HBase实践 | 数据人看Feed流-架构实践
背景
Feed流:可以理解为信息流,解决的是信息生产者与信息消费者之间的信息传递问题。
我们常见的Feed流场景有:
手淘,微淘提供给消费者的首页商品信息,用户关注店铺的新消息等
微信朋友圈,及时获取朋友分享的信息
微博,粉丝获取关注明星、大V的信息
头条,用户获取系统推荐的新闻、评论、八卦
关于Feed流的架构设计,包括以上场景中的很多业内专家给出了相应的思考、设计和实践。本人是大数据方向出身的技术人,所在的团队参与了阿里手淘、微淘Feed流的存储层相关服务,我们的HBase/Lindorm数据存储产品在公有云上也支持着Soul、趣头条、惠头条等一些受欢迎的新媒体、社交类产品。我们在数据存储产品的功能、性能、可用性上的一些理解,希望对真实落地一个Feed流架构可以有一些帮助,以及一起探讨Feed流的未来以及数据产品如何帮助Feed流进一步迭代。
本文希望可以提供两点价值:
Feed流当前的主流架构以及落地方案
一个初创公司如何选择Feed流的架构演进路径
业务分析
Feed流参与者的价值
信息生产者
希望信息支持格式丰富(文字、图片、视频),发布流畅(生产信息的可用性),订阅者及时收到消息(时效性),订阅者不漏消息(传递的可靠性)
信息消费者
希望及时收到关注的消息(时效性),希望不错过朋友、偶像的消息(传递的可靠性),希望获得有价值的消息(解决信息过载)
平台
希望吸引更多的生产者和消费者(PV、UV),用户更长的停留时间,广告、商品更高的转化率
Feed信息传递方式
一种是基于关系的消息传递,关系通过加好友、关注、订阅等方式建立,可能是双向的也可能是单向的。一种是基于推荐算法的,系统根据用户画像、消息画像利用标签分类或者协同过滤等算法向用户推送消息。微信和微博偏向于基于关系,头条、抖音偏向于基于推荐。
Feed流的技术难点
互联网场景总是需要一定规模才能体现出技术的瓶颈,下面我们先看两组公开数据:
