斯坦福大学公开课 :机器学习课程(Andrew Ng)——3、监督学习:Gaussian Discriminant Analysis (GDA)
2015-01-02 19:23
295 查看
[b]0)[b][b][b]高斯判别分析模型[/b][/b]适用于输入特征x是连续型随机变量的情况,主要目的是确定后验概率p(x|y)。
[/b][/b]
[b]1)判别模型和生成模型(Discriminative/Generative Model)
[/b]
[b]2)高斯判别分析(Gaussian Discriminant Analysis(GDA))[/b]
[b] 2.1) 多元正态分布
[/b]
[b] 2.2) 高斯判别模型分析[/b]
[b] 2.3) 利用高斯判别模型进行分类[/b]
[b] 2.4)高斯判别分析(GDA)与logistic回归的关系[/b]
[b][b]0)[b][b][b]高斯判别分析模型[/b][/b]适用于输入特征x是连续型随机变量的情况,主要目的是确定后验概率p(x|y)。[/b][/b]
[/b]
1)判别模型和生成模型(Discriminative/Generative Model)
Discriminative Algorithms:mapping directly from X to the labels {0, 1}。
Generative Algorithms: try to model p(x|y=0), p(x|y=1),p(x) = p(x|y=1)*p(y=1)+p(x|y=0)*p(y=0),p(y=1),p(y=0)
然后利用贝叶斯公式将统一性:
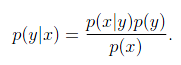
由于我们关注的是y的离散值结果中哪个概率大,而并不是关心具体的概率,因此上式改写为:
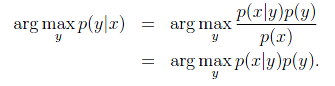
其中
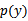
称为先验概率,人为指定或根据每个y=0/1在样本中所占的比例近似;
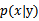
称为后验概率,是我们想要真正计算的。
2)高斯判别分析(Gaussian Discriminant Analysis(GDA))
高斯判别分析:assume that p(x|y) is distributed according to a multivariate normal distribution(多元正态分布)。
2.1) 多元正态分布
多变量正态分布描述的是n维随机变量的分布情况,这里的

变成了向量,
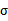
也变成了矩阵
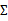
。写作

。假设有n个随机变量X1,X2,…,Xn。

的第i个分量是E(Xi),而
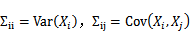
。
概率密度函数如下:
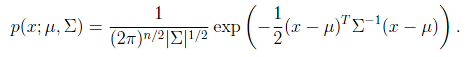
其中|

是
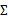
的行列式,
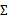
是协方差矩阵,而且是对称半正定的。
当

是二维的时候可以如下图表示:
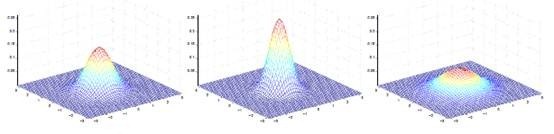
其中

决定中心位置,

决定投影椭圆的朝向和大小。
如下图:
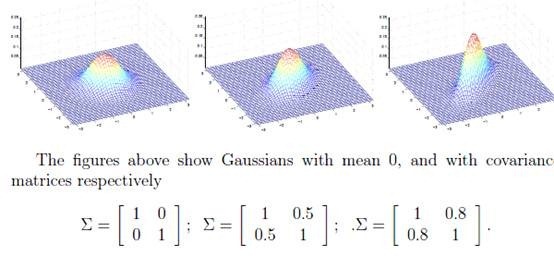
对应的
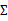
都不同。
2.2) 高斯判别模型分析
如果输入特征x是连续型随机变量,那么可以使用高斯判别分析模型来确定p(x|y)。
模型如下:
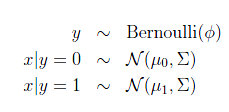
输出结果服从伯努利分布,在给定模型下特征符合多元高斯分布。通俗地讲,在山羊模型下,它的胡须长度,角大小,毛长度等连续型变量符合高斯分布,他们组成的特征向量符合多元高斯分布。
这样,可以给出概率密度函数:
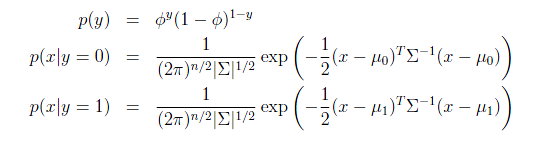
最大似然估计如下:
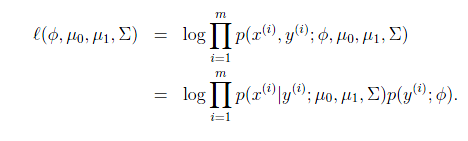
注意这里的参数有两个

