数据挖掘回顾十二:关联规则挖掘之 FP-Growth 算法
2015-04-13 17:39
471 查看
1,鉴于Apriori算法需要反复地扫描事务数据库,产生频繁项集候选的数量巨大,并且在计算支持度计数时工作量巨大。
2,为了避免在产生候选时巨大的工作量,J.Han(韩家炜),
J.Pei(裴健),and
Y.Yin 提出了频繁模式增长算法,即本文中要说的FP-Growth 算法。此算法最主要的有点就是避免了产生候选频繁集。
3,FP-Growth
算法利用了如下的性质:局部频繁项由短模式生长出长模式,即先求短的频繁项,然后由短的频繁项衍生出长的频繁项。
4,FP-Growth 算法主要的步骤就是构造一棵 FP 树。如下图:

5,FP 树的优点如下:

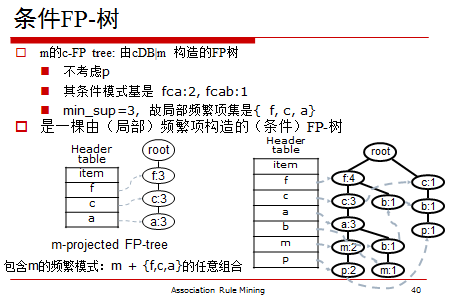
6,条件模式基和条件FP 树:
7,FP-Growth 算法的思想和方法:

8,FP-Growth 算法 PK Apriori 算法:

2,为了避免在产生候选时巨大的工作量,J.Han(韩家炜),
J.Pei(裴健),and
Y.Yin 提出了频繁模式增长算法,即本文中要说的FP-Growth 算法。此算法最主要的有点就是避免了产生候选频繁集。
3,FP-Growth
算法利用了如下的性质:局部频繁项由短模式生长出长模式,即先求短的频繁项,然后由短的频繁项衍生出长的频繁项。
4,FP-Growth 算法主要的步骤就是构造一棵 FP 树。如下图:
5,FP 树的优点如下:
6,条件模式基和条件FP 树:
7,FP-Growth 算法的思想和方法:
8,FP-Growth 算法 PK Apriori 算法:

相关文章推荐
- 关联规则挖掘算法-FP-Growth
- 数据挖掘算法之Apriori和FP-growth
- 挖掘DBLP作者合作关系,FP-Growth算法实践(2):从DBLP数据集中提取信息,三种源码(dom,sax,string)
- 挖掘DBLP作者合作关系,FP-Growth算法实践(1):从DBLP数据集中提取目标信息(会议、作者等)
- 数据挖掘笔记-关联规则-FPGrowth-MapReduce实现
- 数据挖掘 关联规则的FP-growth-tree(FP增长树)的python实现 使用方法
- 基于FPGrowth挖掘算法的乳腺癌中医症型关联规则挖掘
- 数据挖掘笔记-关联规则-FPGrowth-简单实现
- 关联规则挖掘算法-Top Down FP-Growth
- 【数据挖掘算法】关联规则——Fp-tree算法
- 基于FP-tree的关联规则挖掘FP-growth算法基本思想
- 数据挖掘 关联规则的FP-growth-tree(FP增长树)的python实现(一)
- 数据挖掘回顾十一:关联规则挖掘之 Apirori 算法
- 数据挖掘 关联规则的FP-growth-tree(FP增长树)的python实现(二)
- 数据挖掘回顾四:分类算法之 logistic回归 算法
- 数据挖掘算法-Apriori Algorithm(关联规则)
- 数据挖掘回顾六:分类算法之 AdaBoost 集成算法
- 数据挖掘回顾二:分类算法之 决策树 算法 (ID3算法)
- 利用mahout自带的fpgrowth算法挖掘频繁模式