[计算机视觉论文速递] 2018-03-18
通知:这篇推文有10篇论文速递信息,涉及人脸表情识别、人脸替换、3D人脸重建、Re-ID、目标检测和目标跟踪等方向
Note:最近一直有童鞋私聊问我,有没有相关的讨论群,于是今天我新建了CVer微信讨论群。愿意加入群聊的童鞋请下拉至文末,扫码进群,谢谢
往期回顾
[计算机视觉] 入门学习资料
[计算机视觉论文速递] 2018-03-16
[计算机视觉论文速递] 2018-03-14
人脸
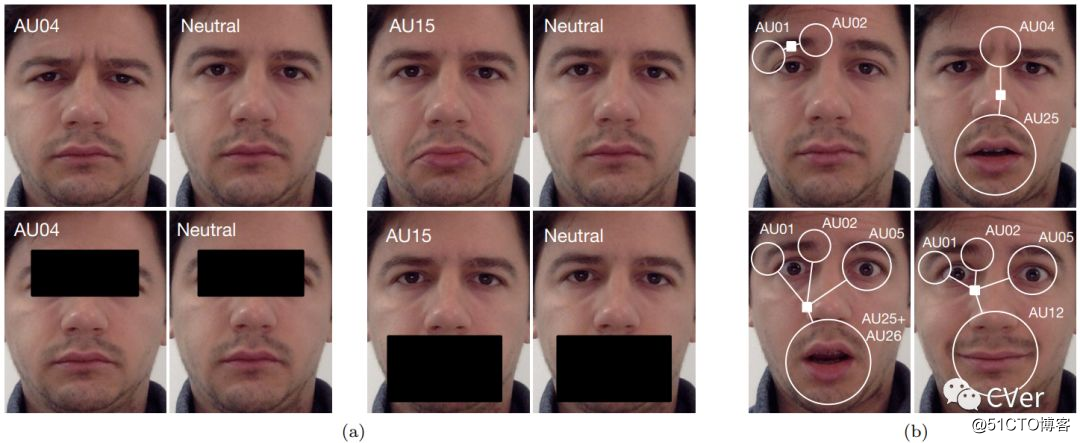
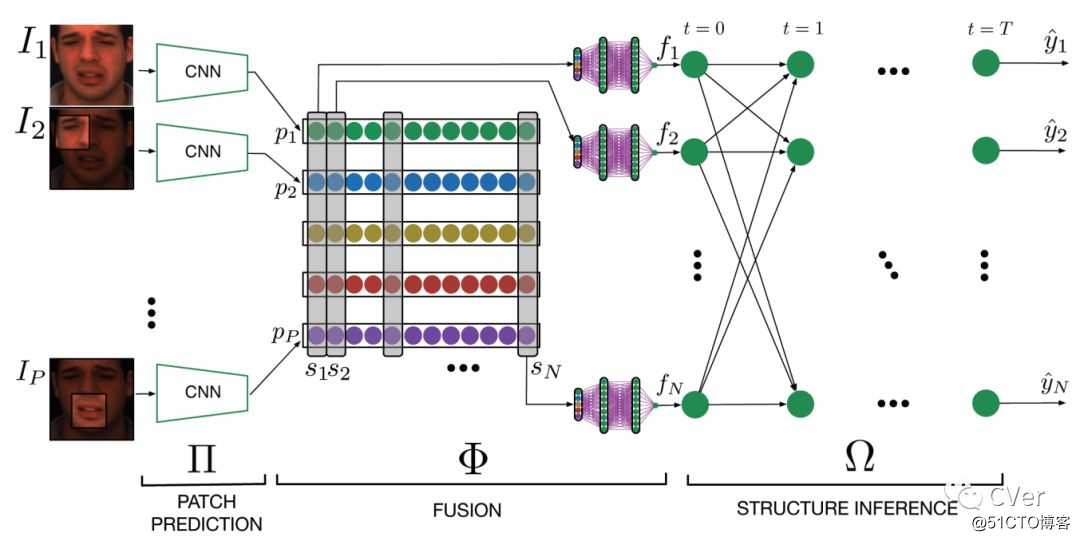
[1]《Deep Structure Inference Network for Facial Action Unit Recognition》
Abstract:面部表情是称为行动单位(AU)的基本组件的组合。 识别AU是开发常规面部表情分析的关键。 近年来,自动AU识别中的大部分努力致力于学习局部特征的组合,并利用动作单元之间的相关性。 在本文中,我们提出了一种深度神经网络架构,通过在初始阶段结合学习的局部和全局特征来解决这两个问题,并在类之间复制类似于后面阶段的图形模型推理方法的消息传递算法。 我们证明,通过增加监督来端对端地训练模型,我们分别提高了BP4D和DISFA数据集的5.3%和8.2%的性能水平。
