Hulu机器学习问题与解答系列 | 第十弹:LSTM
2018-02-27 19:33
260 查看
RNN课题内容较多,将持续四期哦。坚持学下去,让所有面试变小菜一碟~
你可以点击菜单栏的“机器学习”,回顾本系列前几期的全部内容,并留言发表你的感悟与想法。
今天的内容是
【LSTM】
场景描述
俗话说,前事不忘,后事之师,各种带有记忆功能的网络是近来深度学习研究和实践的一个重要领域。由于RNN有着梯度弥散(vanishing gradient)和梯度爆炸(explosion gradient)等问题,难以学习长期的依赖,在遇到重要的信息时,又难以清空之前的记忆,因此在实际任务中的效果往往并不理想。
LSTM是Long Short-Term Memory(长短期记忆网络)的简称。作为RNN的最知名和成功的扩展,LSTM可以对有价值的信息进行长期记忆,并在遇到新的重要信息时,及时遗忘过去的记忆,减小了RNN的学习难度。它在语音识别,语音建模,机器翻译,图像描述生成,命名实体识别等各类问题中,取得了巨大的成功。
问题描述
LSTM是如何实现长短期记忆功能的?它的各模块分别使用了什么激活函数,可以使用别的激活函数么?
背景知识假设:基本的深度学习知识。
该类问题的被试者:对RNN有一定的使用经验,或在自然语言理解、序列建模等领域有一定的经历。
解答与分析
1. LSTM是如何实现长短期记忆功能的?
该问题需要被试者对LSTM的结构有清晰的了解,并理解其原理。在回答的过程中,应当结合其结构图或更新的计算公式进行讨论,LSTM的结构图示例如下:
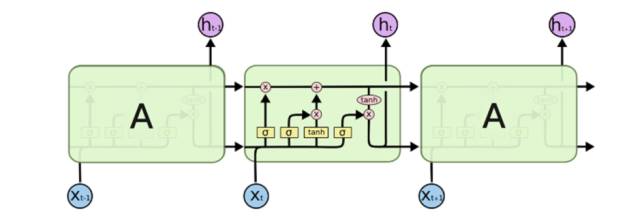
图片来源:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
与传统的RNN比较,LSTM仍然是基于xt和ht-1来计算ht,只不过对内部的结构进行了更加精心的设计,加入了三个阀门(输入门i, 遗忘门f,输出门o)和一个内部记忆单元c。输入门控制当前计算的新状态以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元中的信息有多大程度被遗忘掉;输出门控制当前的输出有多大程度上取决于当前的记忆单元。
经典的LSTM中,第t步的更新计算公式如下:

其中输入门it是通过输入xt和上一步的隐含层输出ht-1进行线性变换,再经过Sigmoid激活函数得到。输入门的结果是向量,其中每个元素是0到1之间的实数,用于控制各维度流过阀门的信息量;Wi,Ui两个矩阵和向量bi为输入门的系数,是在训练过程中需要学习得到的。遗忘门ft和输出门ot的计算方式与输入门类似,它们有各自的系数W,U和b。与传统RNN不同的是,从上一个记忆单元的状态ct-1到当前的状态ct的转移不完全取决于由tanh激活函数计算得到状态,而是由输入门和遗忘门来共同控制。
在一个训练好的网络中,当输入的序列中没有重要信息时,LSTM的遗忘门的值接近于1,输入门的值接近于0,此时过去的记忆会被保存,从而实现了长期记忆功能;当输入的序列中出现了重要的信息时,LSTM应当把其存入记忆中,此时其输入门的值会接近于1;当输入的序列中出现了重要信息,且该信息意味着之前的记忆不再重要时,此时输入门的值接近1, 遗忘门的值接近于0,这样旧的记忆被遗忘,新的重要信息被记忆。经过这样的刻意设计,可以使得整个网络更容易学习到序列之间的长期依赖。
