百度机器学习课程 ⑤:如何跨上大数据的战车

导读:接下来将结合案例继续为大家分享如何跨上大数据的战车,以及对整个第一部分的总结,并预告下第二部分的内容。
▌案例:教育个性化学习路径
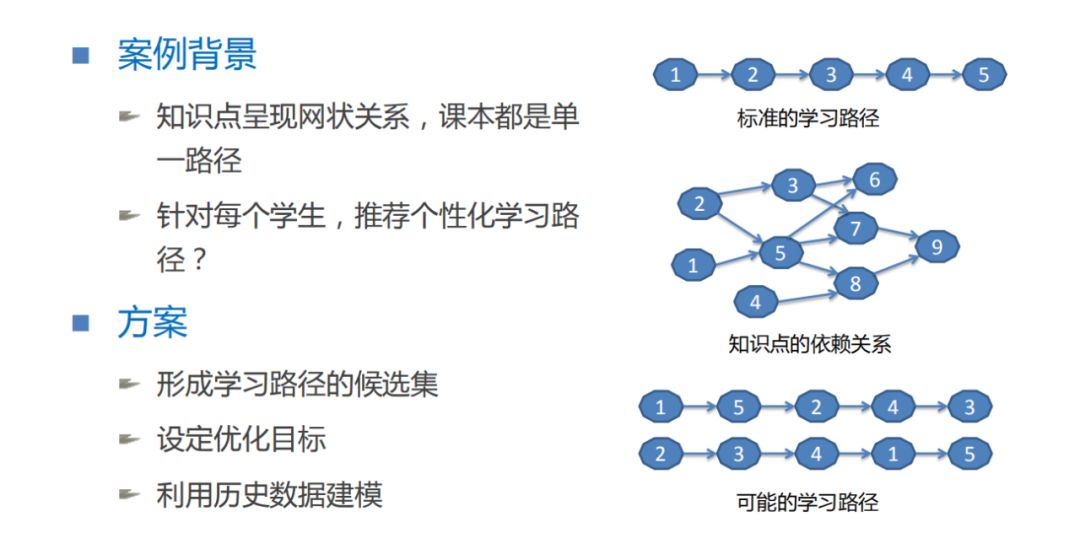
首先我们将通过一个具体的案例,看看是否可以用机器学习的方式去解决它,以及在解决过程中产生的问题与思考。
这是一个教育个性化学习路径的案例。当我们翻开一本几何教材,我们会发现它是一个标准的学习路径:会按照点->线段->三角形->圆的标准学习路径进行学习。实际上,这个学习路径背后知识点的依赖关系往往是一个网状的。这样一个网状知识点的依赖关系,其实可能会产生非常多的可行的学习路径,而不一定是我们书本上现在罗列的这种标准的学习路径,只要不破坏这种网状的知识点依赖的关系就可以。比如说可能今天先要学矩形的面积求解,再学三角形的面积求解,因为三角形的面积求解可能要用到矩形面积的求解,在这样的一个知识点的依赖关系下,我们最好先学前置的一些知识,再学后面的一些知识。
问题是这样的,我们是否可以为每位学生推荐一个个性化的学习路径,而不一定非得按照课本上标准的学习路径进行学习,从而产生一个更好的学习效果。关于这个问题,我们思考一下解决方案,大概可以分三个步骤:
Step 1:首先把所需知识点依赖关系做出来,然后根据知识点依赖关系,生成可能的学习路径的候选集。
Step2:当生成候选集之后,需要设定优化目标,究竟什么样的学习路径对一个同学来说是好的,什么样是不好的。
Step3:利用大量历史的学习这些路径可能的结果,对路径做评分排序,最后我们为每位同学选择最适合他的一个路径,让他进行系统的学习各个知识点。
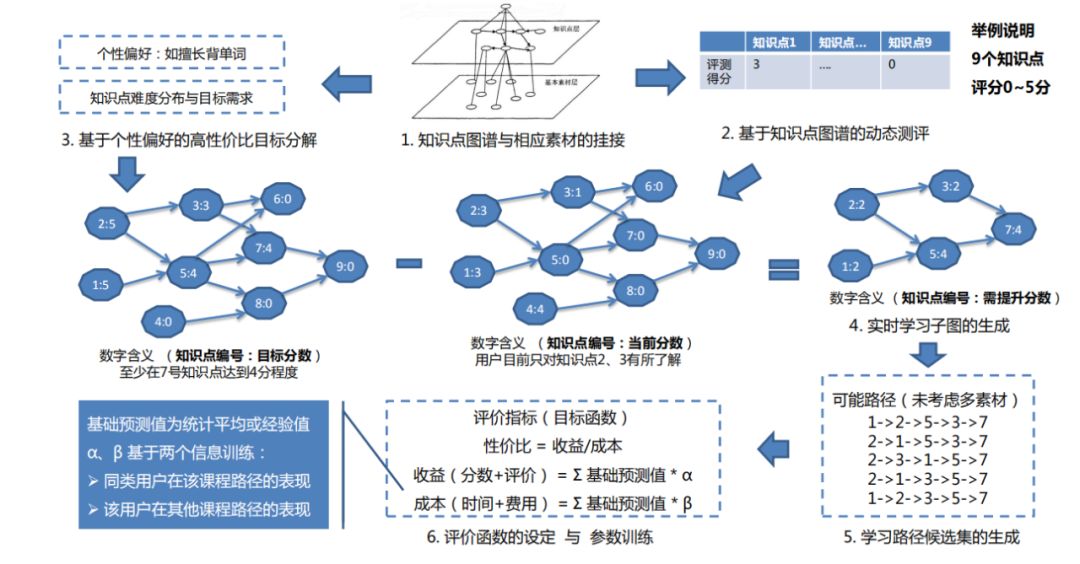
具体的实践步骤为:
1. 知识点图谱与相应素材的挂接。把整个知识点和相应素材的依赖关系的图谱画出来,它是一个上下层的结构,上层为知识点层,下层为基本素材层,它们之间都会有一定的先后的依赖的关系。
2. 基于知识点图谱的动态测评。得到知识点图谱之后,会测评用户目前对知识点的掌握程度。如图2,有9个知识点,每个知识点会对应打0~5分,如果得分是5,表示用户完全掌握了这个知识点,0分,则表示用户完全不知道这个知识点。这样我们基于评测得到了用户对知识点的掌握情况。
3. 基于个性偏好的高性价比目标分解。接下来,会根据用户的个性偏好设定一个目标,比如用户需要完成知识点7,并获得一个较好的分数,那么用户需要对知识点7及和知识点7相关联的知识点1,2,3,5都有一个较好的掌握,也就是基于个性偏好的高性价比目标分解。