,表示在不同的结果模型下,特征均值不同,但我们假设协方差相同。反映在图上就是不同模型中心位置不同,但形状相同。这样就可以用直线来进行分隔判别。
求导后,得到参数估计公式:
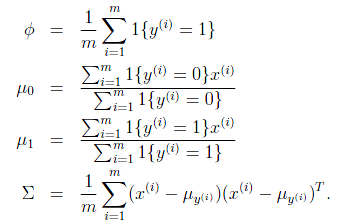
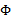
是训练样本中结果y=1占有的比例。
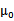
是y=0的样本中特征均值。
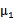
是y=1的样本中特征均值。
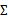
是样本特征方差均值。
如前面所述,在图上表示为:

直线两边的y值不同,但协方差矩阵相同,因此形状相同。

不同,因此位置不同。
2.3) 利用高斯判别模型进行分类
a)根据训练样例,利用2.2)中描述的方法计算出了高斯判别模型中的4个参数。
b)对于一个新的待分类数据x,根据下面的式子计算p(x|y=0)*p(y=0)和p(x|y=1)*p(y=1)哪个大,对应的y就是x要归为的类。
2.4)高斯判别分析(GDA)与logistic回归的关系
将GDA用条件概率方式来表述的话,如下:
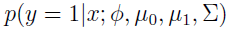
y是x的函数,其中
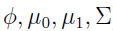
都是参数。
进一步推导出
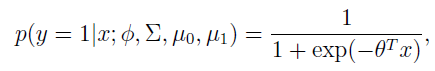
这里的
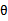
是
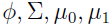
的函数。这个形式就是logistic回归的形式。
也就是说,如果p(x|y)符合多元高斯分布,那么p(y|x)符合logistic回归模型。反之,不成立。为什么反过来不成立呢?因为GDA有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么GDA在训练集上是最好的模型。然而,我们往往事先不知道训练数据满足什么样的分布,更不应该做很强的假设,此时采用logistic回归的方法就比较合适。 例如,如果训练数据满足泊松分布(而不是多元高斯分布),即
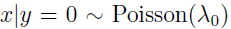
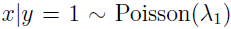
,此时p(y|x)仍然是logistic回归的,但不是多元高斯分布,采用GDA效果也会比较差。这也是logistic回归用的更多的原因。
参考:http://www.cnblogs.com/jerrylead/archive/2011/03/05/1971903.html
[/b][/b]
[b]1)判别模型和生成模型(Discriminative/Generative Model)
[/b]
[b]2)高斯判别分析(Gaussian Discriminant Analysis(GDA))[/b]
[b] 2.1) 多元正态分布
[/b]
[b] 2.2) 高斯判别模型分析[/b]
[b] 2.3) 利用高斯判别模型进行分类[/b]
[b] 2.4)高斯判别分析(GDA)与logistic回归的关系[/b]
[b][b]0)[b][b][b]高斯判别分析模型[/b][/b]适用于输入特征x是连续型随机变量的情况,主要目的是确定后验概率p(x|y)。[/b][/b]
[/b]
1)判别模型和生成模型(Discriminative/Generative Model)
Discriminative Algorithms:mapping directly from X to the labels {0, 1}。
Generative Algorithms: try to model p(x|y=0), p(x|y=1),p(x) = p(x|y=1)*p(y=1)+p(x|y=0)*p(y=0),p(y=1),p(y=0)
然后利用贝叶斯公式将统一性:
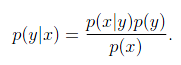
由于我们关注的是y的离散值结果中哪个概率大,而并不是关心具体的概率,因此上式改写为:
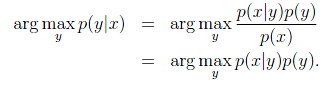
其中
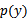
称为先验概率,人为指定或根据每个y=0/1在样本中所占的比例近似;
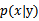
称为后验概率,是我们想要真正计算的。
2)高斯判别分析(Gaussian Discriminant Analysis(GDA))
高斯判别分析:assume that p(x|y) is distributed according to a multivariate normal distribution(多元正态分布)。
2.1) 多元正态分布
多变量正态分布描述的是n维随机变量的分布情况,这里的

变成了向量,
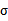
也变成了矩阵
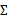
。写作

。假设有n个随机变量X1,X2,…,Xn。

的第i个分量是E(Xi),而
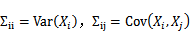
。
概率密度函数如下:
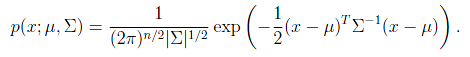
其中|
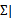
是

