数据挖掘算法--分类与预测笔记
2013-08-15 14:39
555 查看
分类和预测是两种数据分析形式,可以用于提取描述重要数据量的模型或预测未来的数据趋势。然而,分类是预测分类标号,而预测建立连续值函数模型。
数据分类两过程:
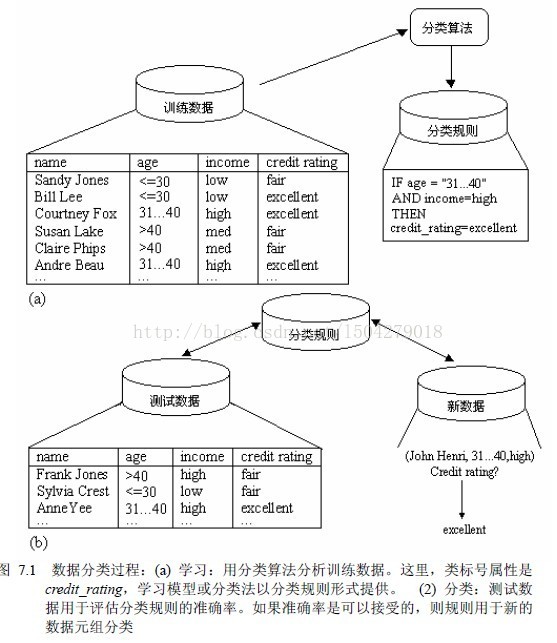
1.建立模型,描述预定的数据类或概念集。学习模型用分类规则、判定树或数学公式的形式提出。
2.使用模型进行分类。利用测试集评估模型的预测准确率,如果准确率可以接受,可以用来对未知数据元组分类。
预测是构造和使用模型评估无标号样本,或者评估给定样本可能具有的属性值或值区间。
分类和回归时两类主要预测问题。其中,分类是预测离散或标称值,而回归用于预测连续或有序值。
关于分类和预测的问题:
准备分类和预测的数据:数据清洗、相关性分析、数据变换
分类好坏的指标:预测的准确率、速度、鲁棒性、可规模性、可解释性。
用判定树归类分类:

判定树归纳:
判定树归纳的基本算法是贪心算法,它以自定而下递归的划分-控制方式构造判定树。算法的基本策略是:
(1)树以代表训练样本的单个节点开始。
(2)如果样本在同一个类,则该节点成为树叶,并用该类标号。
(3)否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好将样本分类的属性。该属性成为该结点的“测试”或“判定”属性。
(4)对测试属性的每个已知的值,创建一个分支,并据此划分样本。
(5)算法使用同样的过程,递归地形成每个划分的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代考虑它。
(6)递归划分步骤停止条件:
(a)给定结点所有样本属于同一类。
(b)没有剩余属性可以用来进一步划分样本。
(c)分支没有样本。
属性选择度量:信息增益熵分析
集成数据仓库技术和判定树归纳:
数据方方法可以与判定树归纳集成,提供交互的判定树的多层挖掘。数据防和存放在概念分成中的知识可以用于在不同的抽象层归纳判定树。
贝叶斯分类:
贝叶斯分类假定一个属性值对给定类的影响独立于其他属性值。该假定称作类条件独立。
贝叶斯信念网络:
贝叶斯分类假定类条件独立。即,给定样本的类标号,属性的值可以条件地相互独立。这一假定简化了计算。当假设成立时,与其他所有分类算法相比,朴素贝叶斯分类最精准的。贝叶斯信念网络说明联合概率分布。这种网络也被称作信念网络、贝叶斯网络和概念网络。
信念网络由两两部分定义。第一部分是有向无环网,每个节点代表一个随机变量,而每条弧代表一个概率依赖。如果一条弧由结点y到z,则y是z的双亲或直接前驱,而z是y的后继。给定是双亲,每个变量条件独立于图中的非后继。变量可以是离散的或连续值的。它们可以对应于数据中给定的实际属性,或对应于一个相信形成联系的“隐藏变量”。
1.计算梯度。
2.沿梯度方向前进一小步。
3.重新规格化权值。
后向传播分类

神经网络的主要缺点是其知识的表示。用加权链连接的单元的网络表示的知识很难被人理解。这激发了提取隐藏在训练的神经网络中的知识,并象征地解释这些知识的研究。
方法包括:网络提取规则和灵敏度分析。
网络提取规则对网络剪枝,将一些链、单元或活跃值聚类,分析每个隐藏单元的活跃值与对应输出单元值组合的规则。
灵敏度分析用于估计输入变量对网络输出的影响。
基于源于关联规则挖掘概念的分类
第一种方法基于聚类挖掘关联规则,然后使用规则进行分类。
第二种方法称作关联分类。
第三种方法是CAEP(通过聚集显露模式分类)使用项集支持度挖掘显露模式(EP).
