万能cmp程序, 有了他, 建议把其他程序全删掉!

凡是搞计量经济的,都关注这个号了
稿件:econometrics666@126.com
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.

之前,我们引荐了①你的内生性解决方式out, ERM已一统天下而独领风骚(与cmp类似),②二值选择模型内生性检验方法, 步骤及软件code应用(cmp可以替代它),③一个完整的实证程序, 以logit或ologit为例(cmp也可以做),④相亲结婚真的靠谱吗?长得漂亮适合结婚吗?(里面有用到cmp程序)。
正文
关于下方文字内容,作者:蒋泽鸿,英国南安普敦大学经济学,通信邮箱:jiangzehonguk@163.com
cmp简介:别人能做的,我都能做,别人不能做的,我也能做。
*注:如果对文字讲解部分不感兴趣,直接拉到文后的示例代码部分进行演练。
cmp(conditional mixed process,条件混合过程)拟合了一系列多重方程、多级和条件递归混合过程的估计量。
“多重方程”意味着cmp能拟合似不相关(SUR)和工具变量模型。
“多级”是指可以在各个级别上以分层方式对随机系数和效应(截距)进行建模。这类模型的经典示例,是具有不可观察的学校和班级因素对教育结果的影响模型。由于这类模型也可以是多重方程,因此,在默认情况下,允许给定级别的随机效应在方程之间建立相关性。例如,学校和班级因素,可能对学生的数学和阅读分数造成的影响是相关的。但是,我们假定不同级别的影响是不相关的,并且与该观察级别的误差无关。
“混合过程”意味着不同方程可以具有不同种类的因变量(响应类型)。所有具有高斯误差分布的广义线性模型包括:连续和***(经典线性回归模型),tobit(左删失,右删失或双删失),区间删失,probit,有序probit,多项probit和排序probit。对于大多数响应类型,可以对预先删失的截断进行建模。另外,一个等式中的因变量可以出现在另一等式的右侧。
“递归”是指cmp能拟合具有明确定义阶段的方程组,而不能拟合具有联立因果关系的方程组。例如,我们可以将A和B建模为C的决定因素,而C可以作为D的决定因素,但此时D不能作为A,B或C的决定因素。
“条件”是指模型可以根据观察因素而变化。我们可以删除一个与观测值无关的方程式,例如,如果某个城市未提供工人再培训计划,则工人再培训计划不能作为该模型的决定因素。不仅如此,因变量的类型也可以随观察因素而变化。
大致来说,cmp适用于两类模型:1)建立了递归的数据生成过程的模型;2)具有联立性,但通过工具变量可以构造一组递归方程组,如两阶段最小二乘法,可用于在最后阶段一致地估计结构参数。在第一类模型中,cmp是充分信息最大似然(FIML)估计量,并且所有估计的参数都是结构性的。在第二类模型中,它是一个有限信息(LIML)估计量,只有最后阶段的系数是结构性的,其余是简化形式的参数。对于cmp的有效性来说,重要的是方程组是递归的,而不管模型是否是递归的。
cmp的建模框架涵盖了官方的Stata命令,包括probit,ivprobit,treatreg,biprobit,tetrachoric,oprobit,mprobit,asmprobit,asroprobit,tobit,ivtobit,cnreg,intreg,truncreg,heckman,heckprob,xtreg,xtprobit,xttobit,xt,它甚至还包括regress和sureg,以及用户编写的ssm,polychoric,triprobit,mvprobit,bitobit,mvtobit,oheckman,switch_probit和bioprobit。
不仅如此,cmp还在几个方面要优于这些命令。首先,由于ml的灵活性(cmp建立在其基础上),cmp可以接受系数约束以及所有权重类型,vce类型(稳健,聚类,线性化等)和svy设置。而且,它还在模型构建过程中,提供了更大的灵活性。例如,它可以将连续变量回归到两个内生变量上,一个是二值变量,另一个则是左删失的变量,并为每个变量附加其他变量。
cmp通常允许模型根据观察因素而变化。它的方程可以具有不同的样本,无论这些样本是否重叠。另外,Heckman选择模型可以通过辅助的probit方程纳入各种模型中。在某些情况下,所得结果是一致的估计,但在没有cmp以前,很难得到一致的估计。例如,如果C是连续的,B是C的有时左删失的决定因素,而A是一个工具变量,那么我们就可以使用2SLS一致地估计B对C的影响(Kelejian 1971)。但是,如果使用基于B删失的信息,cmp的估计将更有效,因为它基于更准确的模型。
就算法而言,cmp是一个似不相关的回归(SUR)估计量。它将方程视为彼此独立的,只是将它们的潜在误差项建模为联合正态分布。从数学上讲,它计算的似然值取决于观测到的所有右侧变量,包括那些同时还出现在等式左侧的变量。但是,它实际上可以适用于拟合更大范围的模型。例如,包括cmp在内的最大似然(ML)SUR估计量,适用于许多联立方程模型,其中内生变量可以出现在结构方程的右侧和左侧。与 ML SUR一致的这类模型必须满足两个条件:
1)模型是递归的。换句话说,这类模型的方程可以排列成使得彼此方程中因变量的系数矩阵为三角形。如前文所提到的,这意味着模型具有明确定义的阶段,尽管每个阶段可以有多个方程。看看这个“IV和Matching老矣, “弹性联合似然法”成新趋势”,了解递归含义。
2)它们被“充分观察到”。因为一个阶段中的因变量,只有在观察到的情况下,才进入后续阶段。回到上文的示例,如果C是按有序probit建模的分类变量,则C必须在D的模型中出现,而不是该模型基础的潜在变量(称为C *)。
