信息熵、交叉熵与相对熵
2018-01-04 09:19
246 查看
本文参考了:
https://baike.baidu.com/item/%E4%BF%A1%E6%81%AF%E7%86%B5/7302318?fr=aladdin http://blog.csdn.net/zb1165048017/article/details/48937135
这三个概念广泛用于如nlp等深度学习任务中。TF-IDF等概念,是基于这些基本概念衍生出来的。而这三者有着密不可分的联系。下面就来说明一下它们之间的关系。
信息熵
用来衡量信息量大小,也就是不确定程度。直观理解就是用一组序号给若干不确定的结果编码,平均编码长度。
公式:

为什么公式长这样呢?因为一个信源发送出什么符号是不确定的,衡量它可以根据其出现的概率来度量。概率大,出现机会多,不确定性小;反之就大。
不确定性函数f是概率P的单调递降函数;两个独立符号所产生的不确定性应等于各自不确定性之和,即f(P1,P2)=f(P1)+f(P2),这称为可加性。同时满足这两个条件的函数f是对数函数,即

.
而平均不确定性就是不确定性的期望。
交叉熵
现有关于样本集的2个概率分布p和q,其中p为真实分布,q非真实分布。按照真实分布p来衡量识别一个样本的所需要的编码长度的期望(即平均编码长度)为:
也就是信息熵。
如果使用错误分布q来表示来自真实分布p的平均编码长度,则应该是:
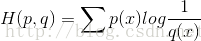
因为用q来编码的样本来自分布p,所以期望H(p,q)中概率是p(i)。H(p,q)我们称之为“交叉熵”。
比如含有4个字母(A,B,C,D)的数据集中,真实分布p=(1/2, 1/2, 0, 0),即A和B出现的概率均为1/2,C和D出现的概率都为0。计算H(p)为1,即只需要1位编码即可识别A和B。如果使用分布Q=(1/4, 1/4, 1/4, 1/4)来编码则得到H(p,q)=2,即需要2位编码来识别A和B(当然还有C和D,尽管C和D并不会出现,因为真实分布p中C和D出现的概率为0,这里就钦定概率为0的事件不会发生啦)。
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
相对熵
可以看到上例中根据非真实分布q得到的平均编码长度H(p,q)大于根据真实分布p得到的平均编码长度H(p)。事实上,根据Gibbs'
inequality可知,H(p,q)>=H(p)恒成立,当q为真实分布p时取等号。我们将由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为“相对熵”:

其又被称为KL散度(Kullback–Leibler divergence,KLD)Kullback–Leibler
divergence。它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0。注意,KL散度的非对称性。
比如TD-IDF算法就可以理解为相对熵的应用:词频在整个语料库的分布与词频在具体文档中分布之间的差异性。
https://baike.baidu.com/item/%E4%BF%A1%E6%81%AF%E7%86%B5/7302318?fr=aladdin http://blog.csdn.net/zb1165048017/article/details/48937135
这三个概念广泛用于如nlp等深度学习任务中。TF-IDF等概念,是基于这些基本概念衍生出来的。而这三者有着密不可分的联系。下面就来说明一下它们之间的关系。
信息熵
用来衡量信息量大小,也就是不确定程度。直观理解就是用一组序号给若干不确定的结果编码,平均编码长度。
公式:
为什么公式长这样呢?因为一个信源发送出什么符号是不确定的,衡量它可以根据其出现的概率来度量。概率大,出现机会多,不确定性小;反之就大。
不确定性函数f是概率P的单调递降函数;两个独立符号所产生的不确定性应等于各自不确定性之和,即f(P1,P2)=f(P1)+f(P2),这称为可加性。同时满足这两个条件的函数f是对数函数,即
.
而平均不确定性就是不确定性的期望。
交叉熵
现有关于样本集的2个概率分布p和q,其中p为真实分布,q非真实分布。按照真实分布p来衡量识别一个样本的所需要的编码长度的期望(即平均编码长度)为:
也就是信息熵。
如果使用错误分布q来表示来自真实分布p的平均编码长度,则应该是:
因为用q来编码的样本来自分布p,所以期望H(p,q)中概率是p(i)。H(p,q)我们称之为“交叉熵”。
比如含有4个字母(A,B,C,D)的数据集中,真实分布p=(1/2, 1/2, 0, 0),即A和B出现的概率均为1/2,C和D出现的概率都为0。计算H(p)为1,即只需要1位编码即可识别A和B。如果使用分布Q=(1/4, 1/4, 1/4, 1/4)来编码则得到H(p,q)=2,即需要2位编码来识别A和B(当然还有C和D,尽管C和D并不会出现,因为真实分布p中C和D出现的概率为0,这里就钦定概率为0的事件不会发生啦)。
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
相对熵
可以看到上例中根据非真实分布q得到的平均编码长度H(p,q)大于根据真实分布p得到的平均编码长度H(p)。事实上,根据Gibbs'
inequality可知,H(p,q)>=H(p)恒成立,当q为真实分布p时取等号。我们将由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为“相对熵”:
其又被称为KL散度(Kullback–Leibler divergence,KLD)Kullback–Leibler
divergence。它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0。注意,KL散度的非对称性。
比如TD-IDF算法就可以理解为相对熵的应用:词频在整个语料库的分布与词频在具体文档中分布之间的差异性。

相关文章推荐
- 熵、联合熵、条件熵、交叉熵与相对熵意义
- 信息量, 信息熵, 交叉熵, KL散度
- 通俗的解释交叉熵与相对熵
- 理解熵(信息熵,交叉熵,相对熵)
- 熵、联合熵、条件熵、交叉熵与相对熵意义
- 交叉熵与相对熵
- 熵、信息熵、交叉熵、相对熵、条件熵、互信息、条件熵的贝叶斯规则
- 交叉编译Qt4.8.2
- Ubuntu 14.04 64位 嵌入式交叉编译环境arm-linux-gcc搭建 一次成功
- 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
- 相对于任意平面的镜像变换矩阵
- RelativeLayout相对布局
- 机器学习-CrossValidation交叉验证
- 交叉编译mentohust实现锐捷认证共享上网
- HTML相对路径和绝对路径
- EBS调用交叉验证规则校验外围系统导入凭证
- 绝对路径和相对路径的问题
- 不要与上级争锋相对地顶撞
- 编写函数void change(char *a,char *b,char*c)。 函数功能是首先把b指向的字符串逆向存放 然后将a指向的字符串和b指向的字符串按排列顺序交叉合并到c指向的数
- 建立交叉编译的Qt/Embeded开发环境