数据结构与算法专题——第十二题 Trie树
2021-02-23 21:33
736 查看
今天来聊一聊Trie树,Trie树的名字有很多,比如字典树,前缀树等等。
一:概念
下面有and,as,at,cn,com这几个关键词,构建成 trie 树如下。
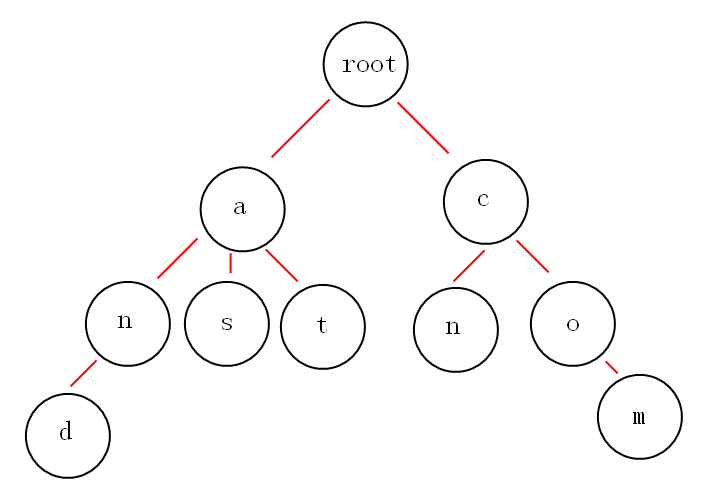
从上面图中,应该可以或多或少的发现一些好玩的特性。
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,就是该节点对应的字符串。
- 每个单词的公共前缀作为一个字符节点保存。
二:使用范围
既然学Trie树,肯定要知道这玩意是用来干嘛的?
1. 词频统计。
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么玩吗?这种限制级条件下就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
2. 前缀匹配
就拿上面的图来说吧,如果我想获取所有以 "a" 开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,用Trie树就不一样了,它可以做到h,h为你检索单词的长度,可以说这是秒杀的效果。
举个例子:现有一个编号为1的字符串”and“,怎样插入到trie树中呢?采用动态规划的思想,将编号”1“计入到每个途径的节点中,那么以后我们要找”a“,”an“,”and"为前缀的字符串的编号将会轻而易举。
三:实际操作
到现在为止,我想大家已经对trie树有了大概的掌握,下面看看如何来实现。
1:定义trie树节点
为了方便,我也采用纯英文字母,大家都知道字母有26个,所以构建的trie树就是一个26叉树,每个节点包含26个子节点,实现代码如下:
/// <summary>
/// Trie树节点
/// </summary>
public class TrieNode
{
/// <summary>
/// 26个字符,也就是26叉树
/// </summary>
public TrieNode[] childNodes;
/// <summary>
/// 词频统计
/// </summary>
public int freq;
/// <summary>
/// 记录该节点的字符
/// </summary>
public char nodeChar;
/// <summary>
/// 插入记录时的编码id
/// </summary>
public HashSet<int> hashSet = new HashSet<int>();
/// <summary>
/// 初始化
/// </summary>
public TrieNode()
{
childNodes = new TrieNode[26];
freq = 0;
}
}
2: 添加操作
既然是26叉树,那么当前节点的后续子节点是放在当前节点的哪一叉中,也就是放在childNodes中哪一个位置,这里采用
int k = word[0] - 'a'来计算位置。
/// <summary>
/// 插入操作
/// </summary>
/// <param name="root"></param>
/// <param name="s"></param>
public void AddTrieNode(ref TrieNode root, string word, int id)
{
if (word.Length == 0)
return;
//求字符地址,方便将该字符放入到26叉树中的哪一叉中
int k = word[0] - 'a';
//如果该叉树为空,则初始化
if (root.childNodes[k] == null)
{
root.childNodes[k] = new TrieNode();
//记录下字符
root.childNodes[k].nodeChar = word[0];
}
//该id途径的节点
root.childNodes[k].hashSet.Add(id);
var nextWord = word.Substring(1);
//说明是最后一个字符,统计该词出现的次数
if (nextWord.Length == 0)
root.childNodes[k].freq++;
AddTrieNode(ref root.childNodes[k], nextWord, id);