arXiv:https://arxiv.org/abs/1803.05873

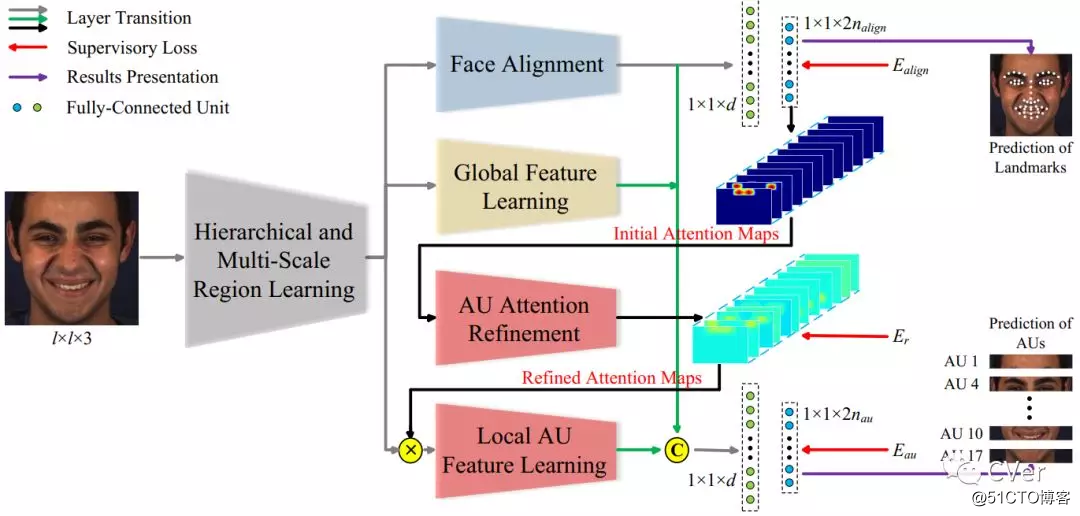
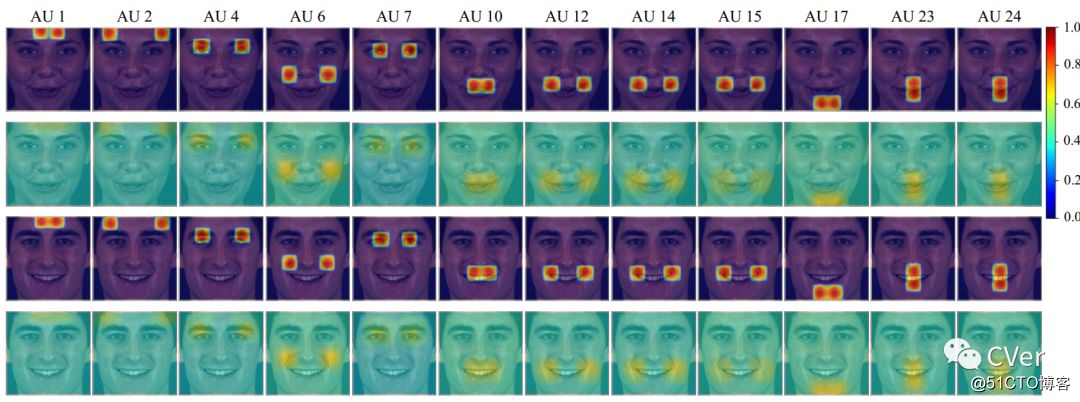
[2]《Deep Adaptive Attention for Joint Facial Action Unit Detection and Face Alignment》
Abstract:面部动作单元(AU)检测和面部对齐是两个高度相关的任务,因为面部标志可以提供精确的AU位置,以便于为AU检测提取有意义的局部特征。大多数现有的AU检测工作经常将面对齐作为预处理并独立处理这两个任务。在本文中,我们提出了一种新颖的端到端深度学习框架,用于联合AU检测和人脸对齐,这在以前没有探讨过。特别是首先学习多尺度共享特征,并将高层次的人脸对齐特征引入AU检测。此外,为了提取精确的局部特征,我们提出了一种自适应注意力学习模块,以自适应地优化每个AU的注意力图。最后,组合的局部特征与面部对齐特征和用于AU检测的全局特征集成。对BP4D和DISFA基准的实验表明,我们的框架明显优于AU检测的最先进方法。