的行列式,
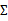
是协方差矩阵,而且是对称半正定的。
当

是二维的时候可以如下图表示:
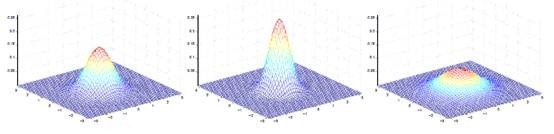
其中

决定中心位置,
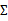
决定投影椭圆的朝向和大小。
如下图:
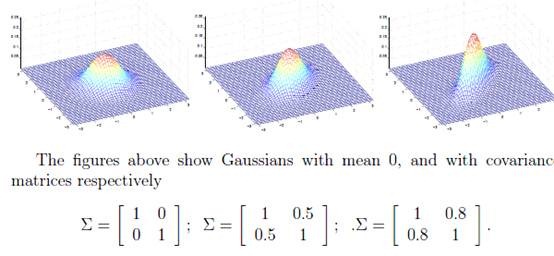
对应的
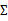
都不同。
2.2) 高斯判别模型分析
如果输入特征x是连续型随机变量,那么可以使用高斯判别分析模型来确定p(x|y)。
模型如下:
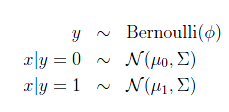
输出结果服从伯努利分布,在给定模型下特征符合多元高斯分布。通俗地讲,在山羊模型下,它的胡须长度,角大小,毛长度等连续型变量符合高斯分布,他们组成的特征向量符合多元高斯分布。
这样,可以给出概率密度函数:
最大似然估计如下:
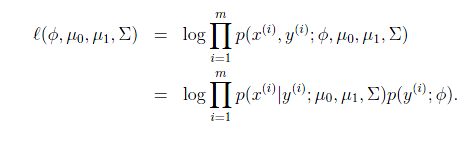
注意这里的参数有两个

,表示在不同的结果模型下,特征均值不同,但我们假设协方差相同。反映在图上就是不同模型中心位置不同,但形状相同。这样就可以用直线来进行分隔判别。
求导后,得到参数估计公式:
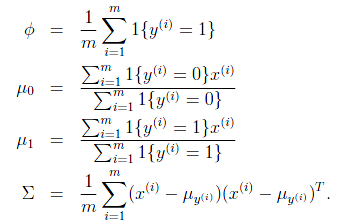
是训练样本中结果y=1占有的比例。
是y=0的样本中特征均值。
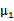
是y=1的样本中特征均值。

是样本特征方差均值。
如前面所述,在图上表示为:
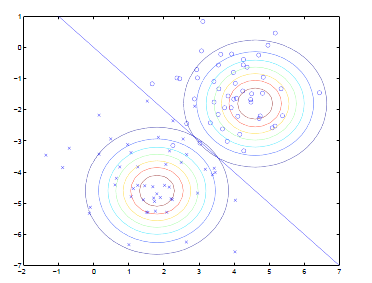
直线两边的y值不同,但协方差矩阵相同,因此形状相同。

不同,因此位置不同。
2.3) 利用高斯判别模型进行分类
a)根据训练样例,利用2.2)中描述的方法计算出了高斯判别模型中的4个参数。
b)对于一个新的待分类数据x,根据下面的式子计算p(x|y=0)*p(y=0)和p(x|y=1)*p(y=1)哪个大,对应的y就是x要归为的类。
2.4)高斯判别分析(GDA)与logistic回归的关系
将GDA用条件概率方式来表述的话,如下:

y是x的函数,其中

都是参数。
进一步推导出
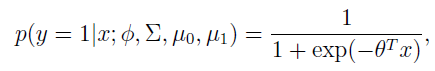
这里的
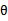
是
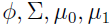
的函数。这个形式就是logistic回归的形式。
也就是说,如果p(x|y)符合多元高斯分布,那么p(y|x)符合logistic回归模型。反之,不成立。为什么反过来不成立呢?因为GDA有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么GDA在训练集上是最好的模型。然而,我们往往事先不知道训练数据满足什么样的分布,更不应该做很强的假设,此时采用logistic回归的方法就比较合适。 例如,如果训练数据满足泊松分布(而不是多元高斯分布),即

,此时p(y|x)仍然是logistic回归的,但不是多元高斯分布,采用GDA效果也会比较差。这也是logistic回归用的更多的原因。
参考:http://www.cnblogs.com/jerrylead/archive/2011/03/05/1971903.html

相关文章推荐
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——14、无监督学习:Independent Component Analysis(ICA)
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——10、无监督学习:Mixture of Gaussians and the EM Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——13、无监督学习:Principal Component Analysis (PCA)
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——12、无监督学习:Factor Analysis
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——2、监督学习:Regression and Classification
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——7、监督学习:Support Vector Machine,立
- 斯坦福大学公开课机器学习课程(Andrew Ng)二监督学习应用 梯度下降
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——11、无监督学习:the derivation of EM Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——9、无监督学习:K-means Clustering Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——5、监督学习:Support Vector Machine,引
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——8、监督学习:Learning Theory
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——15、无监督学习:Reinforcement Learning and Control
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——6、监督学习:Support Vector Machine,破
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——4、监督学习:Naive Bayes
- 斯坦福大学公开课机器学习课程(Andrew Ng)五生成学习算法
- 斯坦福大学公开课机器学习课程(Andrew Ng)第一讲机器学习动机与应用
- 斯坦福大学公开课机器学习课程(Andrew Ng)三欠拟合与过拟合
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——1、整体看一看
- 国际名校公开课 斯坦福大学公开课 :机器学习课程 机器学习的动机与应用 学习笔记
- 斯坦福大学公开课机器学习课程(Andrew Ng)六朴素贝叶斯算法