事实上,一些Stata的估计命令具有比许多人所认识到的更广泛的适用性。sureg(X = Y) (Y = Z),isure通常与ivregress 2sls X(Y = Z)完全匹配,即使在Stata中没有将sureg描述为工具变量(IV)估计量(迭代的SUR不是一个真正的ML估计量,但是它近似与基于ML的SUR相同的解决方案,例如,在命令mysureg中实现的方法。有关LIML迭代的SUR连接,请参见Pagan(1979))。 另外,biprobit(X = Y)(Y = Z)将一致地估计X和Y是二进制的IV 模型。bivariate probit模型的工具变量法,也可以通过cmp进行估计。
若要向cmp告知因变量的性质以及哪些方程应用于哪些观察值,用户必须在cmp命令行中的逗号后面包括indicator()选项。另外, 每个方程必须包含一个表达式。表达式可以是常量,变量名称或更复杂的数学公式。同时要注意将包含空格或括号的公式写在引号中间。对于每个观测值,每个表达式必须计算为以下代码之一,其含义如下所示:
0 =观测值不存在该方程的样本中
1 =该观测值的方程是“连续的”,即它具有OLS可能性,或者在tobit方程中是未删失的
2 =这个tobit方程的观测值在因变量中存储为左删失的
3 =因变量中存储的观测值是右删失的
4 =该观测值的方程是probit
5 =该观测值的方程是有率probit
6 =该观测值的方程是多项probit
7 =该观测值的方程是区间删失的
8 =方程在左侧、右侧或两侧同时被截断(这一代码已被弃用,因为截断现在是一般的建模功能)
9 =该观测值的方程是排序probit
为了更加清晰的显示上述代码意义,用户可以执行cmp setup子命令,该命令定义了可以在cmp命令行中使用的共用宏:
$cmp_out = 0
$cmp_cont = 1
$cmp_left = 2
$cmp_right = 3
$cmp_probit = 4
$cmp_oprobit = 5
$cmp_mprobit = 6
$cmp_int = 7
$cmp_trunc = 8
$cmp_roprobit = 9
由于cmp是基于ml的最大似然估计量,所以其方程是根据ml模型的语法指定的。这意味着对于工具变量的回归,cmp与ivregress,ivprobit,ivtobit以及类似的命令的不同之处在于,cmp的第一阶段的第二阶段不会自动包括外生回归变量(包含的工具变量)。因此,你必须自己输入外生回归变量。例如,ivreg y x1(x2 = z)对应于cmp (y = x1 x2) (x2 = x1 z),ind(cmp_cont, cmp_cont)。
为了对随机系数和效应建模,cmp借用了xtmixed(参见,①混合线性模型MEM,层级数据处理利器,②混合效应模型MEM)的语法。我将用具体示例对此进行解释。eq指定一个方程,该方程是具有两个级别的随机效应,分别对应于变量学校和班级定义的组:
(数学成绩 = 年龄 || 学校: || 班级:)
学校被认为在层次结构中班级的“上方” ,因此排随机效应的在第一位。在给定的级别上,可以假定某些方程中存在随机效应,而其他方程中则不存在。在给定级别上,多个方程中的变量被假定为在各个方程之间(潜在地)相关(可以通过约束或covariance()选项覆盖该假设)。下面显示的方程指定了学校对数学成绩的影响,但未指定其对阅读分数的影响,并且数学和阅读分数都与班级影响相关:
(数学成绩 = 年龄 || 学校: || 班级:) (阅读成绩 = 年龄 ||班级:)
上述两个等式中在班级影响的基础上,都增加了年龄的随机系数。这两个新系数可能彼此相关,并且与同一级别的随机截距相关:
(数学成绩 = 年龄 || 学校: || 班级: 年龄) (阅读成绩 = 年龄 ||班级: 年龄)
可以在每个级别指定各种类型的权重,而这应由在给定级别的每个方程组中恒定的变量或表达式来定义。在给定的方程组中,aweights和pweights被重新缩放以求和下一级的组数(如果该组是最低一级的,则为观察值的数量)。pweights表示vce(cluster groupvar),其中groupvar定义层次结构中具有pweights的最高级别。iweights和fweightss未被调整比例,而后者会影响显示的样本规模。由于各个方程的权重必须相同,因此每个级别只需要指定一次即可。所以,下面的两组方程是相同的:
(数学成绩 = 年龄 || 学校: || 班级: [pw=weightvar1]) (阅读成绩 = 年龄 ||班级)
(数学成绩 = 年龄 || 学校: || 班级: [pw=weightvar1]) (阅读成绩 = 年龄 ||班级: [pw=weightvar1])
上述两组方程的矛盾会导致一个误差:
(数学成绩 = 年龄 || 学校: || 班级: [pw=weightvar1]) (阅读成绩 = 年龄 ||班级: [pw=weightvar2])
xtreg,xtprobit,xttobit,xtintreg,xtmixed和gllamm使用正交积分的方式来整合未观察到的随机效应的可能性(请参阅[R] xtmixed),而cmp使用的是模拟。这个模拟过程,涉及根据假设的正态分布进行多次取值,计算每组取值的隐含可能性,然后取平均值(Train 2009;Greene 2011,chap 15)。
为了管理模拟过程,cmp中的随机效应模型必须包含redraws()选项。这将设置每个观察值在每个级别上的取值数量,而关于序列的类型(Halton,Hammersley,广义的Halton,伪随机),它将决定对立的值是否也被取到,以及在Halton和Hammersley caes中,序列是否使用平方根加扰器进行加扰(以上除了加扰的所有概念,请参见Gates 2006,而有关加扰的详细信息,请参阅Kolenikov 2012)。对于(广义的)Halton和Hammersley序列,最好令取值数为素数,以确保不同观测值之间的分布具有更大的变化率,使整体覆盖范围更均匀。