arXiv:https://arxiv.org/abs/1803.05588
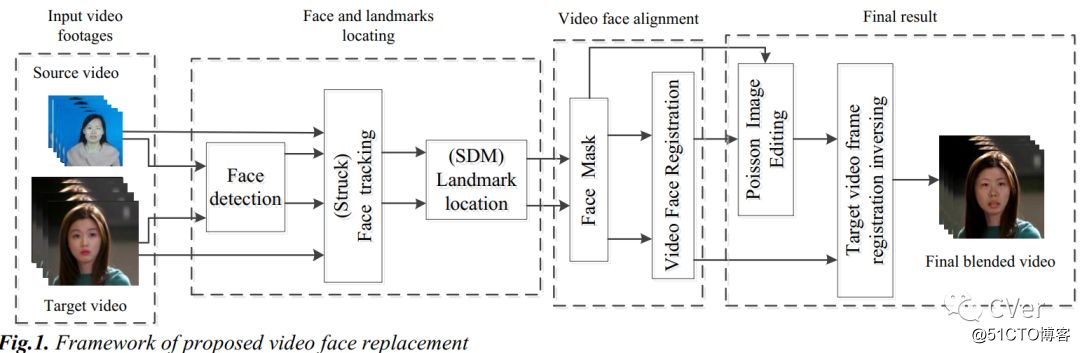
[3]《Image Registration Based Flicker Solving in Video Face Replacement and Analysis Based Sub-pixel Image Registration》
ICIS 2017
Abstract:本文提出了一种视频人脸替换的框架,它处理视频序列中交换人脸的闪烁。该框架包含两个主要创新:1)利用图像配准技术来调整源视频和目标视频面以消除分段视频脸部序列的闪烁或抖动; 2)提出了一种快速亚像素图像配准方法,以获得更高的精度和效率。与先验作品不同,它将重叠区域最小化,并将时空连贯性考虑在内。导致视频闪烁通常是由混合目标人脸频繁变化的边界以及视频序列之间和之后的未注册人脸造成的。提出了亚像素图像配准方法来解决闪烁问题。在对齐过程中,通过最大化图像的相似性和下采样策略来加速整个过程,并且通过分析方法进行的子像素图像配准是单步图像匹配,从而制定整数像素配准。实验结果表明,该算法在不同数据集上进行实验时,减少了计算时间,获得了很高的精度。
注:视频人脸替换,很有意思!!!