4. 实时学习子图的生成。将目标分数和目前掌握的分数做减法,就得到了用户在哪些知识点需要提升的分数,这样我们就得到了一个实时学习的子图。
5. 学习路径候选集的生成。在这个学习图谱的基础上,我们就可以生成用户可能的学习路径候选集。
6. 评价函数的设定与参数训练。最后根据评价指标来对候选集进行排序,选择出一条对用户来说性价比最高的学习路径。性价比(评价指标/目标函数)=成本/收益。其中成本:费用、时间,收益:学习效果以及对这个学习路径的评价等。我们可以通过计算大量的用户历史数据,来训练出这个性价比,也就是评价指标。最后根据训练出的评价指标模型,我们能够预测出对一个具体的用户,一个具体的课程,用户应该选择怎样的一条学习路径。
这就是一个详细的通过历史数据进行机器学习的方案,大致的一个实现过程。
▌思考和反思

我们来反思下这个过程,会不会存在一些问题。我们知道,要建设一个非常好的机器学习任务,需要有四个非常重要的环节:数据、模型、业务和需求。我们来看下,在这四个环节中,会存在哪些问题:
数据:产品从0->1时没有数据
模型:候选路径生成,路径排序,整个流程没有问题
业务:知识结构->测评工具+目标拆解->待提高知识点结构,对于业务来说,我们需要完成几件事情,比如需要事先生成知识图谱的结构,需要有很好的测评工具,能够真实的评判出每一个用户的喜好,还需要知道用户对每个知识点的掌握程度,这些都是不能通过机器学习解决的,需要业务有很多其他的模块和工具。
需求:如果90%同学的最优路径相同。比如我们生成了10条路径,但是我们发现90%同学的最优学习路径是同一条,也就是现在几何课本上的顺序。这意味着这样一个个性化学习路径对用户来说是没有价值的。
我们反思下,其实即使在模型和业务上没有任何问题,还是存在两个比较大的问题:
第一个是在数据环节就存在比较大的问题,因为产品初期是没有任何数据的,这款产品初期在市场上的成功,一定不是依赖于数据技术,需要其他的启动优势。
第二个比较大的问题是需要对用户的需求做更详细的评测。评测出这款产品不只是“假想”,如果发现90%以上同学在课本上的学习路径,就是一条最优路径,那么这个业务一开始就不应该做,因为即使做得再好,也是没有价值的,或者贡献很小。
所以,再次强调,一旦我们用机学习解决业务问题时,不仅仅要考虑模型技术本身,还要对整个的数据、模型、业务和市场有一个非常透彻的理解,把这四个环节串起来,才能形成一个完善的解决方案,我们才能跨上大数据的战车。