为了增加结果的精确度,我们需要增加取值次数,但这也会增加计算时间。为了提高速度,cmp可以从每个观测值和随机效果(只有在指定的情况下才加上对立值)仅估计一次开始。然后,cmp可以使用该粗略搜索的结果,作为进行更多取值的估计的起点,然后重复进行,每次乘以固定数量直到达到指定的取值数。redraws()的子选项steps(#)默认的步骤数是1。redraws(50 50,steps(1))指定在三个级别的模型中(具有两个级别的随机效应),立即对每次观测值的全部50次取值进行估计。有关该命令更多信息,请参见下面option部分的内容。
在三个或更多数量的方程中(例如具有三个变量的probit模型),被删失的观测值的估计问题,需要计算三个维度或更高维度的累积联合正态分布。我们需要注意这并不是一个小问题。为了解决这个问题,最优的解决办法还是模拟:Geweke,Hajivassiliou和Keane(GHK)的方法(Greene 2011;Cappellari和Jenkins 2003;Gates 2006)。cmp通过单独提供的Mata函数ghk2()运用该算法,必须安装该函数才能使cmp执行该功能。ghk2()以内置的ghk()和ghkfast()为模型,为用户提供有关模拟生成序列的长度和性质的选择,cmp的选择主要通过可选的ghkdraws()选项传递,该选项包括type(),antithetics和 scramble子选项。有关该命令更多信息,请参见下面option部分的内容。
对于模拟的两个领域,即随机系数/效应和使用GHK算法估算的累积正态分布,每个观察值或方程组都有其自己的取值顺序。因此,更改数据集中观测值的顺序将更改估计结果,当然,我们希望它对结果的影响很小。如果使用伪随机序列(ghktype(random))或广义Halton序列(ghktye(ghalton)),则Stata随机数生成器的状态也会对结果产生轻微影响。为了使这些序列具有准确的结果可重复性,每次运行cmp之前,请使用set seed命令将seed初始化为某个选定值。另外,需要模拟估记的运算比不需要模拟估记慢得多。
为了获得整个模型拟合的良好起点,cmp需要先分别拟合每个方程。但是,在该准备步骤中,可能由于收敛困难会使得所报告的参数协方差矩阵出现异常,导致某些回归变量缺少标准误差,或发现变量是共线性的。为了最大化实现收敛,cmp通常会从引起这类问题的方程式中,删除这些回归变量,重新对单方程进行拟合,然后将它们留给完整模型使用, 而nodrop选项可阻止该步骤的实施。
关于区间删失或截断方程的估计
关于具有区间删失观测值方程的估计,需要在等号之前列出两个变量,这在某种程度上遵循了intreg的语法。例如,cmp(y1 y2 = x1 x2),ind($ cmp_int)表示因变量被删失为下限为y1,上限为y2的区间。y1中的缺失值被视为负无穷,y2中的缺失值被视为正无穷。对于y1和y2重合的观测值,不存在删失,并且其可能性与$ cmp_cont相同。
关于具有截断分布方程的估计(它可以是任何模型类型,除了多项和排序probit外),对给定方程使用规定范围内的truncpoints(exp exp)选项可提供截断点。与indicator表达式一样,截断点可以是常量,表达式或变量名,其对缺失值的解释同上一段内容相同。另外,对于该方程而言,系统将自动删除观测值位于截断范围之外的观测值,其示例包含在下文中。
关于多项probit方程的估计
我们可以用两种不同的语法指定多项probit,这些语法大致对应于Stata的命令mprobit和asmprobit。在第一种语法中,用户需要列出一个方程,然后将6($ cmp_mprobit)放在indicator()的括号中,它的因变量将保留每种情况下所做的选择。像mprobit一样,cmp将所有回归变量视为所有替代项的决定因素。不仅如此,cmp针对每个可能的选择,将指定的方程式扩展为具有一个“效用”的方程组。该组中的所有方程均包含所有回归变量,但第一个方程除外。第一个方程对应于因变量的最小值,该最小值作为基础替代项。第二个方程对应于第二个最低值,我们称之为“比例替代项”,这意味着要使结果标准化,其误差项的方差是固定的(其固定值取决于是否调用structural选项,请参见下文)。在第一种语法中,单个eq可以在逗号后包含一个iia选项,以便cmp像mprobit一样施加不相关的替代假设,即cmp将假定效用方程中的误差是不相关的并且具有单位方差。
这类模型没有排除性限制,也没有IIA假设,只要至少一个回归变量因替代项而异,就可以正式确定这类模型(Keane 1992)。但是,Keane强调,如果没有排除性限制,则对此类模型的拟合很有可能不稳定。有两种对cmp施加排除性限制的方法。首先,与mprobit一样,你可以使用约束。
其次,你可以使用cmp的其他多项Probit语法。在这个被称为“特定替代项”的语法中,你可以在cmp命令行中,为每个替代项(包括基本替代项)列出一个方程。另外,不同的方程可能包含不同的回归变量。与asmprobit不同,cmp不会要求出现在多个方程式中的回归变量,在不同替代变量之间具有相同的系数,尽管我们可以通过约束来施加此限制。当使用“特定替代项”的语法时,列出的因变量应该是一组虚拟变量。为此,我们可以使用xi,noomit从潜在的选择变量中生成。第一个方程始终被视为基本替代项,因此在这里你可以通过对方程式重新排序,来控制哪个替代项是基本替代项。通常,出现在所有其他方程中的回归变量应从基本替代项中排除。除非施加约束以减少自由度,否则该模型不会被stata识别(cmp会自动从基本替代项方程中排除该常数)。但是,基本替代项方程中可以包含特定于基本替代项或替代项的严格子集的变量。在第二种语法中,不假定IIA,也不能通过一个选项来实现。但是,它仍然可以通过约束来实现。