新浪微博为例,作为移动社交时代的重量级社交分享平台,2017年初日活跃用户1.6亿,月活跃用户近3.3亿,每天新增数亿条数据,总数据量达千亿级,核心单个业务的后端数据访问QPS高达百万级(来自 Feed系统架构与Feed缓存模型)
截止2016年12月底,头条日活跃用户7800W,月活跃用户1.75亿,单用户平均使用时长76分钟,用户行为峰值150w+msg/s,每天训练数据300T+(压缩后),机器规模万级别(来自 今日头条推荐系统架构设计实践)
上面还是两大巨头的历史指标,假设一条消息1KB那么千亿消息约93TB的数据量,日增量在几百GB规模且QPS高达百万,因此需要一个具备高读写吞吐,扩展性良好的分布式存储系统。用户浏览新消息期望百毫秒响应,希望新消息在秒级或者至少1分钟左右可见,对系统的实时性要求很高,这里需要多级的缓存架构。系统必须具备高可用,良好的容错性。最后这个系统最好不要太贵。
因此我们需要一个高吞吐、易扩展、低延迟、高可用、低成本的Feed流架构。
主流架构
图1是对Feed流的最简单抽象,完成一个从生产者向消费者传递消息的过程。
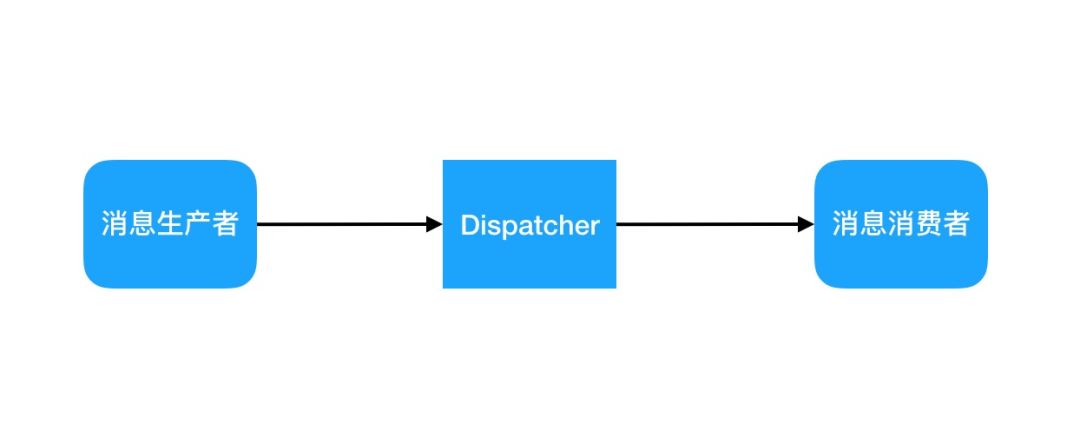
图1 Feed流简单抽象
消息和关系
首先,用户在APP侧获得的是一个Feed ID列表,这个列表不一定包含了所有的新消息,用户也不一定每一个都打开浏览,如果传递整个消息非常浪费资源,因此产生出来的消息首先生成主体和索引两个部分,其中索引包含了消息ID和元数据。其次一个应用总是存在关系,基于关系的传递是必不可少的,也因此一定有一个关系的存储和查询服务。
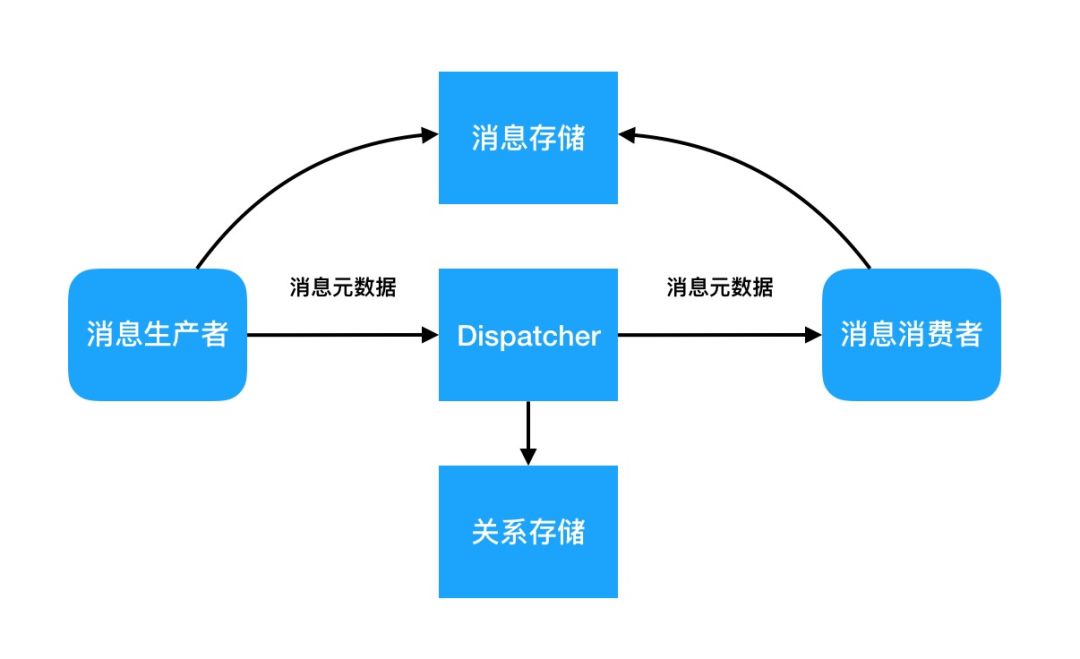
图2 Feed流消息、关系的存储