▌企业对数据技术及人才的定位

关于企业对数据技术定位的一些观点:
基因论:一旦创业者或者创业团队没有数据技术背景或者机器学习背景时,我们会发现他们选择的项目,往往都会把数据技术排除在外,这样就导致企业很难通过现在的项目来吸引做数据技术的人才,这样就导致了一个恶性循环,进而使企业离竞争对手越来越远。
数据技术往往是在企业发展期才开始起到关键作用,也就是只有当产品在市场上站住脚,用户规模的不断扩大,才会产生海量的用户使用数据,这时我们就可以利用数据技术来进一步优化产品。归结起来就是生存期(0->1)往往没有积累数据,需要其他的产品优势来带动企业的发展,当进入发展期(1->无穷)有了数据积累后,数据技术才开始逐渐发力。
数据技术不是壁垒,数据本身是壁垒,没有任何一项技术永远会是黑科技,但是随着数据的积累,数据本身的价值会越来越大,而这个数据是其它企业拿不到的。
什么样的企业是 AI 企业?只有 AI 工程师的公司不是!因为整个 AI 的应用,是包括对数据、业务、市场需求、模型等方方面面 形成整个的产业理解才能去构建的,并不是几个 AI 工程师会写一些代码就可以实现的,很多时候需要我们整个企业的决策层,甚至企业的产品经理和业务人员全都需要对 AI 有一个非常深入的理解,才能使我们的整个业务产生一个质的变化,最后成为一个 AI 企业。
关于数据技术人才定位的一些观点:
误解1:有些同学是找不到龙的屠龙者。通常在学术界做的非常成功的人,都会存在这样的一些问题,虽然掌握了很多算法模型技术,但是缺少对业务的深刻的理解和广阔的知识面。真实的项目中,其实是机器技术跟业务进行的一种深度的偶合,最后才创造出一些真正解决实际问题的效果非常好的模型,而这些模型往往不是只掌握这些技术本身就能够做出来的。
误解2:有些同学是黑盒工具论的鼓吹者。比如我掌握了一些业务问题,而市面上有很多开源的机器学习工具,我只需要把接口弄弄,然后套一套机器学习工具就实现了,这样做的效果往往是不好的,我们会发现,只有对模型有深入的理解,能够在很多细化的环节作出调整,才能形成一个比较好的解决问题的方法。
最后总结下,如果大家想成为一个数据技术人才的话:一方面,我们要对模型有一个白盒的、透彻的、深入的理解;另一方面,对业务应用有相对的理解和思考,两者结合才能产生一个良好结果。
▌总结与反思
到此,回顾下第一部分的四方面内容:
人类学习:归纳+演绎,个案学习->统计学习
我们能相信统计么?基于概率的信任