arXiv:https://arxiv.org/abs/1803.05851
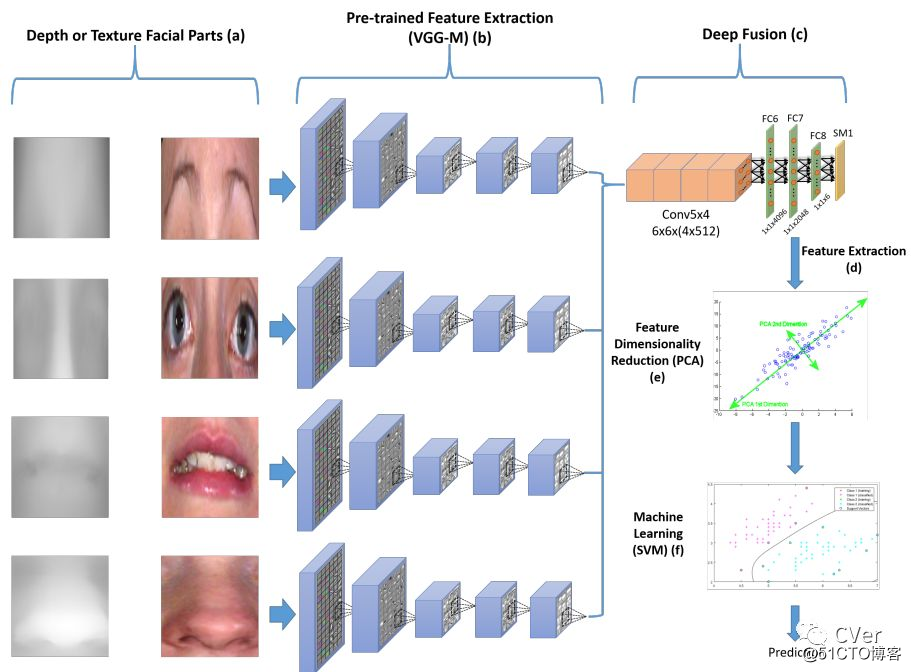
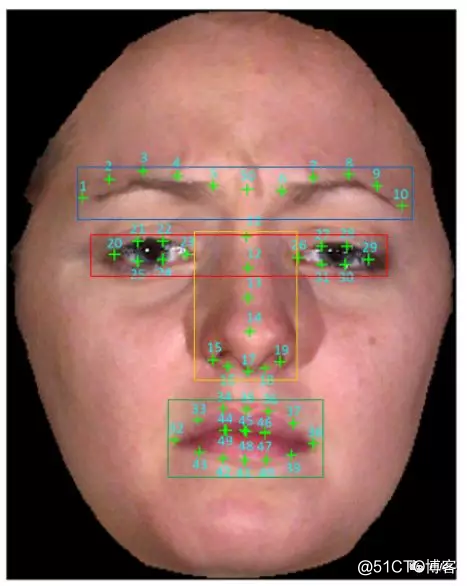
[4]《Accurate Facial Parts Localization and Deep Learning for 3D Facial Expression Recognition》
Abstract:有意义的脸部可以传达面部动作单元检测和表情预测的关键线索。纹理化的3D人脸扫描可以提供详细的3D几何形状和面部表情识别(FER)有益的人脸2D纹理外观提示。然而,准确的脸部提取以及它们的融合是具有挑战性的任务。本文提出了一种基于精确脸部提取和脸部深部特征融合的全新三维FER系统。具体而言,每个纹理化的3D人脸扫描首先被表示为具有一对一密集对应关系的2D纹理图和深度图。然后,使用由面部标志点定位,面部旋转修正,面部尺寸调整,脸部部分包围盒提取和后处理程序组成的新的4阶段过程来提取纹理图和深度图的面部部分。最后,分别从纹理贴图和深度贴图中学习所有面部的深度融合卷积神经网络(CNNs)特征,并将非线性支持向量机用于表达预测。在BU-3DFE数据库上进行实验,证明梳理不同面部部分,纹理和深度线索的有效性,并与相同设置下的所有现有方法进行比较,报告最先进的结果。
arXiv:https://arxiv.org/abs/1803.05846
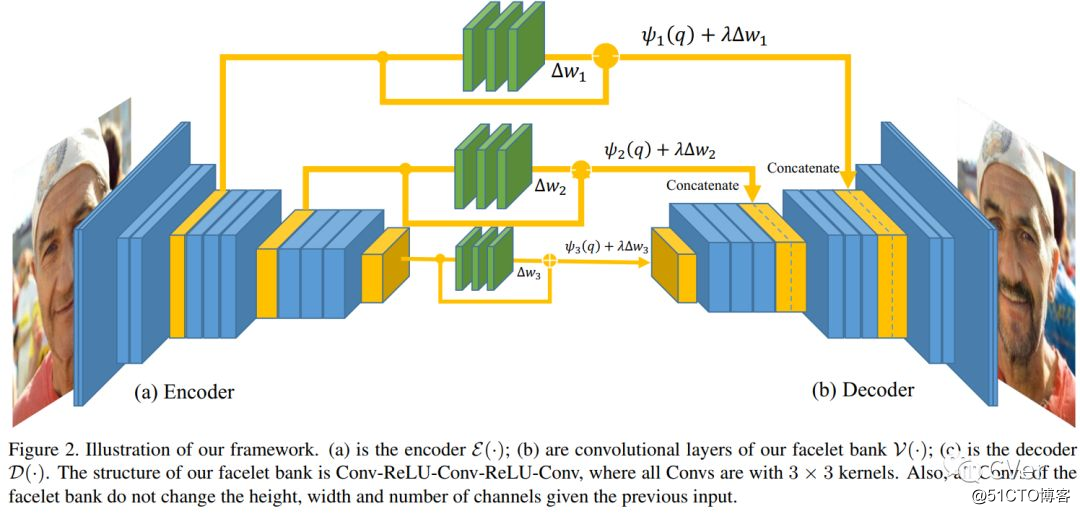
[5]《Facelet-Bank for Fast Portrait Manipulation》
Accepted by CVPR 2018