2. LSTM里各模块分别使用什么激活函数,可以使用别的激活函数么?
LSTM中,遗忘门、输入门和输出门使用Sigmoid函数作为激活函数;在生成候选记忆时,使用双曲正切函数tanh作为激活函数 。Sigmoid函数的输出在0~1之间,符合门控的物理定义,且当输入较大/较小时,其输出会非常接近1/0,从而保证该门开/关。在生成候选记忆时使用tanh函数,是因为其输出在-1~1之间,这与大多数场景下特征的分布是0中心的相吻合。此外,tanh函数在输入为0附近相比Sigmoid函数有更大的梯度,通常使模型收敛更快。
LSTM的激活函数也不是一成不变的。例如在原始的LSTM中[1],使用的激活函数是Sigmoid函数的变种,h(x)=2*sigmoid(x)-1,g(x)=4*sigmoid(x)-2,这两个函数的范围分别是[-1,1]和[-2,2]。并且在原始的LSTM中,只有输入门和输出门,没有遗忘门,其中输入x经过输入门后是直接与记忆相加的,所以输入门控g(x)的值是0中心的。后来经过大量的研究和实践,发现增加遗忘门对LSTM的性能有很大的提升[4],并且h(x)使用tanh比2*sigmoid(x)-1要好,所以现代的LSTM采用Sigmoid和tanh作为激活函数。事实上在门控中,使用Sigmoid函数是几乎所有现代神经网络模块的常见选择:例如在GRU[2]和注意力机制中,也广泛使用Sigmoid作为门控的激活函数。因为门控的结果要与被控制的信息流按元素相乘,所以门控的激活函数通常是会饱和的函数。
此外,在一些对计算能力有限制的情景,诸如可穿戴设备中。由于Sigmoid函数中求指数需要一定的计算, 此时会使用hard gate,让门控输出为0或1的离散值:即当输入小于阈值时,门控输出为0,大于阈值时,输出为1。从而在性能下降不显著的情况下,减小计算量。


总而言之,LSTM经历了20年的发展,其核心思想一脉相承,但各个组件都发生了很多演化。了解其发展历程和常见变种,可以让我们在实际工作和研究中,结合问题选择最佳的LSTM模块。灵活思考并知其所以然,而不是死背网络的结构和公式,也有助于在面试中取得更好的表现。
参考文献:
[1] Hochreiter, Sepp, and Jürgen Schmidhuber. "Long short-term memory." Neural computation 9.8 (1997): 1735-1780.
[2] Chung, Junyoung, et al. "Empirical evaluation of gated recurrent neural networks on sequence modeling." arXiv preprint arXiv:1412.3555 (2014).
[3] Gers, Felix A., and Jürgen Schmidhuber. "Recurrent nets that time and count." IJCNN 2000
[4] Gers, Felix A., Jürgen Schmidhuber, and Fred Cummins. "Learning to forget: Continual prediction with LSTM." (1999): 850-855.
下一题预告
【Seq2Seq】
场景描述
作为生物体,我们的视觉和听觉会不断地获得带有序列的声音和图像信号,并交由大脑理解;同时我们在说话、打字、开车等过程中,也在不断地输出序列的声音、文字、操作等信号。在互联网公司日常要处理的数据中,也有很多是以序列形式存在的,例如文本、语音、视频、点击流等。因此如何更好的对序列进行建模,一向是研究的要点。
2013年来,随着深度学习的发展,Seq2Seq(序列到序列)框架在机器翻译领域被大量采用,随后迅速影响到了上述的各领域,应用在了各类序列数据上。
问题描述
Seq2Seq的框架是什么?有哪些优点?
Seq2Seq在解码时,有哪些常用的方法?