监督学习:预测 Y~X,训练+预测,统计学习
监督学习核心:假设空间+优化目标+寻解算法
更精细的刻画:释放了规律的可能
更智能的学习:规律学习不再依赖人类知识
为何要跨上大数据的战车?功与守
如何跨上这个战车?数据<->模型<->业务<->需求
▌附录:期待下一部分
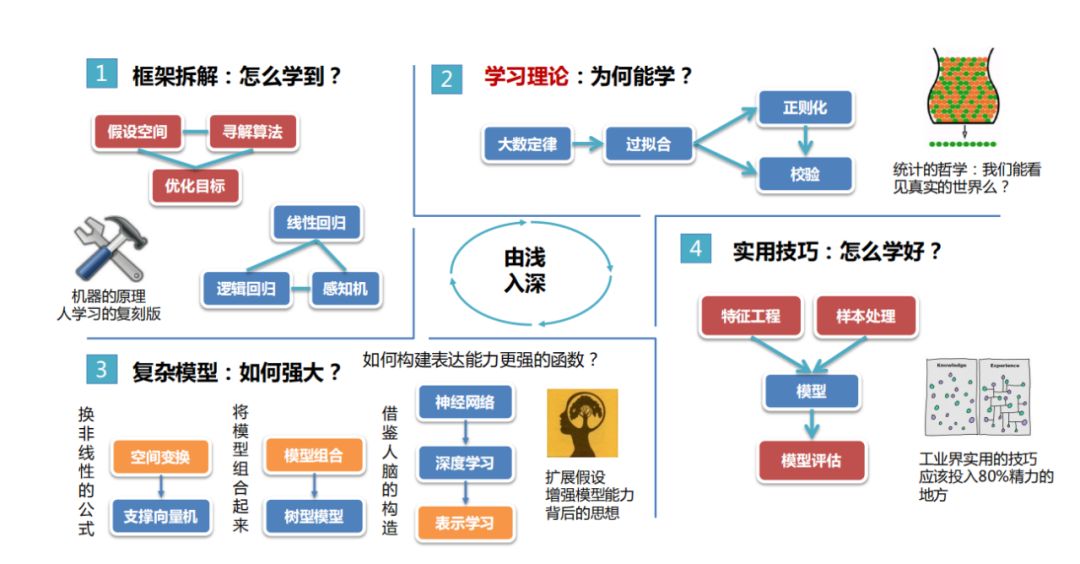
第二部分内容预告(由浅入深):
① 框架拆解:怎么学到?(线性回归、逻辑回归、感知机)
② 学习理论:为何能学?(大数定律->过拟合->正则化->校验)
③ 复杂模型:如何强大?(神经网络->深度学习->表示学习)
④ 使用技巧:怎么学好?(特征工程&样本处理->模型->模型评估)
------
今天的分享就到这里,欢迎关注 DataFun,下一期将分享:百度机器学习课程的第二部分内容。本课程配套视频已经上线,请搜索:百度技术学院官网,点击 AI 课程,即可查看,或者点击文末 [ 阅读原文 ] 收看。
——END——
DataFun:
专注于大数据、人工智能领域的知识分享平台。


- mbr修复、RAID组合方式与性能、文件系统自动挂载
- HBase方案 | 基于Lindorm的大数据用户画像解决方案
- 对话腾讯大数据团队:自研联邦学习系统的技术实践和难点
- 这套人工智能算法书已经出版了3卷,其中卷3深度学习和神经网络最受程序员喜欢
- 基于Hadoop的58同城离线计算平台设计与实践
- AI与人,“替代”还是 “共生”
- 考一个云计算技术认证,是应届生求职加分的利器!
- 一文看懂阿里文娱大数据 OLAP 选型
- 苏宁基于 ClickHouse 的大数据全链路监控实践
- 如何从软件工程师转型为AI工程师?
- 5个与保护数据隐私有关的AI关键问题
- 从理解到改进:非自回归翻译中的词汇选择 | 腾讯 AI 论文解读
- 「最有用」的特殊大数据:一文看懂文本信息系统的概念框架及功能
- 从游戏AI到自动驾驶,一文看懂强化学习的概念及应用
- AI公开课:03月26日未来十年 AI如何进化—圆桌探讨(乌镇智库理事长、CSDN 创始人&董事长、智源人工智能研究院副院长)之《AI:昨天 · 今天 · 明天》
- 解读人工智能、大数据和云计算的关系,大佬们赌AI竟都输了?
- 解读人工智能、大数据和云计算的关系,大佬们赌AI竟都输了?
- 谈论AI之前,你搞懂人类了吗?(颠覆认知)
- 人人都可以创造自己的AI:深度学习的6大应用及3大成熟领域
- 必知!4张图看尽AI发展史重大里程碑