为了指定特定替代的多项probit组,请在indicator()中包括表达式,每个表达式的计算结果为0或6(0表示该选择不适用于给定的观察值)。另外,你必须将所有其它内容放在另外的括号中。请注意,与asmprobit不同的是,cmp的数据集应该仍然存在一行内容在每个实例中,而不是每个实例和替代项。因此,每个替代项都必须有一个版本的变量,而不是变量因替代项而异。例如,cmp命令下包含的内容不是单个旅行时间变量会根据旅行方式而变化,而是一个空中旅行时间变量,一个公共汽车旅行时间变量等等。下文也对一个特定替代的多项式案例进行了阐述。
在具有J个选择的多项probit模型中,每个可能的选择都有其自己的结构方程,并包含误差项。而这些误差项,具有一些协方差的结构。但是,我们不可能估计JxJ协方差矩阵的所有项(Train 2003;Long and Freese(2006))。在似然计算中,使用的是非基本替代误差与基本替代误差之差的(J-1)x(J-1)协方差矩阵。因此,默认情况下,cmp就像asmprobit一样,将与这些方程相关的sigma和rho参数解释为表示这些误差差异的特征。为了消除过度的缩放自由度,它将第一个非基本替代方程的误差方差(“比例替代”)限制为2,如果前两个结构方程式的误差为i.i.d标准正态分布(以便它们的差异具有方差2),则无论如何都是如此。
此参数化的缺点是,很难考虑对其再施加其他约束。作为替代项,cmp像asmprobit一样,提供了一种结构选择。如果包含此参数,则cmp将创建一整套参数来描述J结构误差的协方差。为了消除过度的自由度,然后将基本替代误差限制为方差1且与其他误差不相关,并将第二个比例替代项的误差约束也限制为方差1。为了在此选项下施加IIA限制,则应将各种“ atanhrho”和“ lnsig”参数约束为0。下面有一个示例,阐述了如何估计使用和不使用结构参数化的相同IIA模型。
然而,为了结构参数化的直观性是要付出实际代价的 (Bunch(1991),Long and Freese(2006),pp. 325-29)。尽管施加的特定约束集似乎不会造成不良结果,但实际上,它会导致从允许的结构协方差空间,映射到不存在相对差异误差的可能协方差矩阵空间。也就是说,存在正定的(J-1)x(J-1)矩阵,它们是相对差分误差的协方差的有效候选项,它们与具有方差1的前两个替代项的结构误差的假设不兼容,并且,第一个基本替代项的误差与所有其他结构误差无关。而structural选项可以阻止cmp达到最大似然拟合。Long and Freese(2006)描述了如何通过改变等式,来改变哪些替代项是基础替代项和比例缩替代项,这可以使估计量解放出来,从而在结构参数化中找到真正的最大值。
关于排序probit方程的估计
关于排序probit模型的说明和处理,与上面刚刚描述的多项probit的第二种语法几乎相同。首先,必须为所有替代项列出方程。其次,对于每个观察值,这些方程式的indicators必须为0或9,并分组在一组额外的括号中。另外,基本和比例替代项的约束以相同的方式自动施加,structural选项也完全相同。多项probit的第二种语法中有一个与排序probit相关的选项是相反的,它指示cmp将编号较低的排名解释为较高而不是较低的排名。
关于如何实现和加快收敛的提示
如果你无法通过cmp实现收敛,下面这些方法可能会对你有所帮助:
1.使用ml的technique()选项或通过其最大化选项更改搜索参数来更改搜索方法。cmp可以实现上述功能并将结果传递给ml。只要ml发现凹面区域,默认的Newton-Raphson搜索方法就可以很好地执行其功能。在此之前,DFP算法(tech(dfp))通常效果更好,并且可以与tech(dfp nr)混合使用。请参见ml处technique()选项的详细信息。
2.如果估计问题需要GHK算法(该算法具体内容请参见上文),请使用ghkdraws()选项更改模拟序列中每个观测值的取值次数。为了cmp有效运行,默认情况下,它需要的观测值数量是GHK算法的观测值数量的平方根的两倍,即至少三个方程中被删失的观测值数量。对于收敛而言,有时候我们必须通过增加取值次数来提高模拟的准确性,同时,我们可以通过提高搜索精度来加快模拟速度。但是,我们通过每个观测值极少的取值次数就可以实现收敛,但在结果的精度上会有所损失,特别是当观测值数量很大时,例如,当样本量为10,000时,取值次数只有5个(Cappellari和Jenkins 2003)。如果进行更多的取值则会大大延长执行时间。
3.如果收到很多“(not concave)”信息,请尝试difficult选项,该选项指示ml在非凹面区域中使用其他搜索算法。
4.如果搜索看起来在可能性上收敛或者对数可能性在每次迭代中几乎没有变化,但收敛失败,请尝试在逗号后向命令行添加nrtolerance(#)或nonrtolerance选项。这些都是ml选项,用于控制何时宣布实现了收敛(请参见下面的ml_opts)。默认情况下,当对数似然随着连续迭代而变化很小时(在公差范围内,可以通过tolerance(#)和ltolerance(#)选项进行调整),并且计算出的梯度向量足够接近0时,ml就会宣布实现了收敛。另外,这些选项还可以解决其它困难问题,例如具有接近共线性回归的问题,浮点数的不精确性使ml无法完全满足上文提到的第二个条件,可以通过使用nrtolerance(#),将缩放的梯度公差设置为大于其默认值1e-5的值,或者与非公差一起完全消除,从而放宽它的限制。由于存在共线性的风险,当方程的回归矩阵的条件数超过20时,cmp就会发出警告(Greene 2000,p. 40)。