你可以点击菜单栏的“机器学习”,回顾本系列前几期的全部内容,并留言发表你的感悟与想法。
今天的内容是
【LSTM】
场景描述
俗话说,前事不忘,后事之师,各种带有记忆功能的网络是近来深度学习研究和实践的一个重要领域。由于RNN有着梯度弥散(vanishing gradient)和梯度爆炸(explosion gradient)等问题,难以学习长期的依赖,在遇到重要的信息时,又难以清空之前的记忆,因此在实际任务中的效果往往并不理想。
LSTM是Long Short-Term Memory(长短期记忆网络)的简称。作为RNN的最知名和成功的扩展,LSTM可以对有价值的信息进行长期记忆,并在遇到新的重要信息时,及时遗忘过去的记忆,减小了RNN的学习难度。它在语音识别,语音建模,机器翻译,图像描述生成,命名实体识别等各类问题中,取得了巨大的成功。
问题描述
LSTM是如何实现长短期记忆功能的?它的各模块分别使用了什么激活函数,可以使用别的激活函数么?
背景知识假设:基本的深度学习知识。
该类问题的被试者:对RNN有一定的使用经验,或在自然语言理解、序列建模等领域有一定的经历。
解答与分析
1. LSTM是如何实现长短期记忆功能的?
该问题需要被试者对LSTM的结构有清晰的了解,并理解其原理。在回答的过程中,应当结合其结构图或更新的计算公式进行讨论,LSTM的结构图示例如下:
图片来源:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
与传统的RNN比较,LSTM仍然是基于xt和ht-1来计算ht,只不过对内部的结构进行了更加精心的设计,加入了三个阀门(输入门i, 遗忘门f,输出门o)和一个内部记忆单元c。输入门控制当前计算的新状态以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元中的信息有多大程度被遗忘掉;输出门控制当前的输出有多大程度上取决于当前的记忆单元。
经典的LSTM中,第t步的更新计算公式如下:
其中输入门it是通过输入xt和上一步的隐含层输出ht-1进行线性变换,再经过Sigmoid激活函数得到。输入门的结果是向量,其中每个元素是0到1之间的实数,用于控制各维度流过阀门的信息量;Wi,Ui两个矩阵和向量bi为输入门的系数,是在训练过程中需要学习得到的。遗忘门ft和输出门ot的计算方式与输入门类似,它们有各自的系数W,U和b。与传统RNN不同的是,从上一个记忆单元的状态ct-1到当前的状态ct的转移不完全取决于由tanh激活函数计算得到状态,而是由输入门和遗忘门来共同控制。
在一个训练好的网络中,当输入的序列中没有重要信息时,LSTM的遗忘门的值接近于1,输入门的值接近于0,此时过去的记忆会被保存,从而实现了长期记忆功能;当输入的序列中出现了重要的信息时,LSTM应当把其存入记忆中,此时其输入门的值会接近于1;当输入的序列中出现了重要信息,且该信息意味着之前的记忆不再重要时,此时输入门的值接近1, 遗忘门的值接近于0,这样旧的记忆被遗忘,新的重要信息被记忆。经过这样的刻意设计,可以使得整个网络更容易学习到序列之间的长期依赖。
2. LSTM里各模块分别使用什么激活函数,可以使用别的激活函数么?
LSTM中,遗忘门、输入门和输出门使用Sigmoid函数作为激活函数;在生成候选记忆时,使用双曲正切函数tanh作为激活函数 。Sigmoid函数的输出在0~1之间,符合门控的物理定义,且当输入较大/较小时,其输出会非常接近1/0,从而保证该门开/关。在生成候选记忆时使用tanh函数,是因为其输出在-1~1之间,这与大多数场景下特征的分布是0中心的相吻合。此外,tanh函数在输入为0附近相比Sigmoid函数有更大的梯度,通常使模型收敛更快。
LSTM的激活函数也不是一成不变的。例如在原始的LSTM中[1],使用的激活函数是Sigmoid函数的变种,h(x)=2*sigmoid(x)-1,g(x)=4*sigmoid(x)-2,这两个函数的范围分别是[-1,1]和[-2,2]。并且在原始的LSTM中,只有输入门和输出门,没有遗忘门,其中输入x经过输入门后是直接与记忆相加的,所以输入门控g(x)的值是0中心的。后来经过大量的研究和实践,发现增加遗忘门对LSTM的性能有很大的提升[4],并且h(x)使用tanh比2*sigmoid(x)-1要好,所以现代的LSTM采用Sigmoid和tanh作为激活函数。事实上在门控中,使用Sigmoid函数是几乎所有现代神经网络模块的常见选择:例如在GRU[2]和注意力机制中,也广泛使用Sigmoid作为门控的激活函数。因为门控的结果要与被控制的信息流按元素相乘,所以门控的激活函数通常是会饱和的函数。
此外,在一些对计算能力有限制的情景,诸如可穿戴设备中。由于Sigmoid函数中求指数需要一定的计算, 此时会使用hard gate,让门控输出为0或1的离散值:即当输入小于阈值时,门控输出为0,大于阈值时,输出为1。从而在性能下降不显著的情况下,减小计算量。
总而言之,LSTM经历了20年的发展,其核心思想一脉相承,但各个组件都发生了很多演化。了解其发展历程和常见变种,可以让我们在实际工作和研究中,结合问题选择最佳的LSTM模块。灵活思考并知其所以然,而不是死背网络的结构和公式,也有助于在面试中取得更好的表现。
参考文献:
[1] Hochreiter, Sepp, and Jürgen Schmidhuber. "Long short-term memory." Neural computation 9.8 (1997): 1735-1780.