消息本身应该算是一种半结构化数据(包含文字,图片,短视频,音频,元数据等)。其读写吞吐量要求高,读写比例需要看具体场景。总的存储空间大,需要很好的扩展性来支撑业务增长。消息可能会有多次更新,比如内容修改,浏览数,点赞数,转发数(成熟的系统会独立一个counter模块来服务这些元数据)以及标记删除。消息一般不会永久保存,可能要在1年或者3年后删除。
综上,个人推荐使用HBase存储
HBase支持结构化和半结构化数据;
具有非常好的写入性能,特别对于Feed流场景可以利用批量写接口单机(32核64GB)达到几十万的写入效率;
HBase具备非常平滑的水平扩展能力,自动进行Sharding和Balance;
HBase内置的BlockCache加上SSD盘可以提供ms级的高并发读;
HBase的TTL特性可以自动的淘汰过期数据;
利用数据复制搭建一个冷热分离系统,新消息存储在拥有SSD磁盘和大规格缓存的热库,旧数据存储在冷库。
运用编码压缩有效的控制存储成本,见HBase优化之路-合理的使用编码压缩:
https://yq.aliyun.com/articles/702370
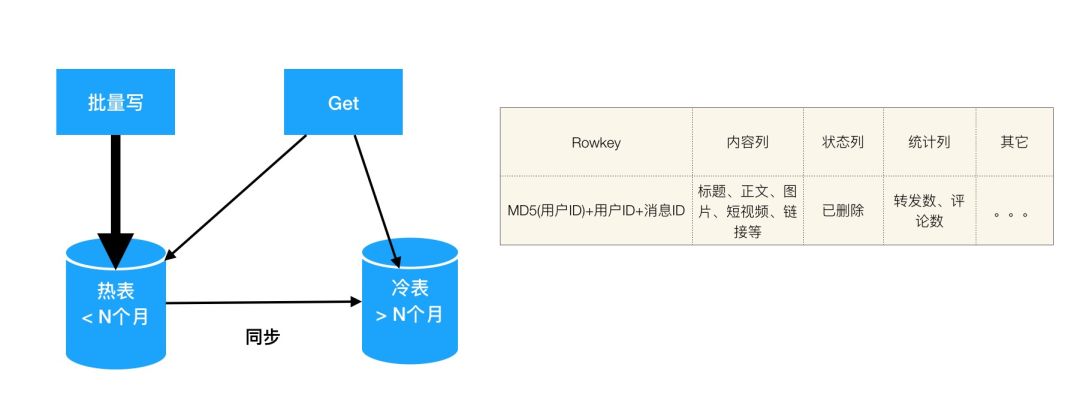
图3 使用HBase存储Feed流消息
对于关系服务,其写入操作是建立关系和删除关系,读取操作是获取关系列表,逻辑上仅需要一个KV系统。如果数据量较少可以使用RDS,如果数据量较大推荐使用HBase。如果对关系的QPS压力大可以考虑用Redis做缓存。
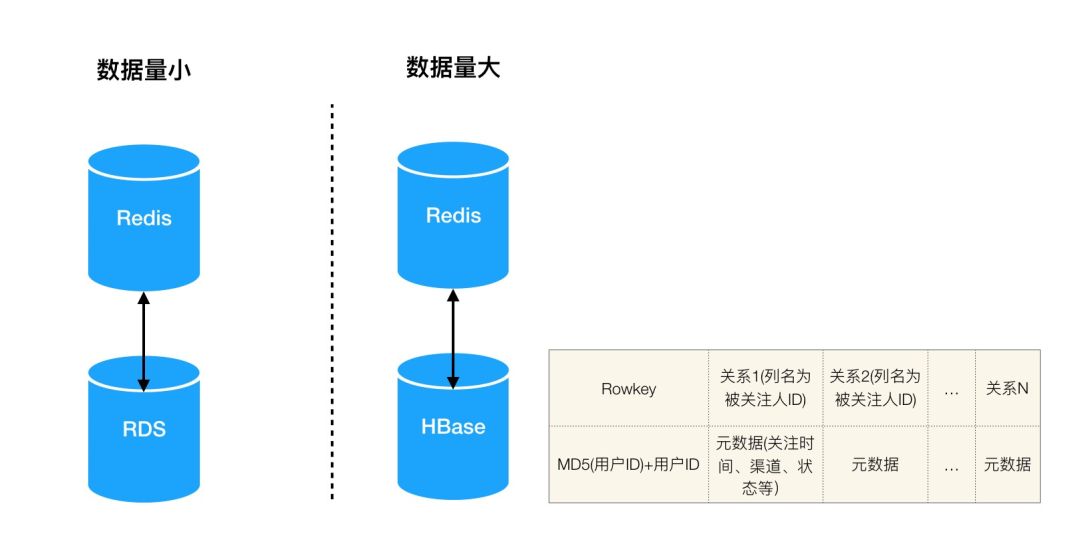
图4 用户关系存储
消息传递
讲到Feed流一定会有关于推模式和拉模式的讨论,推模式是把消息复制N次发送到N个用户的收信箱,用户想看消息时从自己的收信箱直接获取。拉模式相反,生产者的消息写入自己的发信箱,用户想看消息时从关注的M个发信箱中收集消息。
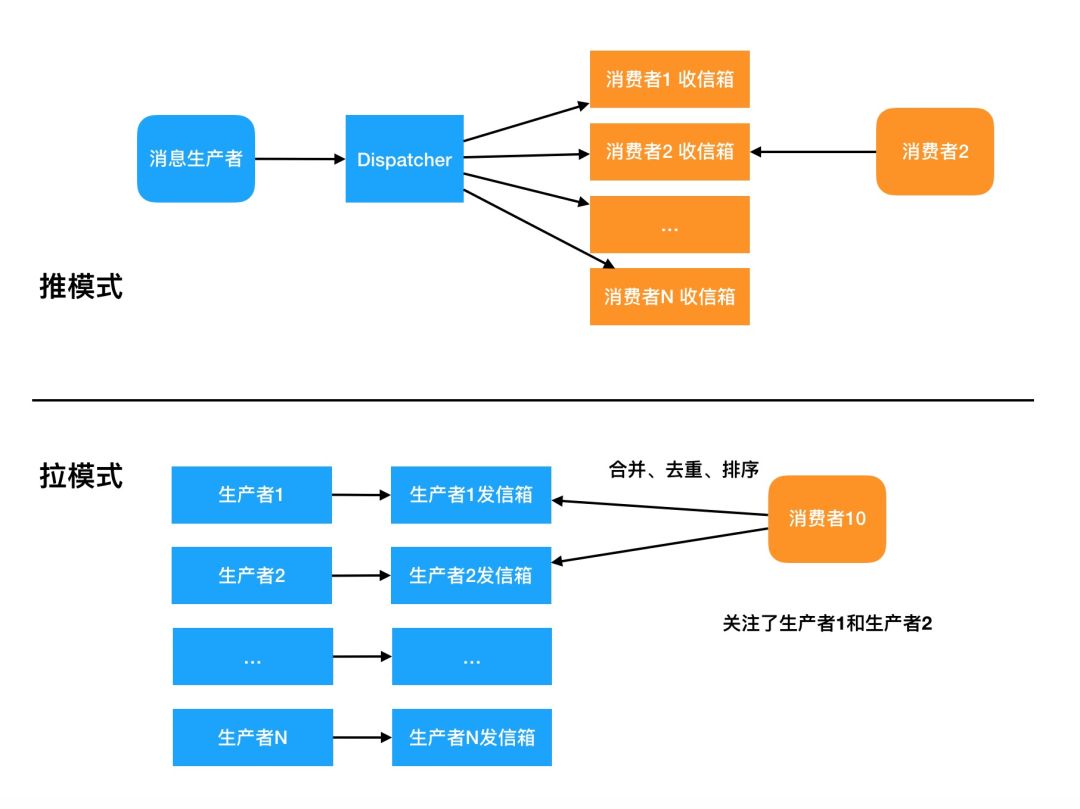
图5 消息传递的推模式和拉模式