Abstract:由于智能手机和社交网络的普及,数字脸部操纵已成为触摸图像的流行和迷人方式。 随着各种各样的用户喜好,面部表情和配件,一个通用和灵活的模型是必要的,以适应不同类型的面部编辑。 在本文中,我们提出了基于支持快速推理,编辑效果控制和快速部分模型更新的端到端卷积神经网络的模型。 另外,该模型从具有不同属性的不成对图像集中学习。 实验结果表明,我们的框架可以处理各种各样的脸部表情,配件和化妆效果,以高速生成高分辨率和高质量的效果。
arXiv:https://arxiv.org/abs/1803.05576

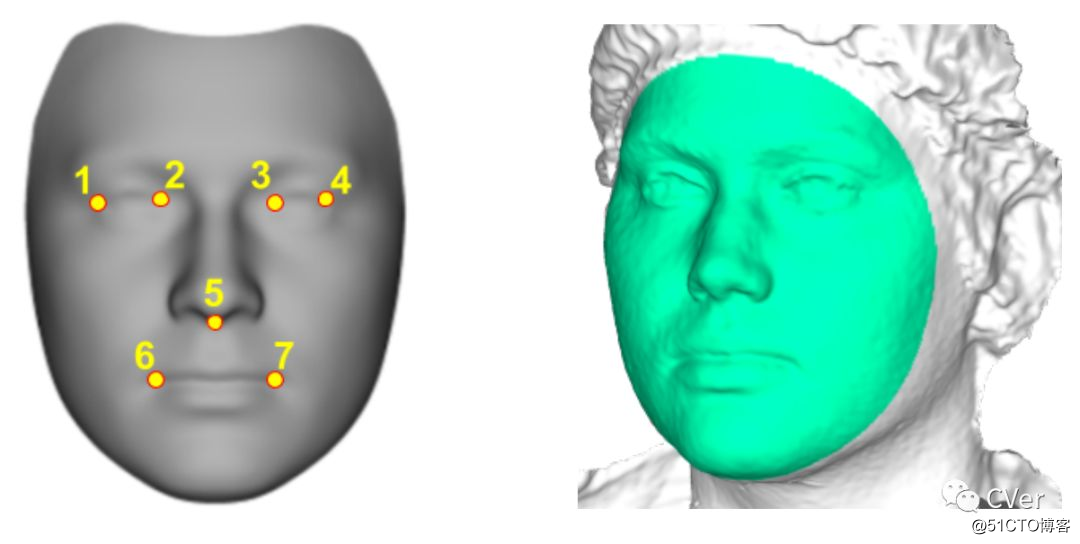
[6]《Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild》
Abstract:本文研究了单个2D图像的密集三维人脸重建评估。 为此,我们组织了一次比赛,提供了一个新的基准数据集,其中包含了2000个2D科目的2D面部图像以及他们的3D地面真相人脸扫描。 与之前的竞赛或挑战相比,这种新的基准数据集的目标是使用真实,准确和高分辨率的3D ground-truth人脸扫描来评估3D稠密人脸重建算法的准确性。 除了数据集之外,我们还提供标准协议以及用于评估的Python脚本。 最后,我们报告了三个最先进的三维人脸重建系统在新基准数据集上的结果。 本次比赛是与2018年第13届IEEE自动人脸识别和手势会议一起举办的。
arXiv:https://arxiv.org/abs/1803.05536
github:https://github.com/patrikhuber/fg2018-competition

Re-ID
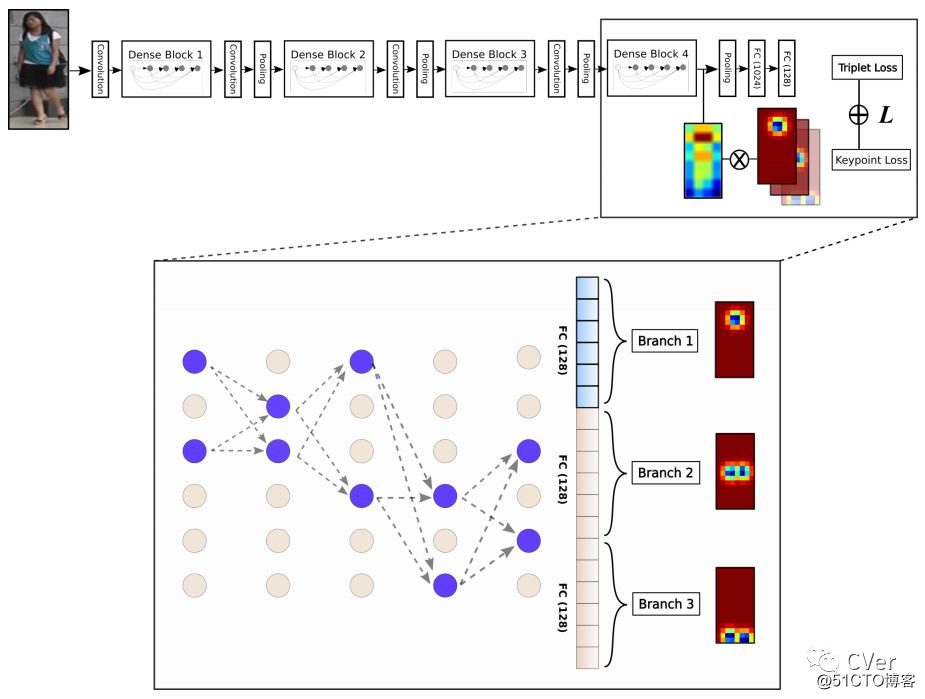
[7]《Virtual CNN Branching: Efficient Feature Ensemble for Person Re-Identification》