5.通过interactive选项,尝试cmp的交互模式。该选项允许用户通过按Ctrl-Break或等效按钮来中断最大化,研究并调整当前解决办法,然后通过输入ml max重新启动最大化。探索和更改当前解决办法的技术,包括显示当前系数和梯度向量图片和运行ml plot。有关详细信息,请参见help ml,[r] ml和Gould, Pitblado, and Sribney(2006)。另外,cmp在交互模式下运行较慢。
运用cmp的示例
首先,我们需要确定将要使用的数据集:
*以下代码都可以放到Stata里运行得出结果。
. cmp setup . webuse laborsup
. replace fem_inc = fem_inc - 10 //将fem_inc的删失级别设置为0,因为2007年10月之前的ivtobit选项假定它是由于系统故障所致。 #这个代表cmp可以替代reg回归: . reg kids fem_inc male_educ . cmp (kids = fem_inc male_educ), ind($cmp_cont) quietly
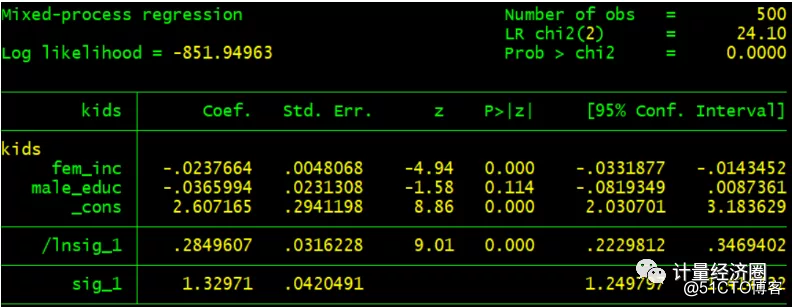
#这个代表cmp可以替代sureg回归:
. sureg (kids = fem_inc male_educ) (fem_work = male_educ), isure . cmp (kids = fem_inc male_educ) (fem_work = male_educ), ind($cmp_cont $cmp_cont) quietly
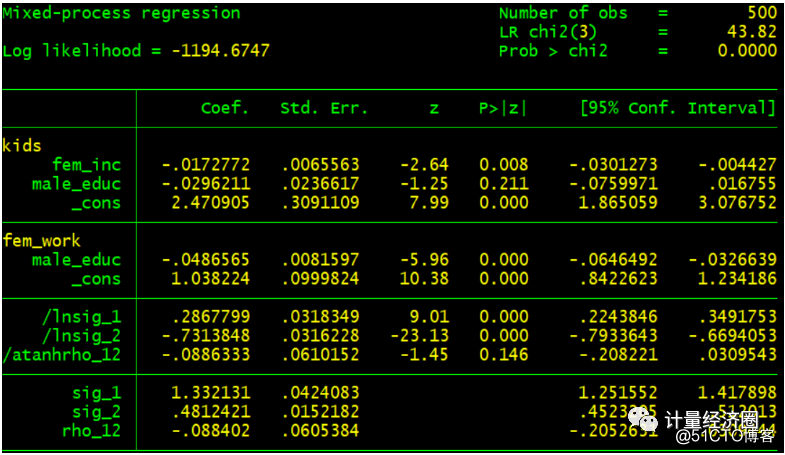
#这个代表cmp可以替代mvreg回归: . mvreg fem_educ male_educ = kids other_inc fem_inc .cmp (fem_educ = kids other_inc fem_inc) (male_educ = kids other_inc fem_inc), ind(1 1) qui
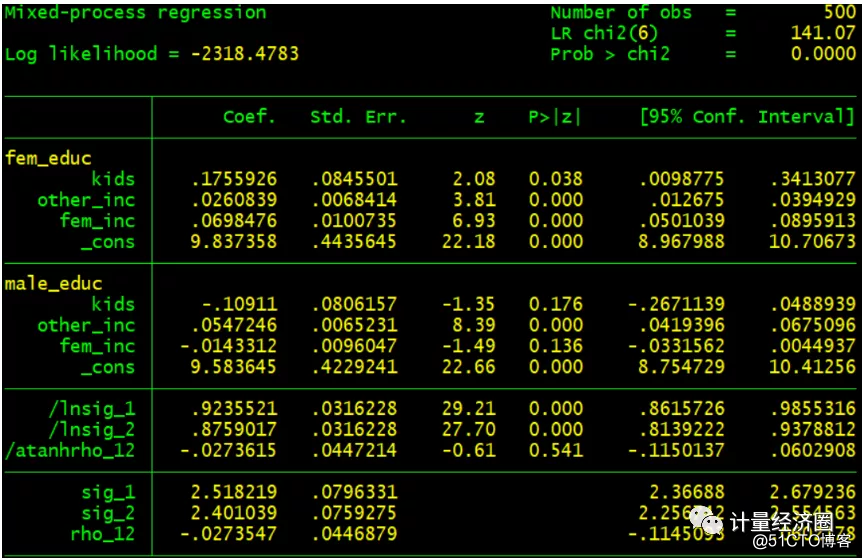
#这个代表cmp可以替代ivreg回归: . ivreg fem_work fem_inc (kids = male_educ), first . cmp (kids = fem_inc male_educ) (fem_work = kids fem_inc), ind($cmp_cont $cmp_cont) qui
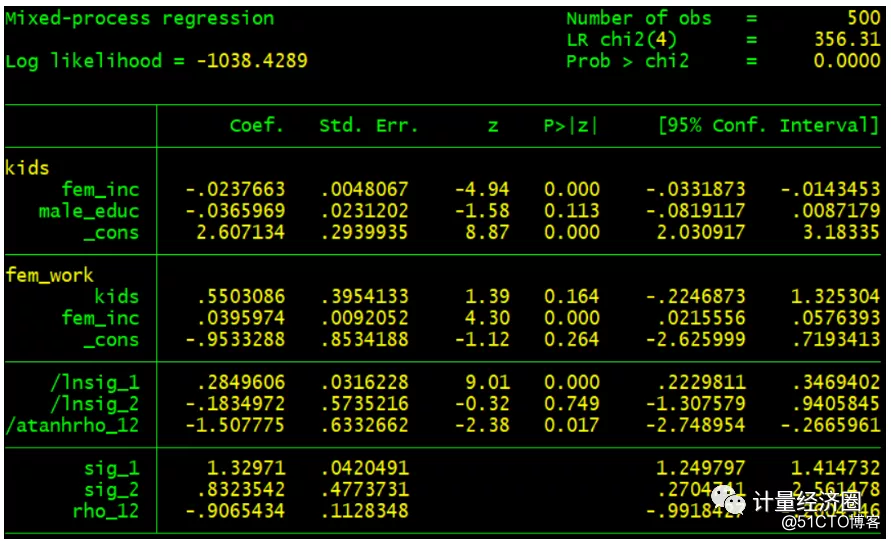
#这个代表cmp可以替代ivregress liml回归: . ivregress liml fem_work fem_inc (kids = male_educ other_inc) . cmp (kids = fem_inc male_educ other_inc) (fem_work = kids fem_inc), ind($cmp_cont $cmp_cont) qui}
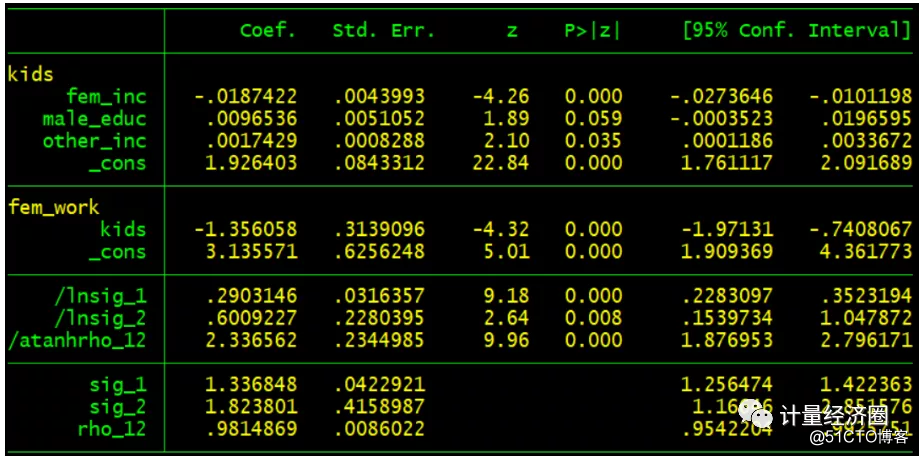
#这个代表cmp可以替代probit回归: . probit kids fem_inc male_educ . predict p . margins, dydx(*) . cmp (kids = fem_inc male_educ), ind($cmp_probit) qui
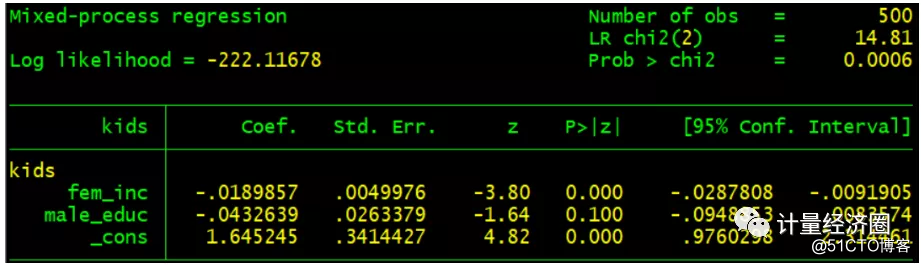
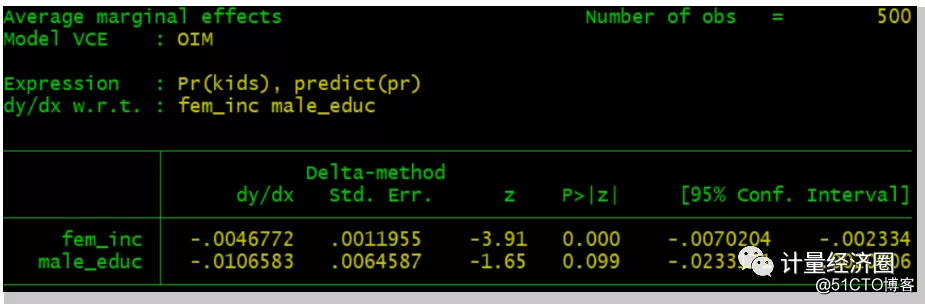
. predict p2, pr . margins, dydx(*) predict(pr)
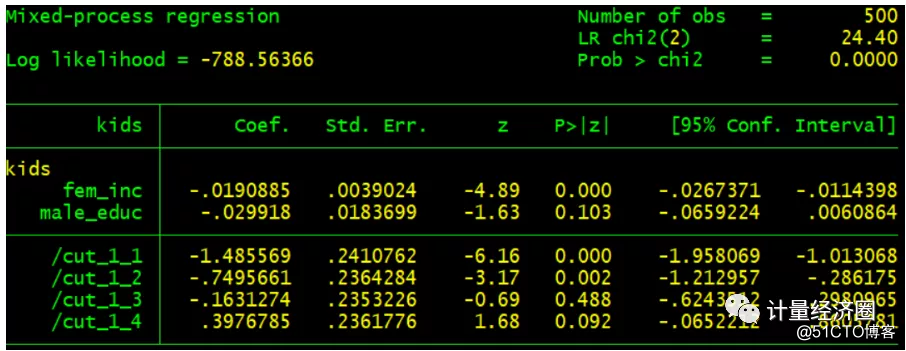
#这个代表cmp可以替代oprobit回归: . oprobit kids fem_inc male_educ . margins, dydx(*) predict(outcome(#2)) . cmp (kids = fem_inc male_educ), ind($cmp_oprobit) qui
. margins, dydx(*) predict(eq(#1) outcome(#2) pr)
. gen byte anykids = kids > 0 #这个代表cmp可以替代biprobit回归: . biprobit (anykids = fem_inc male_educ) (fem_work = male_educ) . cmp (anykids = fem_inc male_educ) (fem_work = male_educ), ind($cmp_probit $cmp_probit)
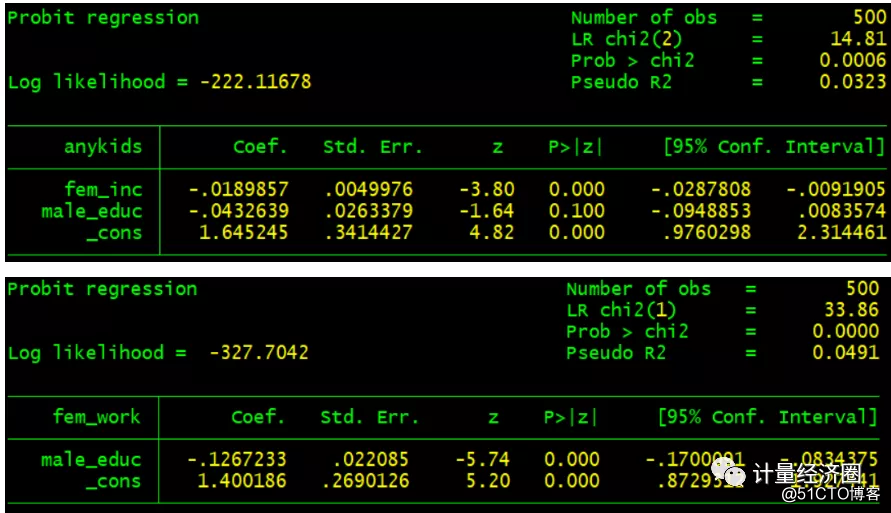
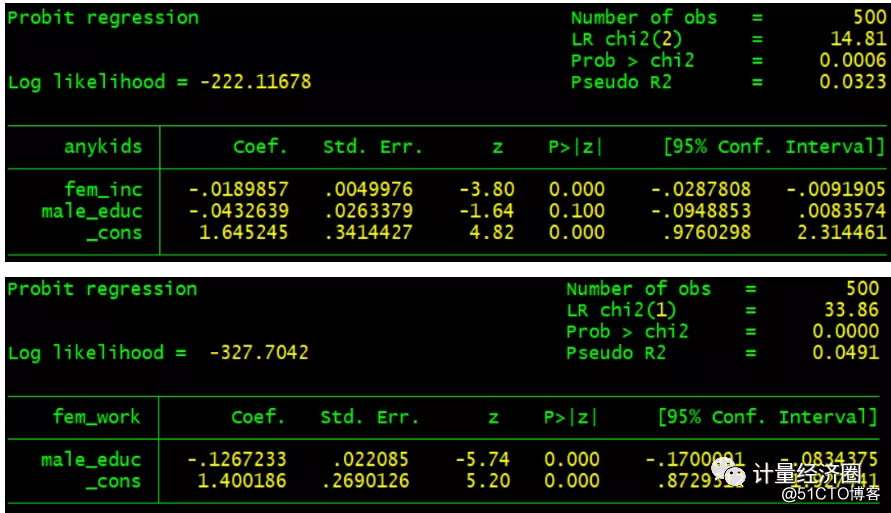
. tetrachoric anykids fem_work . cmp (anykids = ) (fem_work = ), ind($cmp_probit $cmp_probit) nolr qui