推模式实现相对简单,时效性也比较好。拉模式要想获得好的性能需要多级的缓存架构。推模式重写,拉模式重读,Feed流场景下写的聚合效果要优于读,写可以大批量聚合。N越大,写入造成的数据冗余就越大。M越大,读消耗的资源越大。
随着业务的增长,推模式资源浪费会越发严重。原因在于两点:第一存在着大量的僵尸账号,以及大比例的非活跃用户几天或者半个月才登陆一次;第二信息过载,信息太多,重复信息太多,垃圾信息太多,用户感觉有用的信息少,消息的阅读比例低。这种情况下推模式相当一部分在做无用功,白白浪费系统资源。
是推?是拉?还是混合?没有最好的架构,只有适合的场景~
基于关系的传递
图6是纯推模式的架构,该架构有3个关键的部分
异步化。生产者提交消息首先写入一个队列,成功则表示发布成功,Dispatcher模块会异步的处理消息。这一点非常关键,首先生产者的消息发布体验非常好,不需要等待消息同步到粉丝的收信箱,发布延迟低成功率高;其次Dispatcher可以控制队列的处理速度,可以有效的控制大V账号造成的脉冲压力。
多级队列。Dispatcher可以根据消费者的状态,信息的分类等划分不同的处理方式,分配不同的资源。比如对于大V账号的消息,当前活跃用户选择直接发送,保障消息的时效性,非活跃用户放入队列延迟发送。比如转发多的消息可以优先处理等。队列里的消息可以采用批量聚合写的方式提高吞吐。
收信箱。假如有两亿用户,每个用户保留最新2000条推送消息。即便存储的是索引也是千亿的规模。收信箱一般的表结构为用户ID+消息序列 + 消息ID + 消息元数据,消息序列是一个递增的ID,需要存储一个偏移量表示上次读到的消息序列ID。用户读取最新消息 select * from inbox where 消息序列 > offset。
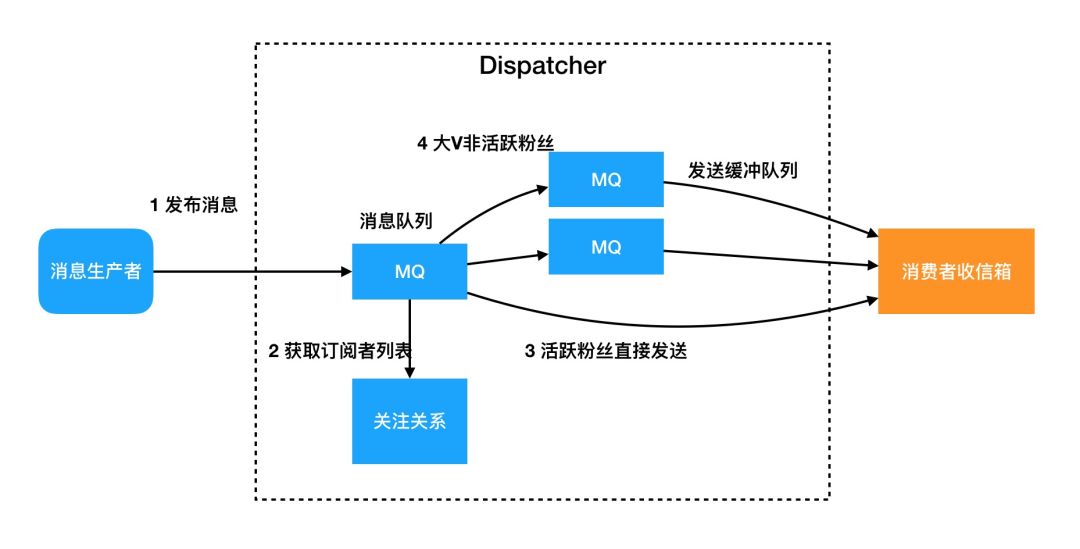
图6 基于关系传递的纯推模式
推荐使用HBase实现收信箱