}
3:删除操作
删除操作中,不仅要删除该节点的字符串编号,还要对词频减一操作。
/// <summary>
/// 删除操作
/// </summary>
/// <param name="root"></param>
/// <param name="newWord"></param>
/// <param name="oldWord"></param>
/// <param name="id"></param>
public void DeleteTrieNode(ref TrieNode root, string word, int id)
{
if (word.Length == 0)
return;
//求字符地址,方便将该字符放入到26叉树种的哪一颗树中
int k = word[0] - 'a';
//如果该叉树为空,则说明没有找到要删除的点
if (root.childNodes[k] == null)
return;
var nextWord = word.Substring(1);
//如果是最后一个单词,则减去词频
if (word.Length == 0 && root.childNodes[k].freq > 0)
root.childNodes[k].freq--;
//删除途经节点
root.childNodes[k].hashSet.Remove(id);
DeleteTrieNode(ref root.childNodes[k], nextWord, id);
}
4:测试
这里我从网上下载了一套的词汇表,共2279条词汇,现在要做的就是检索 “go” 开头的词汇,并统计go出现的频率。
public static void Main()
{
Trie trie = new Trie();
var file = File.ReadAllLines(Environment.CurrentDirectory + "//1.txt");
foreach (var item in file)
{
var sp = item.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
trie.AddTrieNode(sp.LastOrDefault().ToLower(), Convert.ToInt32(sp[0]));
}
Stopwatch watch = Stopwatch.StartNew();
//检索go开头的字符串
var hashSet = trie.SearchTrie("go");
foreach (var item in hashSet)
{
Console.WriteLine("当前字符串的编号ID为:{0}", item);
}
watch.Stop();
Console.WriteLine("耗费时间:{0}", watch.ElapsedMilliseconds);
Console.WriteLine("\n\ngo 出现的次数为:{0}\n\n", trie.WordCount("go"));
}
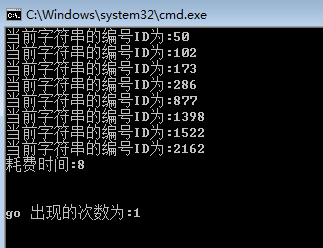
下面我们拿着ID到txt中去找一找,嘿嘿,是不是很有意思。


相关文章推荐
- acm 常用数据结构与算法专题(未分类均放于此)
- 数据结构与算法专题——第九题 外排序
- 数据结构和算法设计专题之---二分查找(Java版)
- 数据结构与算法专题——第三题 最长公共子序列
- 数据结构与算法专题之树——树与二叉树的定义与性质
- 数据结构与算法专题——第十题 输入法跳不过的坎-伸展树
- 数据结构(二)数据结构与基本算法
- 数据结构与算法学习之路:直接插入排序
- 数据结构与算法-图(图的储存方式2-邻接表)
- 算法、数据结构经典资料简介(TAOCP、Robert Sedgewick、算法导论、编程珠玑)
- 数据结构与算法---约瑟夫问题
- 数据结构之(图最短路径之)Dijkstra(迪杰斯特拉)算法
- 数据结构与算法8:图的深度优先搜索
- 数据结构笔记(2)——二叉树基本算法大全
- 数据结构之(图之最小生成树)Kruskal(克鲁斯卡尔)算法
- 数据结构与算法笔记 —— 向量
- 数据结构与算法----顺序查找法
- 数据结构——算法之(034)(编写一个函数求一个数组中的第二大数)
- 【数据结构与算法】桶排序
- 数据结构与算法13:折半查找、差值查找和斐波那契查找