#这个代表cmp可以替代ivprobit回归: . ivprobit fem_work fem_educ kids (other_inc = male_educ), first . margins, predict(pr) dydx(*) . cmp (fem_work = other_inc fem_educ kids) (other_inc = fem_educ kids male_educ), ind($cmp_probit $cmp_cont) . margins, predict(pr eq(#1)) dydx(*) force
#这个代表cmp可以替代treatreg回归: . treatreg other_inc fem_educ kids, treat(fem_work = male_educ) . cmp (other_inc = fem_educ kids fem_work) (fem_work = male_educ), ind($cmp_cont $cmp_probit) qui
#这个代表cmp可以替代tobit回归:
. tobit fem_inc kids male_educ, ll
. cmp (fem_inc = kids male_educ), ind("cond(fem_inc, $cmp_cont, $cmp_left)") qui
#这个代表cmp可以替代ivtobit回归:
. ivtobit fem_inc kids (male_educ = other_inc), ll first
. cmp (fem_inc=kids male_educ) (male_educ=kids other_inc), ind("cond(fem_inc,$cmp_cont,$cmp_left)" $cmp_cont)
#这个代表cmp可以替代intreg回归: . preserve . webuse intregxmpl, clear . intreg wage1 wage2 age age2 nev_mar rural school tenure . cmp (wage1 wage2 = age age2 nev_mar rural school tenure), ind($cmp_int) qui . restore
#这个代表cmp可以替代truncreg回归: . preserve . webuse laborsub, clear . truncreg whrs kl6 k618 wa we, ll(0) . cmp (whrs = kl6 k618 wa we, trunc(0 .)), ind($cmp_cont) qui . restore
#这个代表cmp可以替代mprobit回归: . preserve . webuse sysdsn3, clear . mprobit insure age male nonwhite site2 site3 . cmp (insure = age male nonwhite site2 site3, iia), nolr ind($cmp_mprobit) qui . restore
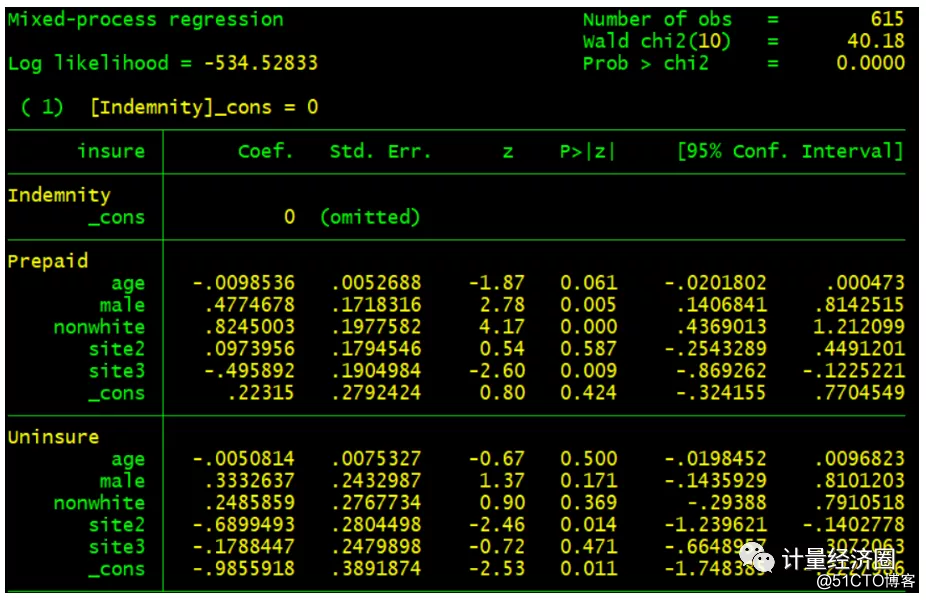
#这个代表cmp可以替代asmprobit回归: . preserve . webuse travel, clear . asmprobit choice travelcost termtime, casevars(income) case(id) alternatives(mode) struct . drop invehiclecost traveltime partysize . reshape wide choice termtime travelcost, i(id) j(mode) . constraint 1 [air]termtime1 = [train]termtime2 . constraint 2 [train]termtime2 = [bus]termtime3 . constraint 3 [bus]termtime3 = [car]termtime4 . constraint 4 [air]travelcost1 = [train]travelcost2 . constraint 5 [train]travelcost2 = [bus]travelcost3 . constraint 6 [bus]travelcost3 = [car]travelcost4 . cmp (air:choice1=t*1) (train: choice2=income t*2) (bus: choice3=income t*3) (car: choice4=income t*4), ind((6 6 6 6)) constr(1/6) nodrop struct tech(dfp) . restore
#这个代表cmp可以替代asroprobit回归: . preserve . webuse wlsrank, clear . asroprobit rank high low if noties, casevars(female score) case(id) alternatives(jobchar) reverse . reshape wide rank high low, i(id) j(jobchar) . constraint 1 [esteem]high1=[variety]high2 . constraint 2 [esteem]high1=[autonomy]high3 . constraint 3 [esteem]high1=[security]high4 . constraint 4 [esteem]low1=[variety]low2 . constraint 5 [esteem]low1=[autonomy]low3 . constraint 6 [esteem]low1=[security]low4 . cmp (esteem:rank1=high1 low1)(variety:rank2=female score high2 low2)(autonomy:rank3=female score high3 low3 (security:rank4=female score high4 low4) if noties,ind((9 9 9 9)) tech(dfp) ghkd(200, ype(hammersley)) rev constr(1/6) . restore