HBase单机批量写能力在几十万并且可以水平扩展。
HBase的高效前缀扫描非常适合读取最新的消息。
HBase的TTL功能可以对数据定义生命周期,高效的淘汰过期数据。
HBase的Filter过滤器和二级索引可以有效的实现Inbox的搜索能力。
消费者收信箱hbase表设计如下,其中序列号要保证递增,一般用时间戳即可,特别高频情况下可以用一个RDS来制造序列号
| Rowkey | 消息元数据列 | 状态列 | 其它列 |
|---|---|---|---|
| MD5(用户ID)+用户ID+序列号 | 消息ID、作者、发布时间、关键字等 | 已读、未读 |
图7是推拉结合的模式
增加发信箱,大V的发布进入其独立的发信箱。非大V的发布直接发送到用户的收信箱。其好处是解决大量的僵尸账号和非活跃账号的问题。用户只有在请求新消息的时候(比如登陆、下拉消息框)才会去消耗系统资源。
发信箱的多级缓存架构。一个大V可能有百万粉丝,一条热点消息的传播窗口也会非常短,即短时间内会对发信箱中的同一条消息大量重复读取,对系统挑战很大。终态下我们可能会选择两级缓存,收信箱数据还是要持久化的,否则升级或者宕机时数据就丢失了,所以第一层是一个分布式数据存储,这个存储推荐使用HBase,原因和Inbox类似。第二层使用redis缓存加速,但是大V过大可能造成热点问题还需要第三层本地缓存。缓存层的优化主要包括两个方向:第一提高缓存命中率,常用的方式是对数据进行编码压缩,第二保障缓存的可用性,这里涉及到对缓存的冗余。
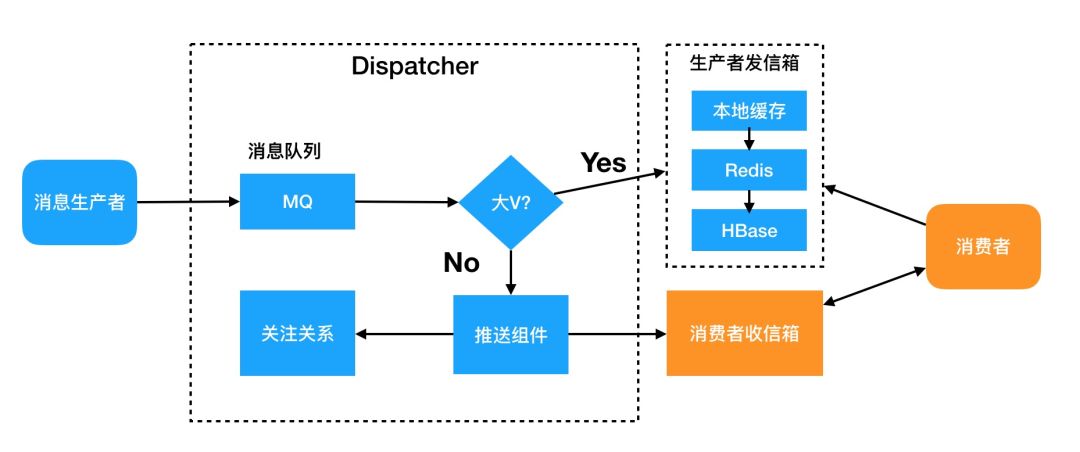
图7 基于关系传递的推拉混合模式
基于推荐的传递
图8是基于推荐的模型,可以看出它是在推拉结合的模式上融合了推荐系统。
引入画像系统,保存用户画像、消息画像(简单情况下消息画像可以放在消息元数据中)。画像用于推荐系统算法的输入。