[2] Chung, Junyoung, et al. "Empirical evaluation of gated recurrent neural networks on sequence modeling." arXiv preprint arXiv:1412.3555 (2014).
[3] Gers, Felix A., and Jürgen Schmidhuber. "Recurrent nets that time and count." IJCNN 2000
[4] Gers, Felix A., Jürgen Schmidhuber, and Fred Cummins. "Learning to forget: Continual prediction with LSTM." (1999): 850-855.
下一题预告
【Seq2Seq】
场景描述
作为生物体,我们的视觉和听觉会不断地获得带有序列的声音和图像信号,并交由大脑理解;同时我们在说话、打字、开车等过程中,也在不断地输出序列的声音、文字、操作等信号。在互联网公司日常要处理的数据中,也有很多是以序列形式存在的,例如文本、语音、视频、点击流等。因此如何更好的对序列进行建模,一向是研究的要点。
2013年来,随着深度学习的发展,Seq2Seq(序列到序列)框架在机器翻译领域被大量采用,随后迅速影响到了上述的各领域,应用在了各类序列数据上。
问题描述
Seq2Seq的框架是什么?有哪些优点?
Seq2Seq在解码时,有哪些常用的方法?

相关文章推荐
- Hulu机器学习问题与解答系列 | 第八弹:强化学习 (二)
- Hulu机器学习问题与解答系列 | 十六:经典优化算法
- Hulu机器学习问题与解答系列 | 十七:随机梯度下降算法之经典变种
- Hulu机器学习问题与解答系列 | 二十:PCA 最小平方误差理论
- HuLu机器学习问题与解答系列(1-8)
- Hulu机器学习问题与解答系列 | 二十一:分类、排序、回归模型的评估
- Hulu机器学习问题与解答系列 | 二十二:特征工程—结构化数据
- Hulu机器学习问题与解答系列 | 第一弹:模型评估
- Hulu机器学习问题与解答系列 | 第九弹:循环神经网络
- Hulu机器学习问题与解答系列 | 二十三:神经网络训练中的批量归一化
- Hulu机器学习问题与解答系列 | 第二弹: SVM模型
- Hulu机器学习问题与解答系列 | 第三弹: 优化简介
- Hulu机器学习问题与解答系列 | 十一:Seq2Seq
- Hulu机器学习问题与解答系列 | 二十四:随机梯度下降法
- Hulu机器学习问题与解答系列 | 第四弹:不均衡样本集的处理
- Hulu机器学习问题与解答系列 | 十二:注意力机制
- Hulu机器学习问题与解答系列 | 第五弹:余弦距离
- Hulu机器学习问题与解答系列 | 十三:集成学习
- Hulu机器学习问题与解答系列 | 第六弹:PCA算法
- Hulu机器学习问题与解答系列 | 十四:如何对高斯分布进行采样