斯坦福大学公开课 :机器学习课程(Andrew Ng)——15、无监督学习:Reinforcement Learning and Control
2015-01-06 19:29
405 查看
在之前的讨论中,我们总是给定一个样本x,然后给出或者不给出label y。之后对样本进行拟合、分类、聚类或者降维等操作。然而对于很多序列决策或者控制问题,很难有这么规则的样本。比如,四足机器人的控制问题,刚开始都不知道应该让其动那条腿,在移动过程中,也不知道怎么让机器人自动找到合适的前进方向;比如,象棋的AI,每走一步实际上也是一个决策过程,虽然对于简单的棋有A*的启发式方法,但在局势复杂时,仍然要让机器向后面多考虑几步后才能决定走哪一步比较好,因此需要更好的决策方法。
对于这种控制决策问题,有这么一种解决思路。我们设计一个回报函数(reward function),如果learning agent(如上面的四足机器人、象棋AI程序)在决定一步后,获得了较好的结果,那么我们给agent一些正回报,得到较差的结果,那么回报函数为负。比如,四足机器人,如果他向前走了一步(接近目标),那么回报函数为正,后退为负。如果我们能够对每一步进行评价,得到相应的回报函数,那么就好办了,我们只需要找到一条回报值最大的路径(每步的回报之和最大),就认为是最佳的路径。
增强学习在很多领域已经获得成功应用,比如自动直升机,机器人控制,手机网络路由,市场决策,工业控制,高效网页索引等。
增强学习的一些重要概念有:马尔科夫决策过程、值迭代和策略迭代法、Q-learning、、、
1)马尔科夫决策过程
MDP的动态过程如下:某个agent的初始状态为
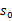
,然后从A中挑选一个动作
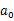
执行,执行后,agent按
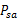
概率随机转移到了下一个
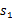
状态,
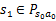
。然后再执行一个动作
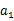
,就转移到了
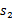
,接下来再执行

…,我们可以用下面的图表示整个过程
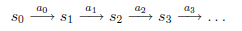
我们定义经过上面转移路径后,得到的回报函数之和如下
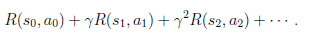
如果R只和S有关,那么上式可以写作
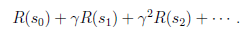
我们的目标是选择一组最佳的action,使得全部的回报加权和期望最大。
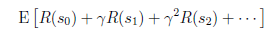
从上式可以发现,在t时刻的回报值被打了
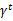
的折扣,是一个逐步衰减的过程,越靠后的状态对回报和影响越小。最大化期望值也就是要将大的
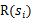
尽量放到前面,小的尽量放到后面。
关于值迭代和策略迭代法,不打算写了,其实比较简单,参考:http://www.cnblogs.com/jerrylead/archive/2011/05/13/2045309.html
比较经典的教材还有:《Machine Learning(Tom M. Mitchell)》第13章Reinforcement Learning。
对于这种控制决策问题,有这么一种解决思路。我们设计一个回报函数(reward function),如果learning agent(如上面的四足机器人、象棋AI程序)在决定一步后,获得了较好的结果,那么我们给agent一些正回报,得到较差的结果,那么回报函数为负。比如,四足机器人,如果他向前走了一步(接近目标),那么回报函数为正,后退为负。如果我们能够对每一步进行评价,得到相应的回报函数,那么就好办了,我们只需要找到一条回报值最大的路径(每步的回报之和最大),就认为是最佳的路径。
增强学习在很多领域已经获得成功应用,比如自动直升机,机器人控制,手机网络路由,市场决策,工业控制,高效网页索引等。
增强学习的一些重要概念有:马尔科夫决策过程、值迭代和策略迭代法、Q-learning、、、
1)马尔科夫决策过程
MDP的动态过程如下:某个agent的初始状态为

,然后从A中挑选一个动作
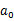
执行,执行后,agent按
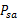
概率随机转移到了下一个
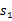
状态,
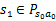
。然后再执行一个动作
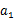
,就转移到了

,接下来再执行

…,我们可以用下面的图表示整个过程
我们定义经过上面转移路径后,得到的回报函数之和如下
如果R只和S有关,那么上式可以写作
我们的目标是选择一组最佳的action,使得全部的回报加权和期望最大。
从上式可以发现,在t时刻的回报值被打了
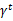
的折扣,是一个逐步衰减的过程,越靠后的状态对回报和影响越小。最大化期望值也就是要将大的
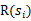
尽量放到前面,小的尽量放到后面。
关于值迭代和策略迭代法,不打算写了,其实比较简单,参考:http://www.cnblogs.com/jerrylead/archive/2011/05/13/2045309.html
比较经典的教材还有:《Machine Learning(Tom M. Mitchell)》第13章Reinforcement Learning。

相关文章推荐
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——2、监督学习:Regression and Classification
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——10、无监督学习:Mixture of Gaussians and the EM Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——5、监督学习:Support Vector Machine,引
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——7、监督学习:Support Vector Machine,立
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——6、监督学习:Support Vector Machine,破
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——13、无监督学习:Principal Component Analysis (PCA)
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——14、无监督学习:Independent Component Analysis(ICA)
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——11、无监督学习:the derivation of EM Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——3、监督学习:Gaussian Discriminant Analysis (GDA)
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——9、无监督学习:K-means Clustering Algorithm
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——8、监督学习:Learning Theory
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——12、无监督学习:Factor Analysis
- 斯坦福大学公开课机器学习课程(Andrew Ng)二监督学习应用 梯度下降
- 斯坦福大学公开课 :机器学习课程(Andrew Ng)——4、监督学习:Naive Bayes
- 深度学习国外课程资料(Deep Learning for Self-Driving Cars)+(Deep Reinforcement Learning and Control )
- 【机器学习-斯坦福】学习笔记21——增强学习(Reinforcement Learning and Control)
- 斯坦福大学公开课机器学习课程(Andrew Ng)五生成学习算法
- 深度学习国外课程资料(Deep Learning for Self-Driving Cars)+(Deep Reinforcement Learning and Control )
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
- 《机器学习》(Machine Learning)——Andrew Ng 斯坦福大学公开课学习笔记(一)