引入了临时收信箱,在信息过载的场景中,非大V的消息也是总量很大,其中不免充斥着垃圾、冗余消息,所以直接进入用户收信箱不太合适。
收信箱和发信箱都需要有良好的搜索能力,这是推荐系统高效运行的关键。Outbox有缓存层,索引可以做到缓存里面;Inbox一般情况下二级索引可以满足大部分需求,但如果用户希望有全文索引或者任意维度的检索能力,还需要引入搜索系统如Solr/ES
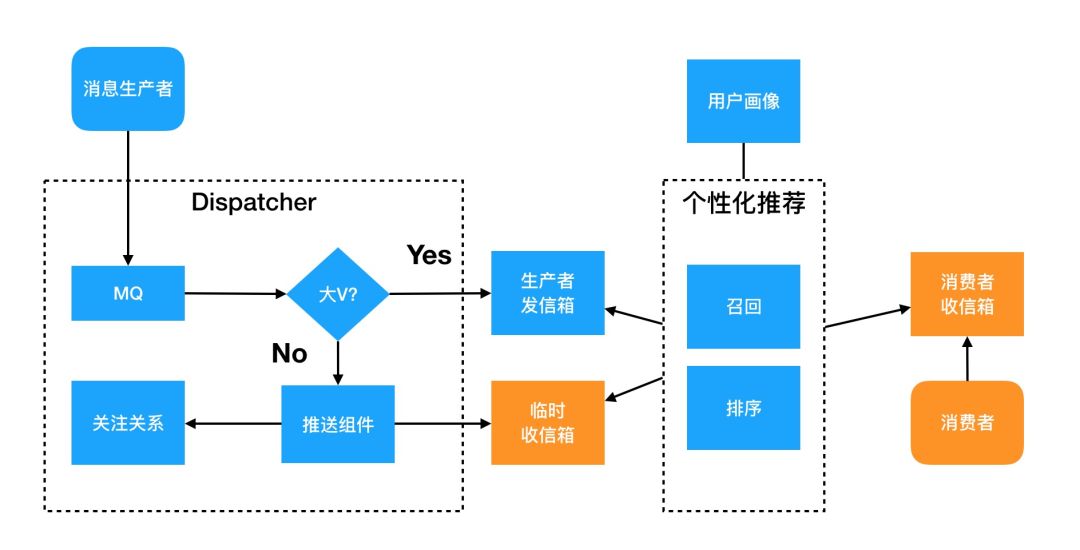
图8 基于推荐的Feed流架构
用户画像使用HBase存储
画像一般是稀疏表,画像总维度可能在200+甚至更多,但单个用户的维度可能在几十,并且维度可能随业务不断变化。那么HBase的Schema free和稀疏表的能力非常适合这个场景,易用且节省大量存储空间。
对画像的访问一般是单行读,hbase本身单行Get的性能就非常好。阿里云HBase在这个方向上做了非常多的优化,包括CCSMAP、SharedBucketCache、MemstoreBloomFilter、Index Encoding等,可以达到平均RT=1-2ms,单库99.9% <100ms。阿里内部利用双集群Dual Service可以做到 99.9% < 30ms,这一能力我们也在努力推到公有云。hbase的读吞吐随机器数量水平扩展。
临时收信箱使用云HBase
HBase的读写高吞吐、低延迟能力,这里不再重复。
HBase提供Filter和全局二级索引,满足不同量级的搜索需求。
阿里云HBase融合HBase与Solr能力,提供低成本的全文索引、多维索引能力。
初创公司的迭代路径
在业务发展的初期,用户量和资源都没有那么多,团队的人力投入也是有限的,不可能一上来就搞一个特别复杂的架构,“够用”就行了,重要的是
可以快速的交付
系统要稳定
未来可以从容的迭代,避免推倒重来
本人水平有限,根据自身的经验向大家推荐一种迭代路径以供参考,如有不同意见欢迎交流