Heckman选择模型
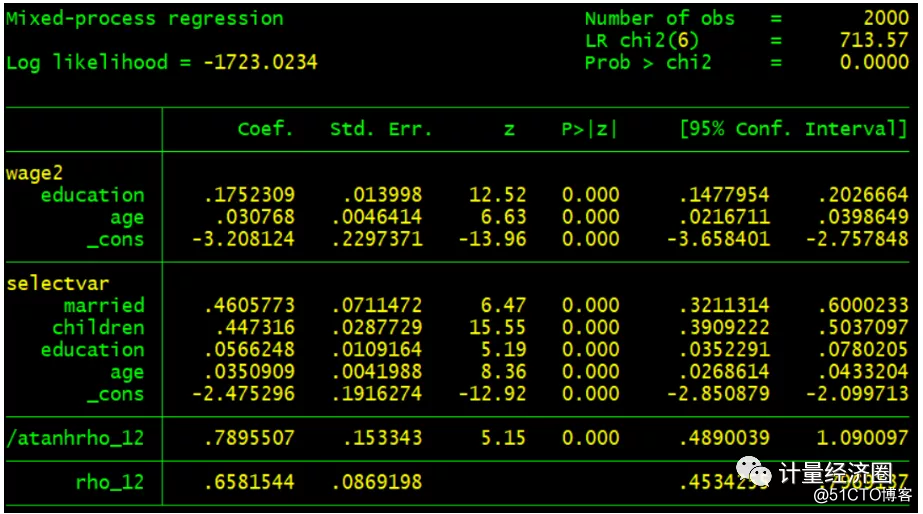
#这个代表cmp可以替代heckman模型: . preserve . webuse womenwk, clear . heckman wage education age, select(married children education age) mills(heckman_mills) . gen selectvar = wage<. . cmp (wage = education age) (selectvar = married children education age), ind(selectvar $cmp_probit) nolr qui . predict cmp_mills, eq(selectvar) . replace cmp_mills = normalden(cmp_mills)/normal(cmp_mills)
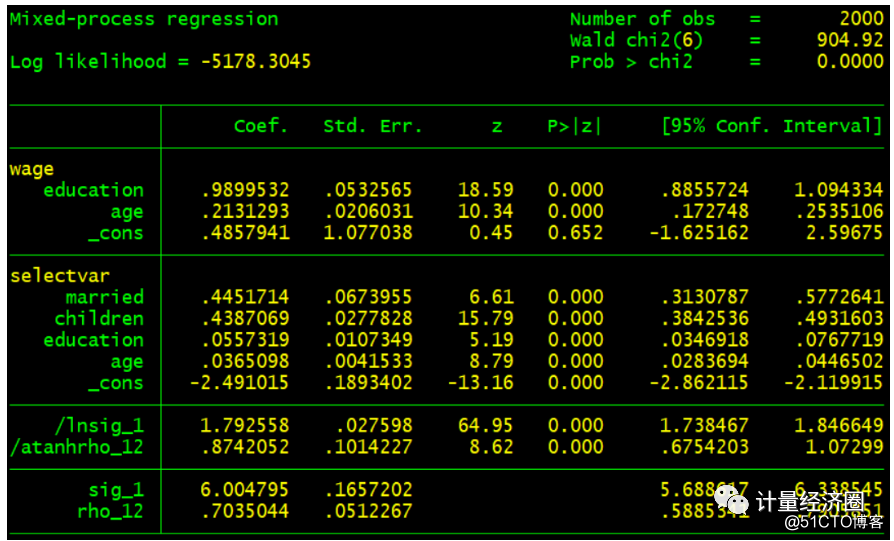
. gen wage2 = wage > 20 if wage < . #这个代表cmp可以替代heckprob回归: . heckprob wage2 education age, select(married children education age) . cmp (wage2 = education age) (selectvar = married children education age), ind(selectvar*$cmp_probit $cmp_probit) qui
分层/随机效应模型
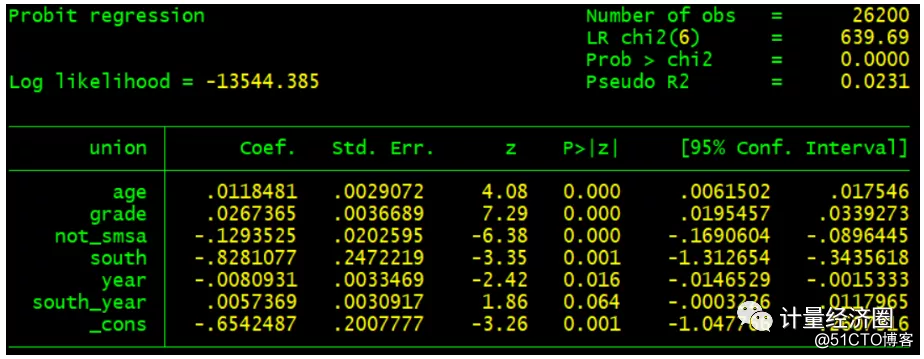
#这个代表cmp可以替代xtprobit回归: . preserve . webuse union, clear . gen double south_year = south * year . xtprobit union age grade not_smsa south year south_year . cmp (union = age grade not_smsa south year south_year || idcode:), ind($cmp_probit) nolr redraws(101, anti) tech(dfp) . restore
#这个代表cmp可以替代xttobit回归:
. preserve
. webuse nlswork3, clear
. gen double south_year = south * year
. xttobit ln_wage union age grade not_smsa south year south_year, ul(1.9)
. replace ln_wage = 1.9 if ln_wage > 1.9
. cmp (ln_wage = union age grade not_smsa south year south_year || idcode:), ind("cond(ln_wage<1.899999, $cmp_cont, $cmp_right)") nolr redraws(101) tech(dfp)
. restore
#这个代表cmp可以替代xtintreg回归: . preserve . webuse nlswork5, clear . gen double south_year = south * year . xtintreg ln_wage1 ln_wage2 union age grade south year south_year occ_code . cmp (ln_wage1 ln_wage2 = union age grade south year south_year occ_code || idcode:), ind($cmp_int) nolr redraws(101, type(hammersley)) tech(dfp) . restore
下面这些示例超出了标准命令的范围:
. webuse laborsup
对工具变量和二值模型的***的连续变量进行回归。两步最小二乘估计(2SLS)的结果是一致的,但效率较低。
. cmp (other_inc = fem_work) (fem_work = kids), ind($cmp_cont $cmp_probit) qui robust . ivreg other_inc (fem_work = kids), robust
现在将左删失的女性收入进行回归,该收入仅针对观察到的从事工作的女性建模。
. gen byte ind2 = cond(fem_work, cond(fem_inc, $cmp_cont, $cmp_left), $cmp_out) . cmp (other_inc=fem_inc kids) (fem_inc=fem_edu), ind($cmp_cont ind2)
