支持向量机(斯坦福大学课程讲义Andrew Ng)
2016-10-28 19:19
183 查看
SVM算法是最流行的监督学习算法之一(很多人认为是最好的)。为了讲清楚SVM算法,我们需要先讨论一下间隔(margin)和分离数据的间隙(gap)。 下一步,我们将会讨论最优间隔分类器,其中用到了拉格朗日对偶。 我们也会接触到核函数,核函数提供了一种将SVM应用于高维(比如无限维)特征空间的方法。 最后我们讲解SMO(序列最小优化)算法,它是SVM算法的高效实现。
1.间隔:直观
这部分给出了间隔和预测的“可信度”的直观介绍。 对于逻辑回归来说,概率P(y=1│x;θ)被模式化为h_θ (x)=g(θ^T x).当且仅当h_θ (x)≥0.5或者是θ^T x≥0,我们将预测结果为1.考虑一个正的的训练样本(y=1). θ^T x越大,h_θ (x)=P(y=1|x;w,b)就会越大,我们就会认为标签为1 的可能性越高。这样我们就会认为当θ^T x≫0时,y=1的可信度很高。相似的,我们就会认为逻辑回归做出如下预测,当θ^T x≪0时,y=0。对于一个训练集来说,如果我们能找到参数θ使得当y^((i))=1时,θ^T x^((i))≫0, 当y^((i))=0时,θ^T x^((i))≪0,才能得到对训练数据的良好的拟合,因为它反映了对于所有训练样本的正确的分类。我们将利用函数间隔来形式化这种分类从而实现良好的拟合结果。
对于直观上的不同类型,如下图,×代表正例的训练样本,0代表负例的训练样本,决策间隔(这条直线根据等式θ^T x=0,也叫分离超平面)为下图直线,还有三个点分别标注为A,B,C。
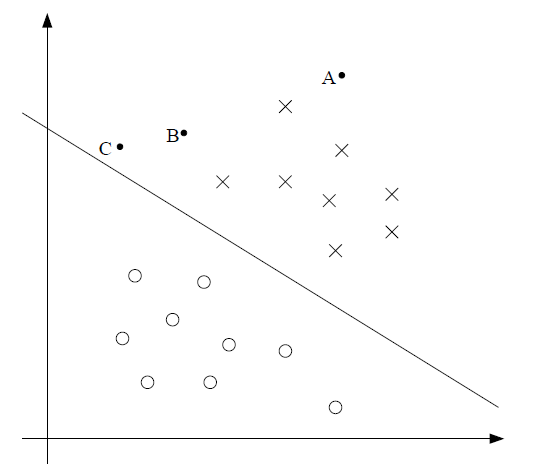
注意到点A远离决策面。如果对点A做出预测,那么我们一定十分确信y=1。相反的,点C离决策面很近,虽然它在决策面做出预测y=1的那一边,但是如果决策面稍微移动,就有可能结果为y=0。因此,相对于C的预测结果,我们更加确信A的预测结果。点B在A,C两个实例之间,从而我们认为当一个点离分离超平面越远时,我们则更加确信我们的预测结果。通常,我们设法找到一个好的决策间隔,使得在训练样本上做出的数据全部为正确的和可信的(意味着远离决策间隔)。稍后我们将要使用几何间隔来形式化的表示上述说法。
由于文章涉及的公式过多,而编辑器不能很好的显示这些公式,所以我已经整理成文档供大家免费下载,请多多指教。
1.间隔:直观 1
2.数学符号 3
3.函数间隔和几何间隔(Functional and geometric margins) 3
4.最优间隔分类器(The optimal margin classifier) 6
5.拉格朗日对偶性 8
6.最优间隔分类器 11
7.核函数 15
8.正则化和不可分离的情况 20
9. SMO算法 22
9.1 坐标上升 22
9.2 SMO 24
1.间隔:直观
这部分给出了间隔和预测的“可信度”的直观介绍。 对于逻辑回归来说,概率P(y=1│x;θ)被模式化为h_θ (x)=g(θ^T x).当且仅当h_θ (x)≥0.5或者是θ^T x≥0,我们将预测结果为1.考虑一个正的的训练样本(y=1). θ^T x越大,h_θ (x)=P(y=1|x;w,b)就会越大,我们就会认为标签为1 的可能性越高。这样我们就会认为当θ^T x≫0时,y=1的可信度很高。相似的,我们就会认为逻辑回归做出如下预测,当θ^T x≪0时,y=0。对于一个训练集来说,如果我们能找到参数θ使得当y^((i))=1时,θ^T x^((i))≫0, 当y^((i))=0时,θ^T x^((i))≪0,才能得到对训练数据的良好的拟合,因为它反映了对于所有训练样本的正确的分类。我们将利用函数间隔来形式化这种分类从而实现良好的拟合结果。
对于直观上的不同类型,如下图,×代表正例的训练样本,0代表负例的训练样本,决策间隔(这条直线根据等式θ^T x=0,也叫分离超平面)为下图直线,还有三个点分别标注为A,B,C。
注意到点A远离决策面。如果对点A做出预测,那么我们一定十分确信y=1。相反的,点C离决策面很近,虽然它在决策面做出预测y=1的那一边,但是如果决策面稍微移动,就有可能结果为y=0。因此,相对于C的预测结果,我们更加确信A的预测结果。点B在A,C两个实例之间,从而我们认为当一个点离分离超平面越远时,我们则更加确信我们的预测结果。通常,我们设法找到一个好的决策间隔,使得在训练样本上做出的数据全部为正确的和可信的(意味着远离决策间隔)。稍后我们将要使用几何间隔来形式化的表示上述说法。
由于文章涉及的公式过多,而编辑器不能很好的显示这些公式,所以我已经整理成文档供大家免费下载,请多多指教。
http://download.csdn.net/detail/aq_cainiao_aq/9797000
目录:1.间隔:直观 1
2.数学符号 3
3.函数间隔和几何间隔(Functional and geometric margins) 3
4.最优间隔分类器(The optimal margin classifier) 6
5.拉格朗日对偶性 8
6.最优间隔分类器 11
7.核函数 15
8.正则化和不可分离的情况 20
9. SMO算法 22
9.1 坐标上升 22
9.2 SMO 24

相关文章推荐
- 斯坦福大学(Andrew Ng)机器学习课程讲义
- 斯坦福大学(Andrew Ng)机器学习课程讲义
- 斯坦福大学Andrew Ng - 机器学习笔记(5) -- 支持向量机(SVM)
- 斯坦福大学cs229Andrew ng的机器学习课程
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——8、监督学习:Learning Theory
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——5、监督学习:Support Vector Machine,引
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——9、无监督学习:K-means Clustering Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——10、无监督学习:Mixture of Gaussians and the EM Algorithm
- 斯坦福大学公开课机器学习课程(Andrew Ng)三欠拟合与过拟合
- 斯坦福大学公开课机器学习课程(Andrew Ng)五生成学习算法
- 斯坦福大学机器学习课程讲义
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——1、整体看一看
- 斯坦福大学公开课机器学习课程(Andrew Ng)四牛顿方法与广义线性模型
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——2、监督学习:Regression and Classification
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——11、无监督学习:the derivation of EM Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——12、无监督学习:Factor Analysis
- 斯坦福大学公开课机器学习课程(Andrew Ng)二监督学习应用 梯度下降
- 斯坦福大学公开课机器学习课程(Andrew Ng)八顺序最小优化算法
- 斯坦福大学机器学习课程原始讲义 + 公开课视频
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——3、监督学习:Gaussian Discriminant Analysis (GDA)