其他分类方法
k-最邻近分类
最邻近分类基于类别学习。训练样本用n维数值属性描述。每个样本代表n维空间一个点。构造距离度量进行分类。
基于案例的推理
基于案例的推理(CBR)分类法是基于要求的。CBR存放样本是复杂的符号描述。给定一个待分类的新案例时,基于案例的推理首先检查是否存在一个同样的训练案例。有则返回附在案例的解上,没有则基于案例的推理搜索具有类似于新案例成分训练案例。
遗传算法
遗传算法创建一个有随机产生的规则组成的初始群体。根据适者生存的元组,形成有当前群体中最合适的规则组成新的群体,以及这些规则的子女。规则的合适度衡量训练样本集分类的准确率。子女通过使用交叉和变异操作创建。规则群体产生新的规则群体的过程继续进化直到每个规则满足预先指定的合适度阀值。
粗糙集方法
粗糙集理论基于给定训练数据内部的等价类建立。形成等价类的所有数据样本是不加区分的。粗糙集用来近似粗略定义这种类.粗糙集可以用于特征归约和相关分析。
预测
线性和多元回归
在线性回归中,数据用直线建模Y = alph + beta*X
alph, beta是回归系数。
beta = sum_{i=1}^s (x-avg(x))(y-avg(y))/sum_{i=1}^s (x_i-avg(x))^2
alph = avg(y)-beta*avg(x)
多元回归分析是线性回归的扩展:Y =alph + beta1*X1+beta2*X2
用最小二乘法求出参数
非线性回归:
多项式回归模型===转化为多元线性回归:X1=X,X2=X^2,....
广义线性模型:对数回归和泊松回归。
分类的准确性
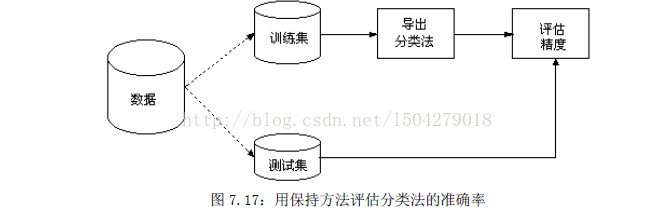
保持(holdout)和k-折交叉确认(k-flod cross-validation)
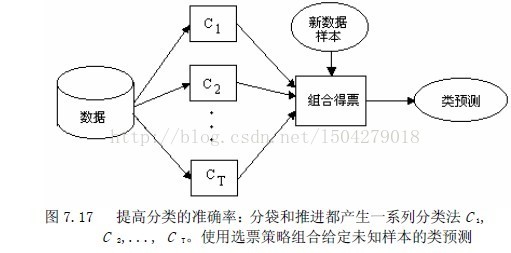
提高分类法准确率的策略:装袋(bagging)和推进(boosting)。
关于分类法准确率和选择的其他问题。
评估分类法的准确率
提高分类法的准确率
数据分类两过程:
1.建立模型,描述预定的数据类或概念集。学习模型用分类规则、判定树或数学公式的形式提出。
2.使用模型进行分类。利用测试集评估模型的预测准确率,如果准确率可以接受,可以用来对未知数据元组分类。
预测是构造和使用模型评估无标号样本,或者评估给定样本可能具有的属性值或值区间。
分类和回归时两类主要预测问题。其中,分类是预测离散或标称值,而回归用于预测连续或有序值。
关于分类和预测的问题:
准备分类和预测的数据:数据清洗、相关性分析、数据变换
分类好坏的指标:预测的准确率、速度、鲁棒性、可规模性、可解释性。
用判定树归类分类:
判定树归纳:
判定树归纳的基本算法是贪心算法,它以自定而下递归的划分-控制方式构造判定树。算法的基本策略是:
(1)树以代表训练样本的单个节点开始。
(2)如果样本在同一个类,则该节点成为树叶,并用该类标号。
(3)否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好将样本分类的属性。该属性成为该结点的“测试”或“判定”属性。
(4)对测试属性的每个已知的值,创建一个分支,并据此划分样本。
(5)算法使用同样的过程,递归地形成每个划分的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代考虑它。
(6)递归划分步骤停止条件:
(a)给定结点所有样本属于同一类。
(b)没有剩余属性可以用来进一步划分样本。
(c)分支没有样本。
属性选择度量:信息增益熵分析
集成数据仓库技术和判定树归纳:
数据方方法可以与判定树归纳集成,提供交互的判定树的多层挖掘。数据防和存放在概念分成中的知识可以用于在不同的抽象层归纳判定树。
贝叶斯分类:
贝叶斯分类假定一个属性值对给定类的影响独立于其他属性值。该假定称作类条件独立。
贝叶斯信念网络:
贝叶斯分类假定类条件独立。即,给定样本的类标号,属性的值可以条件地相互独立。这一假定简化了计算。当假设成立时,与其他所有分类算法相比,朴素贝叶斯分类最精准的。贝叶斯信念网络说明联合概率分布。这种网络也被称作信念网络、贝叶斯网络和概念网络。