Abstract:在本文中,我们介绍一种卷积神经网络(CNN)的集合方法,称为“虚拟分支”,它可以在几乎没有附加参数的情况下实施,并且可以在标准CNN的基础上进行计算。 我们在行人重识别的任务下提出我们的方法。 我们的CNN模型由共享底层组成,其次是“虚拟”分支,来自常规卷积层和完全连接层的神经元被划分为多个集合。 每个虚拟分支用不同的数据进行训练以专注于不同的方面,例如特定的身体区域或姿势取向。 通过这种方式,可以在几乎没有任何额外成本的情况下获得鲁棒的集成表示,以抵抗人体错位,变形或视角变化。 所提出的方法在多人再识别基准数据集上实现了竞争性表现,包括Market-1501,CUHK03和DukeMMC-reID。
arXiv:https://arxiv.org/abs/1803.05872

目标检测
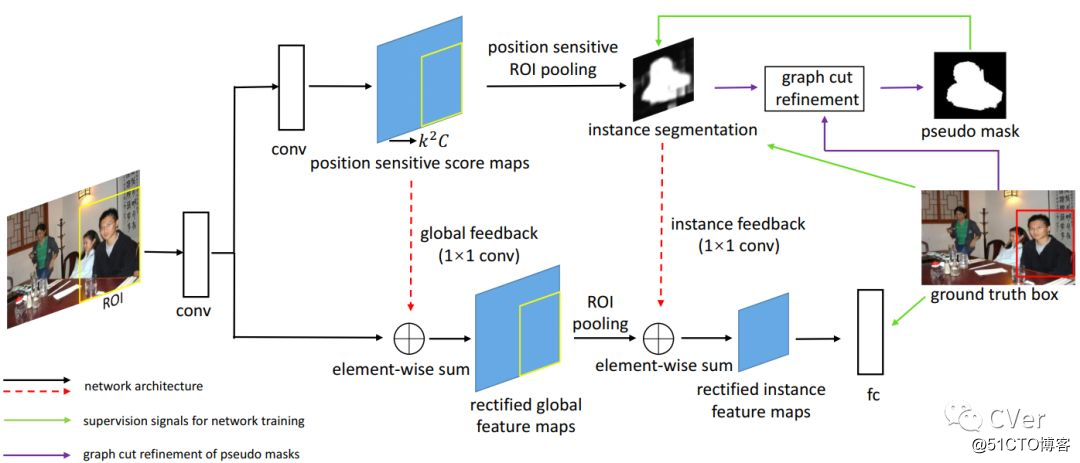
[8]《Pseudo Mask Augmented Object Detection》
Abstract:在这项工作中,我们提出了一个新颖而有效的框架,以利用仅由边框注解监督的实例级分割信息来促进对象检测。从联合对象检测和实例分割网络开始,我们提出从实例级对象分割网络训练中递归地估计pseudo ground-truth对象掩码,然后利用自顶向下分割反馈增强检测网络。pseudo ground-truth掩模和网络参数被优化以替代彼此互惠。为了在每次迭代中获得有较好的伪掩码,我们嵌入了包含低级图像外观一致性和边界框注释的图形推断,以细化由分割网络预测的分割掩模。我们的方法通过结合从弱监督分割网络学习的详细的逐像素信息来逐步提高对象检测性能。对PASCAL VOC 2007和2012 [12]中的检测任务的广泛评估证实了所提出的方法是有效的。
arXiv:https://arxiv.org/abs/1803.05858