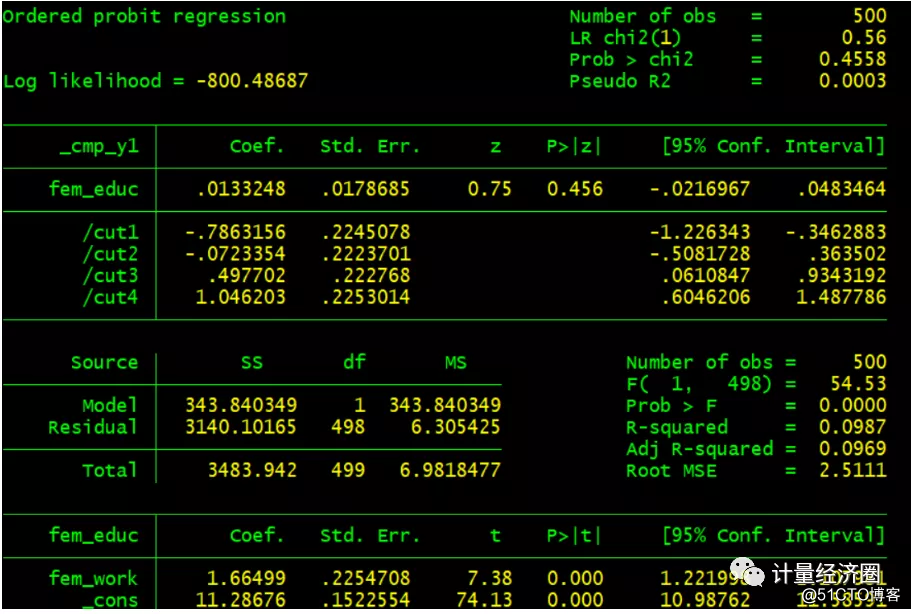
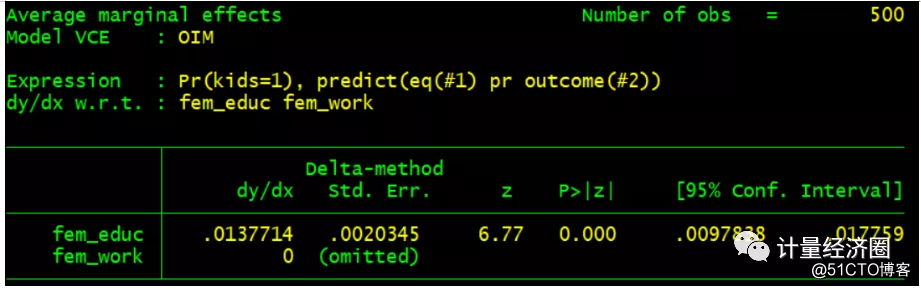
"IV-oprobit": 有序probit的工具变量回归
. cmp (kids = fem_educ) (fem_educ = fem_work), ind($cmp_oprobit $cmp_cont) tech(dfp) nolr . margins, dydx(*) predict(eq(#1) pr outcome(#2)) force

Heckman选择模型的有序probit模型:oprobit模型中存在heckman选择偏差
. preserve . webuse womenwk, clear . gen selectvar = wage<. . gen wage3 = (wage > 10)+(wage > 30) if wage < . . cmp (wage3 = education age) (selectvar = married children education age), ind(selectvar*$cmp_oprobit $cmp_probit) qui . restore
相关的随机系数和随机效应
. preserve . use http://www.stata-press.com/data/mlmus3/gcse, clear . cmp (gcse = lrt || school: lrt), ind($cmp_cont) nolr redraws(101, anti) tech(dfp) . restore
具有异质偏好的多项probit 模型(个体的随机效应)
. preserve . use http://fmwww.bc.edu/repec/bocode/j/jspmix.dta, clear . cmp (tby = sex, iia || scy3:), ind($cmp_mprobit) nolr redraws(47, anti) tech(dfp) . restore
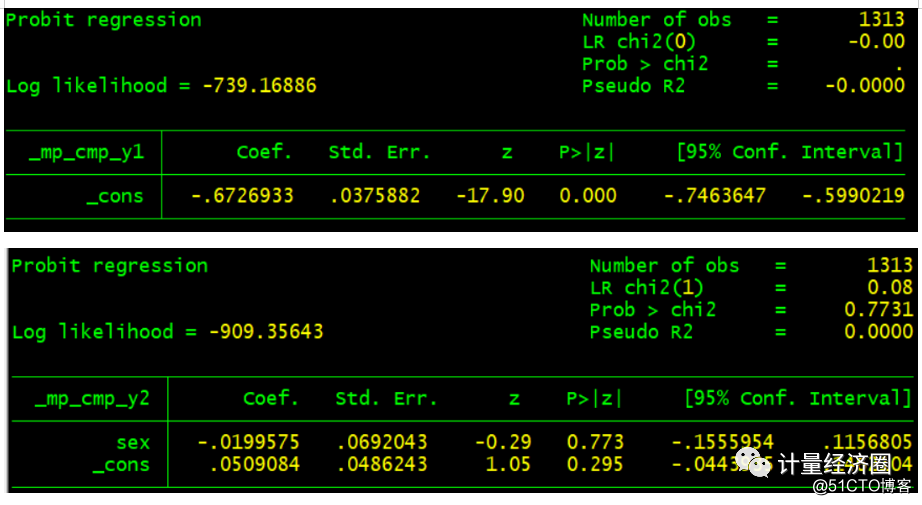
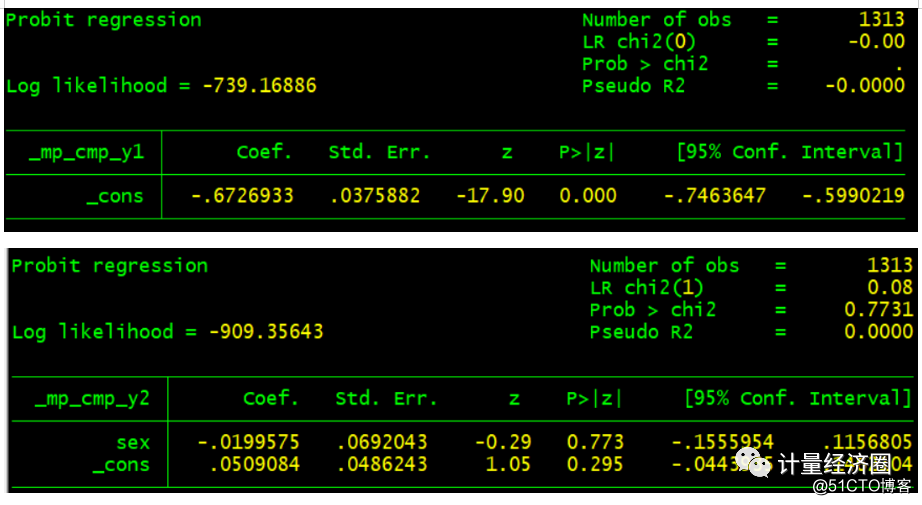
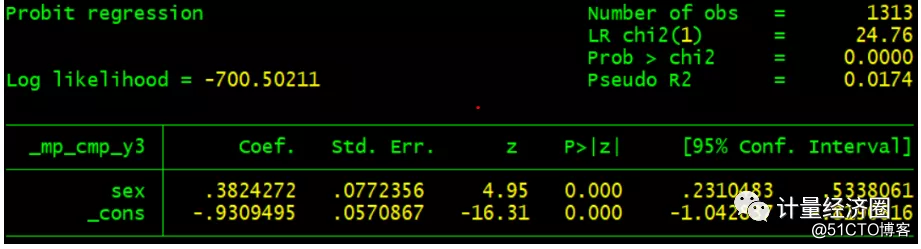
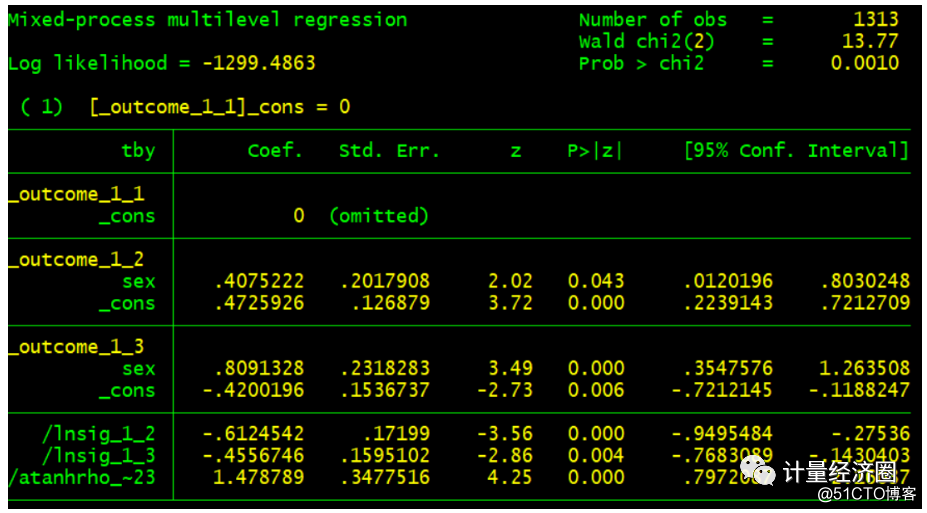
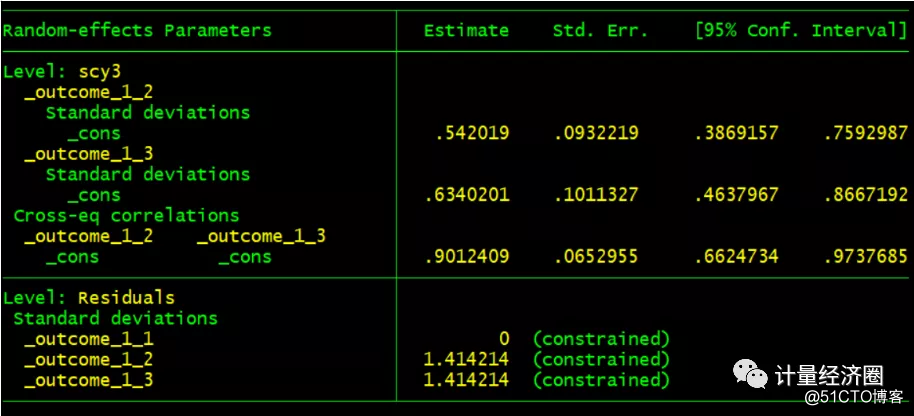
下面这些示例阐述了cmp运行之后,predict的使用方法及其含义:
. webuse laborsup
双变量似不相关的有序probit模型:
. gen byte kids2 = kids + int(uniform()*3) . cmp (kids=fem_educ) (kids2=fem_educ), ind($cmp_oprobit $cmp_oprobit) nolr tech(dfp) qui
预测拟合值。拟合值通常是默认值,另外,第一个方程是默认方程
. predict xbA
预测所有方程拟合值的两种方法
. predict xbB* . predict xbC xbD
获取所有方程和参数的分数
. predict sc*, score
获得观察级别的对数似然值
. predict lnl, lnl
使用第一个方程(默认方程)预测kids=0的两种方法
. predict outcome(0) . predict prB, outcome(#1)
使用第二个方程预测kids2=4的方法
. predict prC, outcome(4) eq(kids2)
预测所有结果和所有方程
. predict prD*, pr
预测所有结果和所有方程,但是两个方程的结果变量名称分别以prE和prF开头
. predict prE prF,
预测所有结果和第二个方程。生成变量prG_Y ,其中Y 是结果编号,而不是结果值
. predict prG, eq(#2) pr
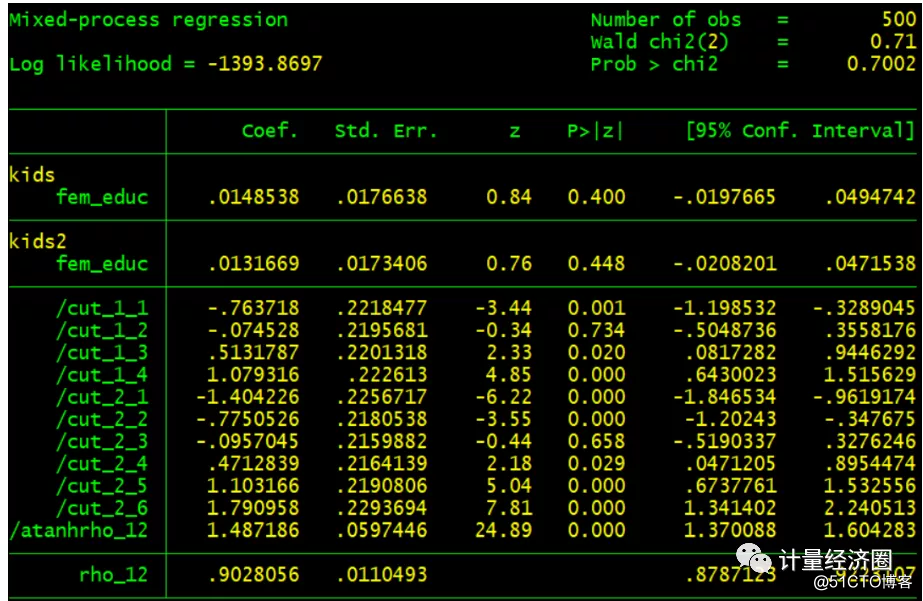
如果觉得不错,为我们点亮“在看”。
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。
2.5年,计量经济圈近1000篇不重类计量文章,
可直接在公众号菜单栏搜索任何计量相关问题,
Econometrics Circle

- UC 国际信息流推荐中的多语言内容理解
- UC 信息流视频标签识别技术
- Java中的IO流 - 入门篇
- 视频 | 深度学习在美图个性化推荐的应用实践
- Linux之Centos8 系统安装
- 阿里妈妈:品牌广告中的 NLP 算法实践
- awk第一行与最后一行
- OCPC 广告算法在凤凰新媒体的实践探索
- 遍历二叉树
- AutoML 技术及应用
- 浅谈 UC 国际信息流推荐
- 三张图秒懂, 混淆, 中介, 调节, 对撞, 暴露, 结果和协变量的复杂关系
- 推荐系统应该如何保障推荐的多样性?
- Cassandra集锦 | Cassandra资料大全&入社区大群邀请
- 阿里云小蜜对话机器人背后的核心算法
- HBase实践 | 数据人看Feed流-架构实践
- AI 在爱奇艺视频广告中的探索
- 华人首次冲进前10!女性经济学家500强名单!在这个学科上中国女性太强了!
- [源码解析] 并行分布式框架 Celery 之 worker 启动 (1)
- 百度机器学习课程 ⑤:如何跨上大数据的战车