python爬虫框架之scrapy安装与当当网爬虫实战
2018-03-23 16:12
891 查看
一、scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下:
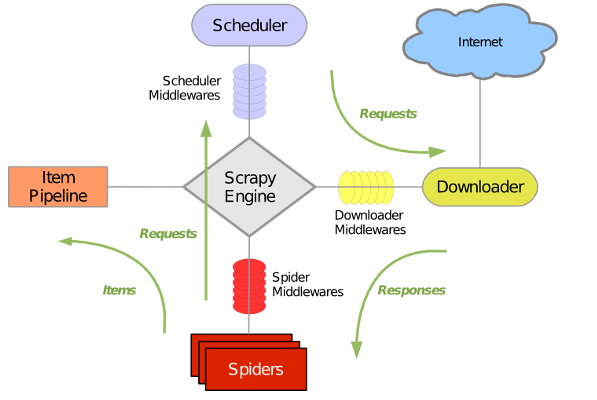
Scrapy主要包括了以下组件:
引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
1. 引擎从调度器中取出一个链接(URL)用于接下来的抓取。
2. 引擎把URL封装成一个请求(Request)传给下载器。
3. 下载器把资源下载下来,并封装成应答包(Response)。
4. 爬虫解析Response。
5. 解析出实体(Item),则交给实体管道进行进一步的处理。
6. 解析出的是链接(URL),则把URL交给调度器等待抓取。
二、安装scrapy
本文在windows平台上进行安装,在cmd中利用pip命令安装,命令为:pip install scrapy但是提示安装失败,如下图所示
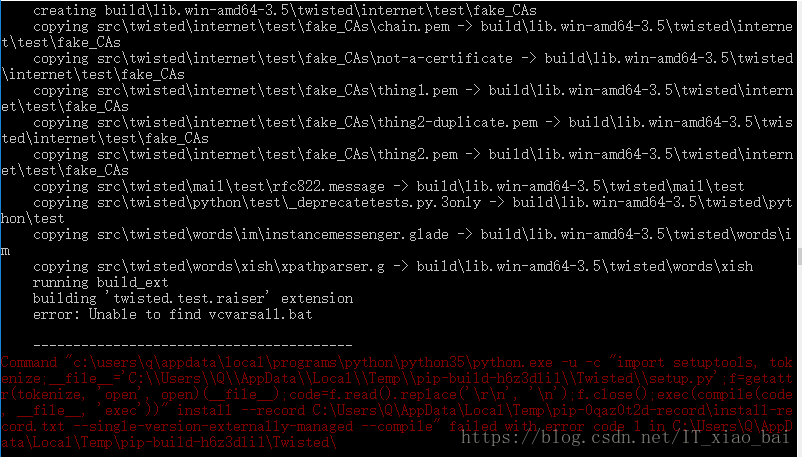
根据错误提示发现是Twisted安装失败导致的问题,这个库它是用Python实现的基于事件驱动的网络引擎框架。
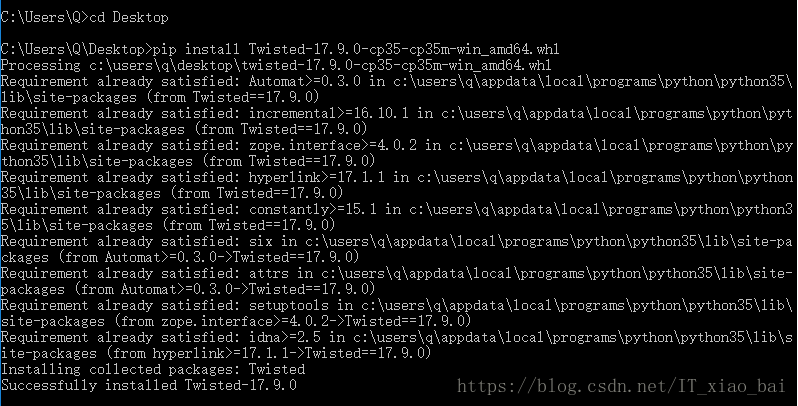
尝试用pip install Twisted进行安装,还是出现了相同的错误。最后通过参考这篇博文安装成功了Twisted,参考的博文地址为https://blog.csdn.net/code_ac/article/details/71159244,安装成功结果如下图所示
之后又重新运行了一次pip install scrapy这个命令,没有错误提示,再用pip list命令查看了以下是否安装上了scrapy,显示已安装,还可以通过输入命令scrapy version查看一下scrapy的版本,如下图所示,这样scrapy就安装好了。

三、当当网爬虫实战
安装好了scrapy,通过实战进一步学习该框架。首先新建一个存储爬虫项目的文件夹,然后在该文件夹中输入命令scrapy startproject dangdang创建一个爬虫项目,如下图

