数据挖掘回顾四:分类算法之 logistic回归 算法
2015-04-06 21:19
218 查看
logistic回归是分类算法中最璀璨的一个算法。在研究两分类相应变量(即只有类别0和类别1)与诸多自变量(即每条数据的各个特征变量)之间的相互关系时,常常选用logistic回归模型。
关于logistic回归分类算法,《机器学习实战》一书中说的不是很好。
在博客 http://blog.csdn.net/dongtingzhizi/article/details/15962797 中,博主洞庭之子对其介绍已经相当清楚了,我们应该对博主表示感谢。但对于数据挖掘的初学者来说,看完此文之后,或许仍有一些疑问之处。下面总体上说一下logistic回归分类算法,并且对洞庭之子的那篇博文,做一些小小的注释说明。希望对大家有所帮助。
1,logistic回归也是一种有监督的学习算法,即是有训练集的。在几何层面上,回归的意思,就是我们是否可以找一条线,这条线可以把训练集中的两类数据比较好的分割开来,直线的一侧是类别0中的数据,另一侧是类别1中的数据。这条线就叫做最佳拟合直线,求这条直线的迭代过程就称为回归。然后对于,待分类的一条测试数据,代入拟合直线,看结果在直线的哪一侧,就能得到测试数据的类别。
2,符号假设说明:假设训练集中有100条数据,类别用y表示,每条数据的特征向量用x=(x1,x2,...,xn)表示,最佳拟合直线用z=a0+a1*x1+...+an*xn表示,其中a=(a0,a1,...an)为直线的系数。
3,logistic回归通过计算拟合极大似然函数()求最佳拟合直线。似然函数就是联合概率,极大似然函数就是极大联合 概率。对于训练集中的第i条数据xi,我们已经知道,它的类别yi,其中i=1,....,100,yi的值是0或1。则在离散层面
上,
概率P(yi|xi)=1。那么也就是要,我们模拟一个极大似然函数,使得模拟的联合概率P(y1,y2,...,y100|a,x)无限
接近于满足P(y1,y2,...,y100|x)这样一个个的事实。而对于训练集中的100条数据,
P(y1,y2,...,y100|a,x)=P(y1|a,x1)*P(y2|a,x2)*...*P(y100|a,x100)
P(y1,y2,...,y100|x)=P(y1|x1)*P(y2|x2)*...*P(y100|x100)
所以在实际操作中,本段红色的那句话的意思就是说,怎样构造一个极大似然函数,使得上面两个等式中的前者 无限接近于满足后者。
4,对于洞庭之子的博客,说明如下两个截图:

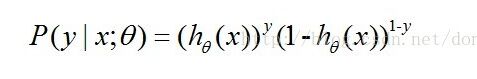
关于第一个图中画红线的地方,可能引起疑问,此处说明两点。一,对于训练集中的那100条数据,我们 要把h(x)看成是一个越阶函数,即只输出0或1。二,而P(yi|xi)=1,i=1,...,100。所以, 红线中更加合理的说法应该是:h(x)的值表示类别y的值,而上面第二个图中的式子才是真正地表示概率P(y)。
联合本文的这几个说明,再加上洞庭之子的那篇博文,和《机器学习实战》中的相关内容。相信大家可以 对Logistic回归会有更加清晰的认识了。

相关文章推荐
- 数据挖掘回顾二:分类算法之 决策树 算法 (ID3算法)
- 数据挖掘回顾六:分类算法之 AdaBoost 集成算法
- 数据挖掘回顾一:分类算法之 kNN 算法
- 数据挖掘回顾五:分类算法之 支撑向量机(SVM) 算法
- 数据挖掘回顾三:分类算法之 朴素贝叶斯 算法
- 数据挖掘算法分类别示例
- 数据挖掘系列(6)决策树分类算法
- 数据挖掘-决策树ID3分类算法的C++实现
- 数据挖掘十大经典算法(10) CART: 分类与回归树
- 【z】 数据挖掘中分类算法小结
- 数据挖掘算法--分类与预测笔记
- 数据挖掘中分类算法小结
- 数据挖掘分类算法比较
- 数据挖掘分类算法之决策树(zz)
- 数据挖掘系列(7)分类算法评价
- 数据挖掘十大经典算法(10) CART: 分类与回归树
- 数据挖掘十大经典算法(10) CART: 分类与回归树
- 数据挖掘分类算法比较
- 数据挖掘中分类算法小结
- 数据挖掘十大经典算法学习之C4.5决策树分类算法及信息熵相关