Python爬虫框架Scrapy实战之抓取户外数据
2015-03-26 15:19
791 查看
一个户外论坛的特点:
列出一些活动,有翻页功能,点向一个活动显示当前活动信息,在二楼一般显示报名名单!需要的数据:
就是活动的信息,报名的名单,价钱,主题,url数据库:
旅游表与报名表选择Spider:
我选择了CrawlSpider,这个特点:提供一个跟随链接的一个规则!rules = (
Rule(LinkExtractor(allow=('forum\.php\?mod=forumdisplay\&fid=2\&page=\d+', ))),
Rule(LinkExtractor(restrict_xpaths='//tr/th[@class="common"]/a[starts-with(@href,"http")]'), callback='parse_item'),
)提取数据的xpath:
'//div[@id="postlist"]/div[2]//div[@align="left"]/text()','//div[@id="postlist"]/div[2]//strong/text()']
实例地址:
https://github.com/heavyzero/example/tree/master/uutravel结果:
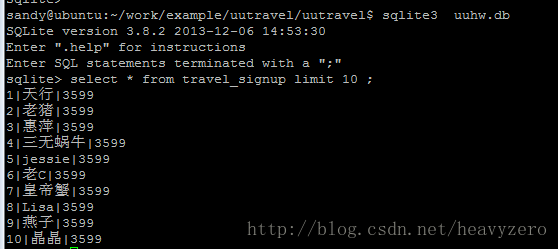

相关文章推荐
- Python爬虫框架Scrapy 学习笔记 10.2 -------【实战】 抓取天猫某网店所有宝贝详情
- Python爬虫框架Scrapy 学习笔记 10.2 -------【实战】 抓取天猫某网店所有宝贝详情
- Python爬虫框架Scrapy实战之批量抓取招聘信息
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- Python爬虫框架Scrapy实战之批量抓取招聘信息
- Python爬虫框架Scrapy 学习笔记 10.3 -------【实战】 抓取天猫某网店所有宝贝详情
- Python爬虫框架Scrapy实战 - 抓取BOSS直聘招聘信息
- Python爬虫框架Scrapy 学习笔记 10.1 -------【实战】 抓取天猫某网店所有宝贝详情
- Python爬虫简单实战:抓取小猪短租西安市前五页民房数据
- 利用python scrapy 框架抓取豆瓣小组数据
- 实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
- python3 [爬虫入门实战]scrapy爬取盘多多五百万数据并存mongoDB
- Python爬虫框架Scrapy之爬取糗事百科大量段子数据
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第1章 课程介绍
- python爬虫框架scrapy实战之爬取京东商城进阶篇
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第2章 windows下搭建开发环境
- python 爬虫 实战(一) —— 抓取学校开课数据
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- 使用python scrapy爬虫框架 爬取科学网自然科学基金数据