创建好的爬虫项目的目录结构如下图所示

在dangdang项目文件夹下有dangdang文件夹和scrapy.cfg文件,其中scrapy.cfg文件中主要包含的是项目的相关设置。
Spiders文件夹:我们可以在Spiders文件夹下编写我们的爬虫文件,里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或一些网站。
__init__.py:项目的初始化文件。
items.py:通过文件的注释我们了解到这个文件的作用是定义我们所要爬取的信息的相关属性。Item对象是种容器,用来保存获取到的数据。
middlewares.py:Spider中间件,在这个文件里我们可以定义相关的方法,用以处理蜘蛛的响应输入和请求输出。pipelines.py:在item被Spider收集之后,就会将数据放入到item pipelines中,在这个组件是一个独立的类,他们接收到item并通过它执行一些行为,同时也会决定item是否能留在pipeline,或者被丢弃。
settings.py:提供了scrapy组件的方法,通过在此文件中的设置可以控制包括核心、插件、pipeline以及Spider组件。
在spiders文件夹里创建爬虫文件,或者可以在命令行中输入命令scrapy genspider -t basic dangdangspider dangdang.com进行创建,命令的格式为:scrapy genspider [-t 模板名称] 文件名 域名
下面我们开始对http://category.dangdang.com/pg1-cp01.03.38.00.00.00.html这个网址的前100个网页进行爬虫实战
首先,编写item,代码如下:
import scrapy class DangdangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() #pass titile = scrapy.Field() #标题 link = scrapy.Field() #链接 price = scrapy.Field() #价格 comment = scrapy.Field() #评论数 primecost = scrapy.Field() #原价 pid = scrapy.Field() #商品id rebate = scrapy.Field() #折扣 press = scrapy.Field() #出版社 shop = scrapy.Field() #店铺名 e_book = scrapy.Field() #电子书 e_price = scrapy.Field() #电子书价格
然后编写爬虫程序,在dangdangspider爬虫程序中输入如下代码:
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request
class DangdangspiderSpider(scrapy.Spider):
name = 'dangdangspider'
allowed_domains = ['dangdang.com']
start_urls = ['http://category.dangdang.com/pg1-cp01.03.38.00.00.00.html']
def parse(self, response):
#通过检查网页元素,发现要爬取的信息都在li标签下
list = response.xpath('/html/body/div[2]/div[3]/div[3]/div[9]/div[2]/ul/li')
for li in list:
item = DangdangItem
item['title'] = li.xpath('div/p[1]/a/@title').extract()[0] #此处xpath表达式不要加‘/’
link = li.xpath('div/p[1]/a/@href').extract()[0]
item['link'] = link.split('#')[0] #用‘#’分割网址,去掉网址多余的后半部分
item['pid'] = li.xpath('@id').extract()[0]
item['comment'] = li.xpath('div/p[2]/a/text()').extract()[0]
item['price'] = li.xpath('div/p[6]/span[1]/text()').extract()[0].lstrip('\xa5') #需要去除‘¥’符号
press = li.xpath('div/div/p[3]/a/text()').extract() #出版社
if len(press) > 0:
item['press'] = press[0]
else:
item['press'] = '未知'
shopname = li.xpath('div/p[4]/a/text()').extract()
if len(shopname) > 0:
item['shop'] = shopname[0]
else:
item['shop'] = '当当自营'
item['primecost'] = li.xpath('div/p[6]/span[2]/text()').extract()[0].lstrip('\xa5') #原价
item['rebate'] = li.xpath('div/p[6]/span[3]/text()').extract()[0] #折扣
e_book = li.xpath('div/div[2]/a/text()').extract()
if len(e_book) > 0:
item['e_book'] = e_book[0]
item['e_price'] = li.xpath('div/div[2]/p[2]/span/text()').extract()[0].lstrip('\xa5')
else:
item['e_book'] = '无'
item['e_price'] = '-'
yield item
for i in range(2, 101): #爬取100页的数据
url = 'http://category.dangdang.com/pg' + str(i) + '-cp01.03.38.00.00.00.html'
yield Request(url, callback = self.parse)接下来编写pipelines,出于调试爬虫程序的需要,这里的pipelines就先定义为打印输出在屏幕上
class DangdangPipeline(object):
def process_item(self, item, spider):
print(item['title'])
print(item['link'])
print(item['comment'])
print(item['pid'])
print(item['rebate'])
print(item['price'])
print(item['primecost'])
print(item['press'])
print(item['shop'])
print(item['e_book'])
print(item['e_price'])
print('==============================')
return item然后修改settings.py文件,在22行设置为不遵守robots.txt,修改ROBOTSTXT_OBEY = False
在67行解除pipelines的注释,并修改为对应的pipelines
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}最后,在cmd中输入命令 scrapy crawl dangdangspider -o dangdangbooks.csv进行爬虫,将数据直接输出为csv文件
运行后出现ImportError: No module named ‘win32api’的错误,通过pip install pypiwin32命令安装该库。
再次运行爬虫程序,成功爬到数据。


相关文章推荐
- 【Python】Python34环境下安装爬虫框架scrapy实战篇!
- Python爬虫框架Scrapy实战之安装
- redhat系统安装scrapy爬虫框架步骤Python版
- python2.7.9安装爬虫框架Scrapy的问题
- Python3环境安装Scrapy爬虫框架
- Python爬虫框架Scrapy安装使用步骤
- 零基础写python爬虫之爬虫框架Scrapy安装配置
- python3 [爬虫入门实战]爬虫之scrapy安装与配置教程
- Python爬虫框架Scrapy安装使用步骤
- Python爬虫进阶一之爬虫框架Scrapy安装配置
- ubuntu14.04安装python爬虫框架Scrapy
- python爬虫框架scrapy安装
- Python网络爬虫3 ---- ubuntu下安装爬虫框架scrapy
- Python3环境安装Scrapy爬虫框架过程及常见错误
- Python3 爬虫之 Scrapy 框架安装配置(一)
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第4章 scrapy爬取知名技术文章网站(1)
- python爬虫框架scrapy实战之爬取京东商城进阶篇
- Python爬虫进阶三之Scrapy框架安装配置
- Python之Scrapy爬虫框架安装及简单使用
- Python之Scrapy爬虫框架安装及使用详解