起步架构如图9,使用云Kafka+云HBase。如果对Inbox有检索需求,建议使用HBase的scan+filter即可。
消息分为主体和索引
采用纯推的模式
采用异步化
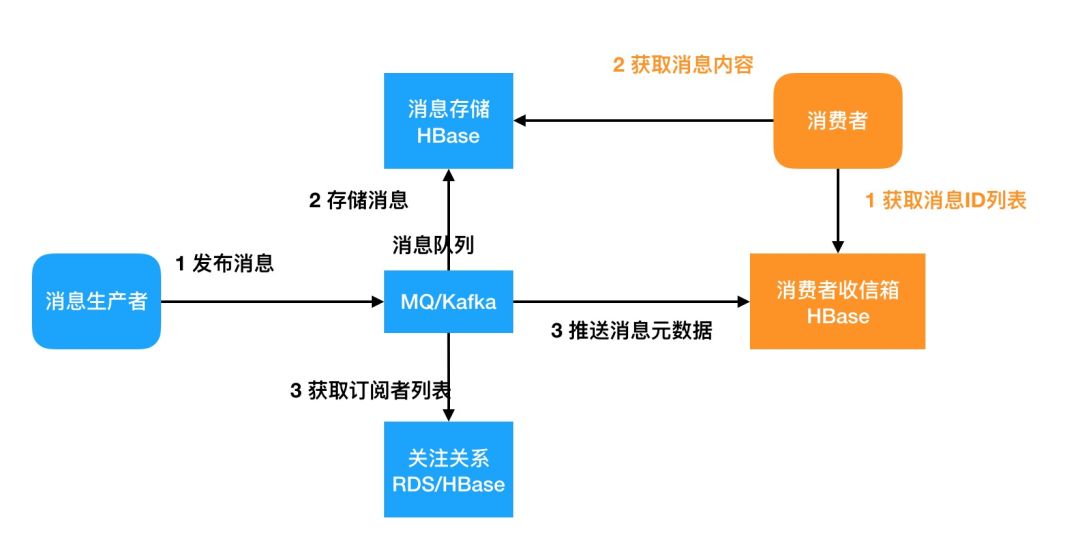
图9 起步架构
数据量逐渐增大后,对推模式进一步迭代,主要需求是
控制大V造成的写入脉冲高峰
控制存储成本
提升读写性能
提升一定的Inbox搜索能力
进一步的迭代架构如图10
消息分为主体和索引
采用纯推的模式
采用异步化
采用多级队列解决大V问题
采用冷热分离降低存储成本
此时Inbox中的消息也很多,对搜索的需求增强,仅仅Scan+Filter不够,可能需要二级索引
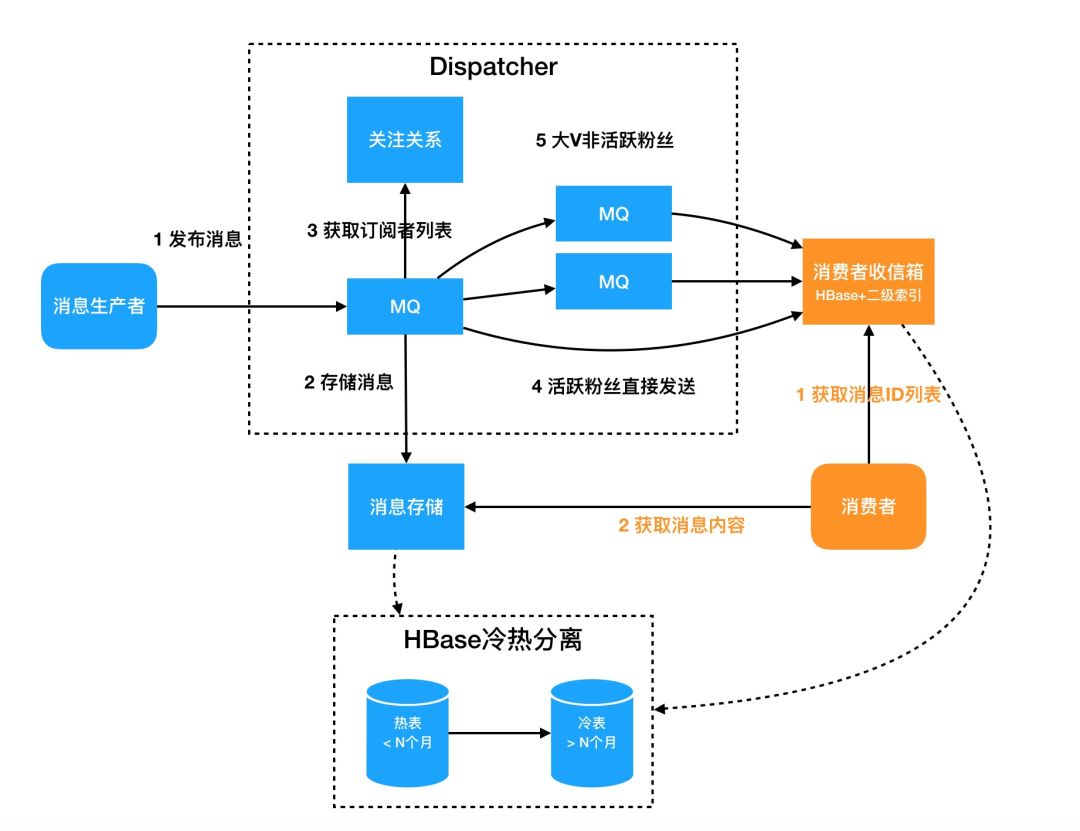
图10 纯推模式的演进
业务迅猛发展,消息和用户增长迅速,僵尸账号、非活跃账号较多,信息过载严重
消息分为主体和索引
采用推拉结合模式
采用异步化
引入推荐系统
采用冷热分离降低存储成本
Outbox采用多级缓存提高读取性能
Inbox增加二级索引提升搜索能力
使用云Kafka+云HBase+云Redis
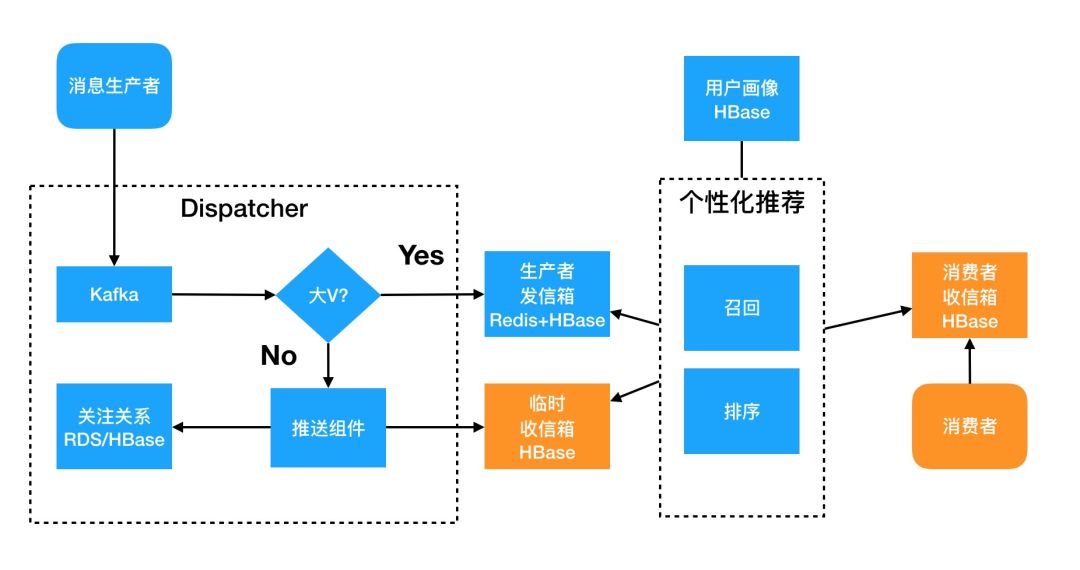
图11 基于推荐的推拉混合架构
总结
Feed信息流是互联网场景中非常普遍的场景,遍布于电商、社交、新媒体等APP,因此研究Feed流是非常有价值的一件事情。本文总结了Feed流的业务场景和主流架构,分析了不同场景、体量下技术的难点与瓶颈。对Dispatcher、Inbox、Outout几个组件进行了详细的演进介绍,提供了基于云环境的落地方案。本人水平有限,希望可以抛砖引玉,欢迎大家一起探讨。Feed流的架构演进还在持续,不同业务场景下还有哪些缺陷和痛点?数据产品如何从功能和性能上演进来支撑Feed流的持续发展?在这些问题的驱动下,云HBase未来将会大力投入到Feed流场景的持续优化和赋能!
