 | 二十一:分类、排序、回归模型的评估
- Hulu机器学习问题与解答系列 | 十六:经典优化算法
- Hulu机器学习问题与解答系列 | 第八弹:强化学习 (一)
- Hulu机器学习问题与解答系列 | 第一弹:模型评估
- Hulu机器学习问题与解答系列 | 第八弹:强化学习 (二)
- Hulu机器学习问题与解答系列 | 第六弹:PCA算法
- Hulu机器学习问题与解答系列 | 十八:SVM – 核函数与松弛变量
- Hulu机器学习问题与解答系列 | 十四:如何对高斯分布进行采样
- Hulu机器学习问题与解答系列 | 十一:Seq2Seq
- Hulu机器学习问题与解答系列 | 十九:主题模型
- Hulu机器学习问题与解答系列 | 第五弹:余弦距离
- 【机器学习】从分类问题区别机器学习类型 与 初步介绍无监督学习算法 PAC
- Hulu机器学习问题与解答系列 | 十二:注意力机制
- Hulu机器学习问题与解答系列 | 第二弹: SVM模型
- Hulu机器学习问题与解答系列 | 二十二:特征工程—结构化数据
- Hulu机器学习问题与解答系列 | 第三弹: 优化简介
- Hulu机器学习问题与解答系列 | 第十弹:LSTM
- Hulu机器学习问题与解答系列 | 二十:PCA 最小平方误差理论
- Hulu机器学习问题与解答系列 | 第九弹:循环神经网络
- HuLu机器学习问题与解答系列(1-8)