python爬虫实战--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
2018-01-08 13:46
666 查看
python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
阅读目录
笔记实战操作
正文
在学习scrapy爬虫框架中,肯定会涉及到IP代理池和User-Agent池的设定,规避网站的反爬。这两天在看一个关于搜狗微信文章爬取的视频,里面有讲到ip代理池和用户代理池,在此结合自身的所了解的知识,做一下总结笔记,方便以后借鉴。
回到顶部
笔记
一.反爬虫机制处理思路:浏览器伪装、用户代理池;
IP限制--------IP代理池;
ajax、js异步-------抓包;
验证码-------打码平台。
二.散点知识:
def process_request(): #处理请求
request.meta["proxy"]=.... #添加代理ip
scrapy中如果请求2次就会放弃,说明该代理ip不行。
回到顶部
实战操作
相关代码已经调试成功----2017-4-4目标网址:http://weixin.sogou.com/weixin?type=2&query=python&ie=utf8
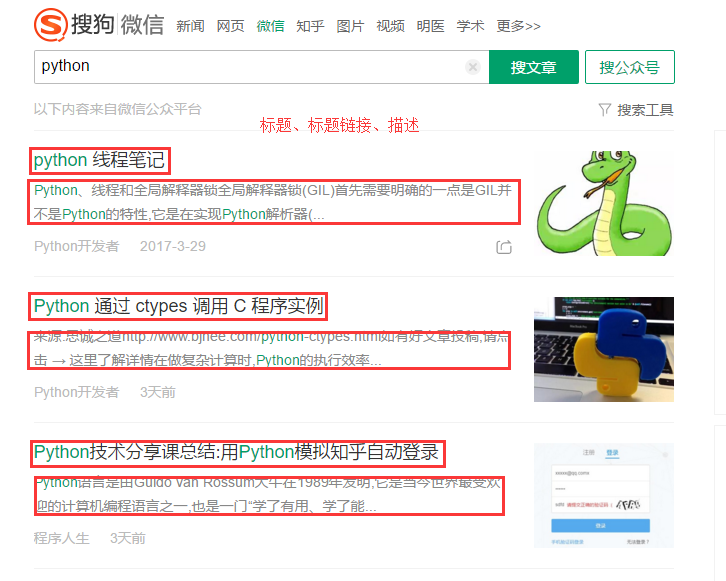
实现:关于python文章的抓取,抓取标题、标题链接、描述。如下图所示。
数据:数据我就没有保存,此实战主要是为了学习IP和用户代理池的设定,推荐一个开源项目关于搜狗微信公众号:基于搜狗微信的公众号文章爬虫
图1
在这里贴出设置IP和用户代理池的代码,完整代码请移步我的github:https://github.com/pujinxiao/weixin
1.middlewares.py主要代码
1 # -*- coding: utf-8 -*-
2 import random
3 from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware #代理ip,这是固定的导入
4 from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware #代理UA,固定导入
5 class IPPOOLS(HttpProxyMiddleware):
6 def __init__(self,ip=''):
7 '''初始化'''
8 self.ip=ip
9 def process_request(self, request, spider):
10 '''使用代理ip,随机选用'''
11 ip=random.choice(self.ip_pools) #随机选择一个ip
12 print '当前使用的IP是'+ip['ip']
13 try:
14 request.meta["proxy"]="http://"+ip['ip']
15 except Exception,e:
16 print e
17 pass
18 ip_pools=[
19 {'ip': '124.65.238.166:80'},
20 # {'ip':''},
21 ]
22 class UAPOOLS(UserAgentMiddleware):
23 def __init__(self,user_agent=''):
24 self.user_agent=user_agent
25 def process_request(self, request, spider):
26 '''使用代理UA,随机选用'''
27 ua=random.choice(self.user_agent_pools)
28 print '当前使用的user-agent是'+ua
29 try:
30 request.headers.setdefault('User-Agent',ua)
31 except Exception,e:
32 print e
33 pass
34 user_agent_pools=[
35 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3',
36 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3',
37 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36',
38 ]2.setting.py主要代码
1 DOWNLOADER_MIDDLEWARES = {
2 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':123,
3 'weixin.middlewares.IPPOOLS':124,
4 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware' : 125,
5 'weixin.middlewares.UAPOOLS':126
6 }作者:今孝
出处:http://www.cnblogs.com/jinxiao-pu/p/6665180.html

相关文章推荐
- python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(2)
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(1)
- Python爬虫实战(三) — 微信文章爬虫
- python爬虫实战笔记---以轮子哥为起点Scrapy爬取知乎用户信息
- Python爬虫框架Scrapy实战之抓取户外数据
- [Python爬虫] 之十五:Selenium +phantomjs根据微信公众号抓取微信文章
- python爬虫——爬取微信文章
- python3 [爬虫入门实战]爬虫之scrapy爬取织梦者网站并存mongoDB
- python3 [爬虫入门实战]爬取熊猫直播用户信息
- python爬虫框架之scrapy安装与当当网爬虫实战
- Python爬虫实战之使用Scrapy爬起点网的完本小说
- python爬虫实战(七)--------伯乐在线文章(模版)
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第3章 爬虫基础知识回顾
- Python爬虫框架Scrapy 学习笔记 10.2 -------【实战】 抓取天猫某网店所有宝贝详情
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- Python scrapy爬虫爬取伯乐在线全部文章,并写入数据库
- nodejs爬虫抓取搜狗微信文章详解
- 【Python】Python34环境下安装爬虫框架scrapy实战篇!
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)