信念网络由两两部分定义。第一部分是有向无环网,每个节点代表一个随机变量,而每条弧代表一个概率依赖。如果一条弧由结点y到z,则y是z的双亲或直接前驱,而z是y的后继。给定是双亲,每个变量条件独立于图中的非后继。变量可以是离散的或连续值的。它们可以对应于数据中给定的实际属性,或对应于一个相信形成联系的“隐藏变量”。
1.计算梯度。
2.沿梯度方向前进一小步。
3.重新规格化权值。
后向传播分类
神经网络的主要缺点是其知识的表示。用加权链连接的单元的网络表示的知识很难被人理解。这激发了提取隐藏在训练的神经网络中的知识,并象征地解释这些知识的研究。
方法包括:网络提取规则和灵敏度分析。
网络提取规则对网络剪枝,将一些链、单元或活跃值聚类,分析每个隐藏单元的活跃值与对应输出单元值组合的规则。
灵敏度分析用于估计输入变量对网络输出的影响。
基于源于关联规则挖掘概念的分类
第一种方法基于聚类挖掘关联规则,然后使用规则进行分类。
第二种方法称作关联分类。
第三种方法是CAEP(通过聚集显露模式分类)使用项集支持度挖掘显露模式(EP).
其他分类方法
k-最邻近分类
最邻近分类基于类别学习。训练样本用n维数值属性描述。每个样本代表n维空间一个点。构造距离度量进行分类。
基于案例的推理
基于案例的推理(CBR)分类法是基于要求的。CBR存放样本是复杂的符号描述。给定一个待分类的新案例时,基于案例的推理首先检查是否存在一个同样的训练案例。有则返回附在案例的解上,没有则基于案例的推理搜索具有类似于新案例成分训练案例。
遗传算法
遗传算法创建一个有随机产生的规则组成的初始群体。根据适者生存的元组,形成有当前群体中最合适的规则组成新的群体,以及这些规则的子女。规则的合适度衡量训练样本集分类的准确率。子女通过使用交叉和变异操作创建。规则群体产生新的规则群体的过程继续进化直到每个规则满足预先指定的合适度阀值。
粗糙集方法
粗糙集理论基于给定训练数据内部的等价类建立。形成等价类的所有数据样本是不加区分的。粗糙集用来近似粗略定义这种类.粗糙集可以用于特征归约和相关分析。
预测
线性和多元回归
在线性回归中,数据用直线建模Y = alph + beta*X
alph, beta是回归系数。
beta = sum_{i=1}^s (x-avg(x))(y-avg(y))/sum_{i=1}^s (x_i-avg(x))^2
alph = avg(y)-beta*avg(x)
多元回归分析是线性回归的扩展:Y =alph + beta1*X1+beta2*X2
用最小二乘法求出参数
非线性回归:
多项式回归模型===转化为多元线性回归:X1=X,X2=X^2,....
广义线性模型:对数回归和泊松回归。
分类的准确性
保持(holdout)和k-折交叉确认(k-flod cross-validation)
提高分类法准确率的策略:装袋(bagging)和推进(boosting)。
关于分类法准确率和选择的其他问题。
评估分类法的准确率
提高分类法的准确率

相关文章推荐
- 数据挖掘笔记-分类-回归算法-梯度上升
- 数据挖掘笔记(2)——分类、数值预测
- 大数据学习笔记之三十九 数据挖掘算法之预测建模
- 大数据学习笔记之四十一 数据挖掘算法之预测建模的回归模型
- [数据挖掘课程笔记]基于规则的分类-顺序覆盖算法(sequential covering algorithm)
- 数据挖掘笔记:分类和预测bayes,svm等
- 数据挖掘笔记-分类-回归算法-最小二乘法
- 大数据学习笔记之四十 数据挖掘算法之预测建模关于决策树模型的介绍
- 【CSDN学院视频】以性别预测为例,谈谈数据挖掘中常见的分类算法
- 数据挖掘笔记:分类和预测,判定树
- 数据挖掘-ionosphere数据集-k近邻算法-分类预测
- 数据挖掘—决策树ID3分类算法的C++实现
- 数据挖掘笔记-分类-决策树-MapReduce实现-2
- 数据挖掘(8):朴素贝叶斯分类算法原理与实践
- 数据挖掘中分类和预测的异同
- 数据挖掘——各种分类算法的优缺点
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 数据挖掘分类算法详解
- 数据挖掘-决策树ID3分类算法的C++实现
- 数据挖掘之分类算法---knn算法(有matlab例子)