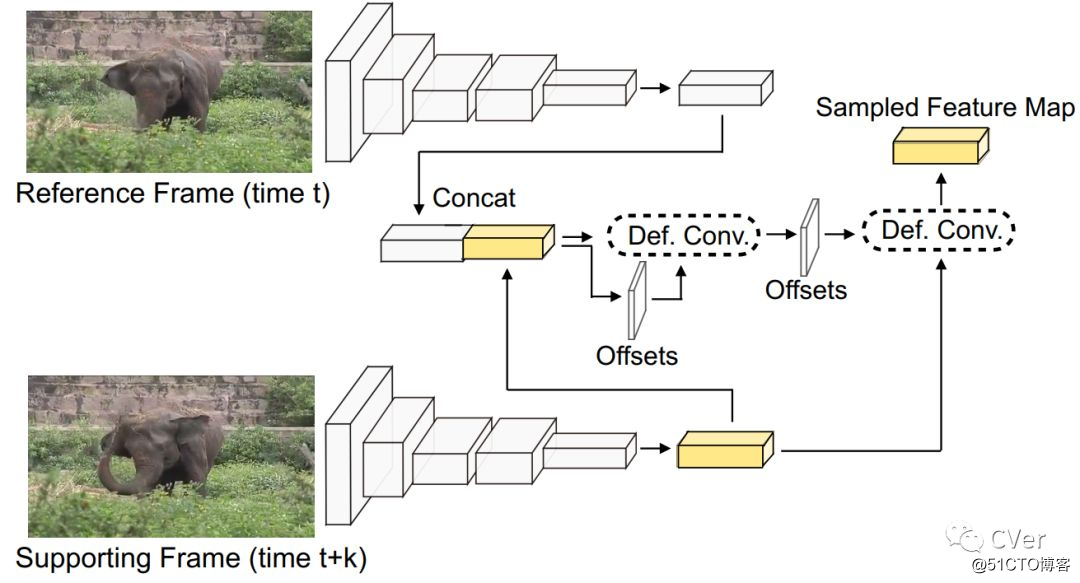
[9]《Object Detection in Video with Spatiotemporal Sampling Networks》
Abstract:我们提出了一种时空采样网络(STSN),它使用跨时间变形卷积来进行视频中的物体检测。 我们的STSN通过学习从相邻帧的空间采样特征来在视频帧中执行对象检测。 这自然使得该方法对于单个帧中的遮挡或运动模糊是鲁棒的。 我们的框架不需要额外的监督,因为它直接针对物体检测性能优化采样位置。 我们的STSN性能优于ImageNet VID数据集的最新技术水平,与之前的视频对象检测方法相比,它采用更简单的设计,并且不需要光流数据进行培训。 我们还表明,在对视频进行STSN训练之后,我们可以通过在静止图像数据上添加和训练单个可变形的卷积层来适应图像中的对象检测。 与传统的图像中的物体检测相比,这可以提高精确度。
arXiv:https://arxiv.org/abs/1803.05549


目标跟踪
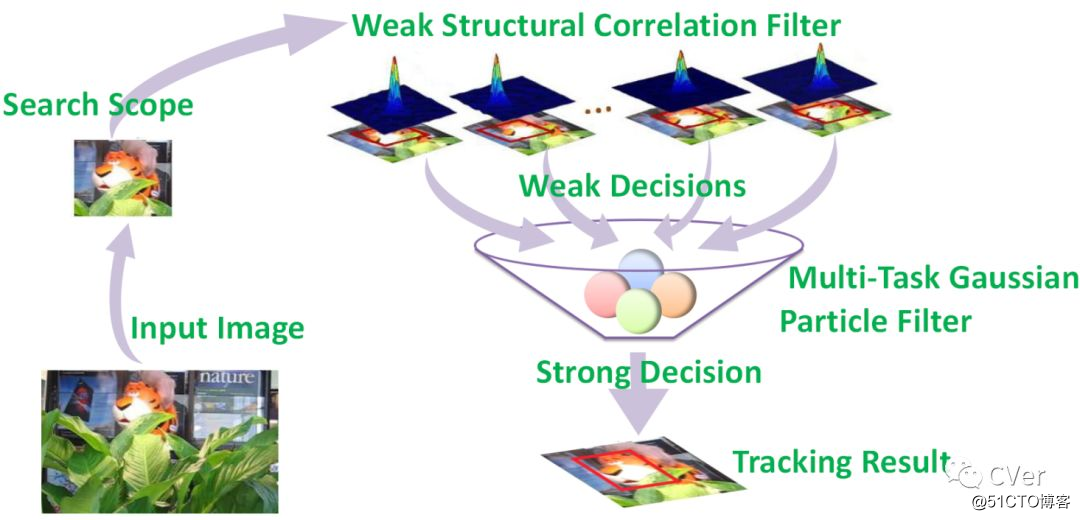
[10]《A Structural Correlation Filter Combined with A Multi-task Gaussian Particle Filter for Visual Tracking》
Abstract:在本文中,我们提出了一种新颖的结构相关滤波器与多任务高斯粒子滤波器(KCF-GPF)模型相结合的鲁棒视觉跟踪。我们首先提出一种组装结构,其中几个KCF跟踪器作为弱专家为高斯粒子滤波器提供初步决策,以作出最终决定。所提出的方法旨在利用和补充KCF和高斯粒子滤波器的强度。与基于相关滤波器或粒子滤波器的现有跟踪方法相比,所提出的跟踪器具有多个优点。