参考文献
[1] Feed架构-我们做错了什么
https://timyang.net/architecture/feed-data-arch-cons/
[2] Feed系统架构与Feed缓存模型
https://mp.weixin.qq.com/s/RmDLqQmXQAmtQrajoanNuA?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
[3] 今日头条推荐系统架构设计实践
https://yq.aliyun.com/download/602
[4] 新浪微博架构和FEED架构分析
http://blog.sina.com.cn/s/blog_53b95aec0100ujim.html
[5] feed流个性化推荐架构和算法分享
https://blog.csdn.net/baymax_007/article/details/89853030


- 微博广告策略工程架构体系演进
- 开源框架TLog核心原理架构解析
- 软件架构-zookeeper集群部署与快速入门
- 深度解读:实时数仓架构对比与基于Flink的典型ETL场景实现
- [源码解析] 并行分布式框架 Celery 之架构 (2)
- [源码解析] 并行分布式框架 Celery 之架构 (1)
- 百度直播消息服务架构实践
- 假如你是微博架构师,你会如何设计微博架构?
- Linux系统集群架构线上项目配置实战(一)
- Linux系统集群架构线上项目配置实战(二)
- Linux系统集群架构线上项目配置实战(三)
- 国内那些的求职网站
- K8S中部署mysql-ha高可用集群
- Exchange2016和2019的架构分享
- 一口气说透中台--给你架构师的视角
- 一通百通,一文实现灵活的K8S基础架构!
- 网站整改公告
- 网站整改公告
- 网站整改公告
- 网站整改公告