首先,它可以通过弱KCF跟踪器检测大规模搜索范围内的跟踪目标,并评估高斯粒子滤波器的弱跟踪器\ rq决策的可靠性,从而做出强有力的决策,因此它可以解决快速运动,外观变化,遮挡和重新检测。其次,它可以通过高斯粒子滤波器有效处理大范围的变化。第三,可以采用重采样的方式完全并行实现而不需重采样,因此便于VLSI的实施,并且可以降低计算成本。在包含50个具有挑战性的序列的OTB-2013数据集上进行的大量实验证明,所提出的算法对16个最先进的跟踪器
arXiv:https://arxiv.org/abs/1803.05845



- [计算机视觉论文速递] 2018-05-16
- [计算机视觉论文速递] 2018-05-19
- [计算机视觉论文速递] 2018-03-20
- [计算机视觉论文速递] 2018-03-30
- [计算机视觉论文速递] 2018-03-31
- 2019计算机视觉论文精选速递(2019/1/23-2018/1/28)
- [计算机视觉论文速递] 2018-04-03
- [计算机视觉论文速递] 2018-04-17
- [计算机视觉论文速递] 2018-04-19
- [计算机视觉论文速递] 2018-04-23
- [计算机视觉论文速递] 2018-04-28
- [计算机视觉论文速递] 2018-05-08
- [计算机视觉论文速递] 2018-05-10
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- 计算机视觉领域经典论文源码大全
- 图像处理和计算机视觉中的经典论文
- 为什么不去读顶级会议上的论文?适应于机器学习、计算机视觉和人工智能
- [ZZ]计算机视觉、机器学习相关领域论文和源代码大集合
- 可下载计算机视觉顶级论文的网址
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新