[计算机视觉论文速递] 2018-04-28
通知:这篇文章有6篇论文速递信息,涉及视觉跟踪、Zero-shot Learning、GAN和人员计数等方向(含2篇CVPR论文)
[1]《View Extrapolation of Human Body from a Single Image》
CVPR 2018
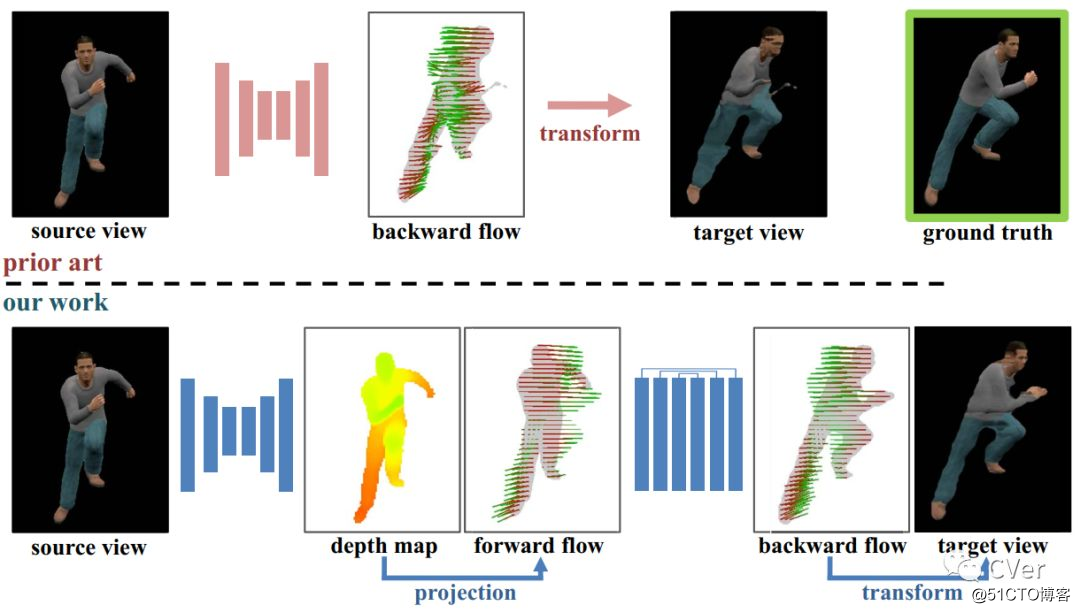
Abstract:我们研究如何从单个图像合成人体的新视图。尽管最近基于深度学习的方法对于刚性物体很适用,但它们通常在大型关节的物体(如人体)上失败。现有方法的核心步骤是将可观察的视图与CNN的新视图相匹配;然而,人体丰富的发音模式使得CNN很难记忆和插入数据。为了解决这个问题,我们提出了一种新的基于深度学习的pipeline,明确地估计和利用underlying人体的几何形状。我们的pipeline是一个形状估计网络和一个图像生成网络的组合,并且在接口处应用透视变换来生成像素值传输的正向流。我们的设计能够将数据变化的空间分解出来,并使每一步的学习变得更容易。经验上,我们表明姿态变化对象的性能可以大大提高。我们的方法也可应用于3D传感器捕获的实际数据,并且我们的方法生成的流可用于生成高分辨率的高质量结果。
arXiv:https://arxiv.org/abs/1804.04213
视觉跟踪
[2]《VITAL: Visual Tracking via Adversarial Learning》
CVPR 2018
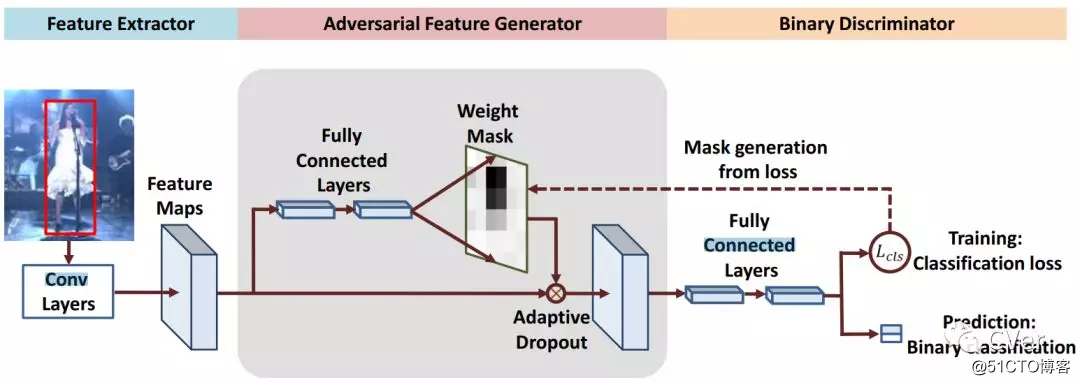
Abstract:Tracking-by-detection框架由两个阶段组成,即在第一阶段在目标对象周围drawing样本,并在第二阶段将每个样本分类为目标对象或将其分类为背景。使用深度分类网络的现有跟踪器的性能受到两方面的限制。首先,每帧中的正样本在空间上是高度重叠的,它们不能捕捉到丰富的外观变化。其次,正面和负面样本之间存在极端的class失衡。本文介绍了通过对抗学习(adversarial learning)解决这两个问题的VITAL算法。为了增加正样本,我们使用生成网络随机生成掩模,将其应用于自适应丢失输入特征以捕捉各种外观变化。通过使用对抗学习(adversarial learning),我们的网络可以识别在长时间跨度上保持目标对象最稳健特征的mask。另外,为了处理类别失衡的问题,我们提出了一个高阶的代价(cost)敏感性损失来减少简单负样本的影响,以便于训练分类网络。在基准数据集上的大量实验表明,所提出的跟踪器是state-of-the-art。
arXiv:https://arxiv.org/abs/1804.04273
注:还有对抗学习(adversarial learning),简直太秀了
Zero-shot
[3]《A Large-scale Attribute Dataset for Zero-shot Learning》
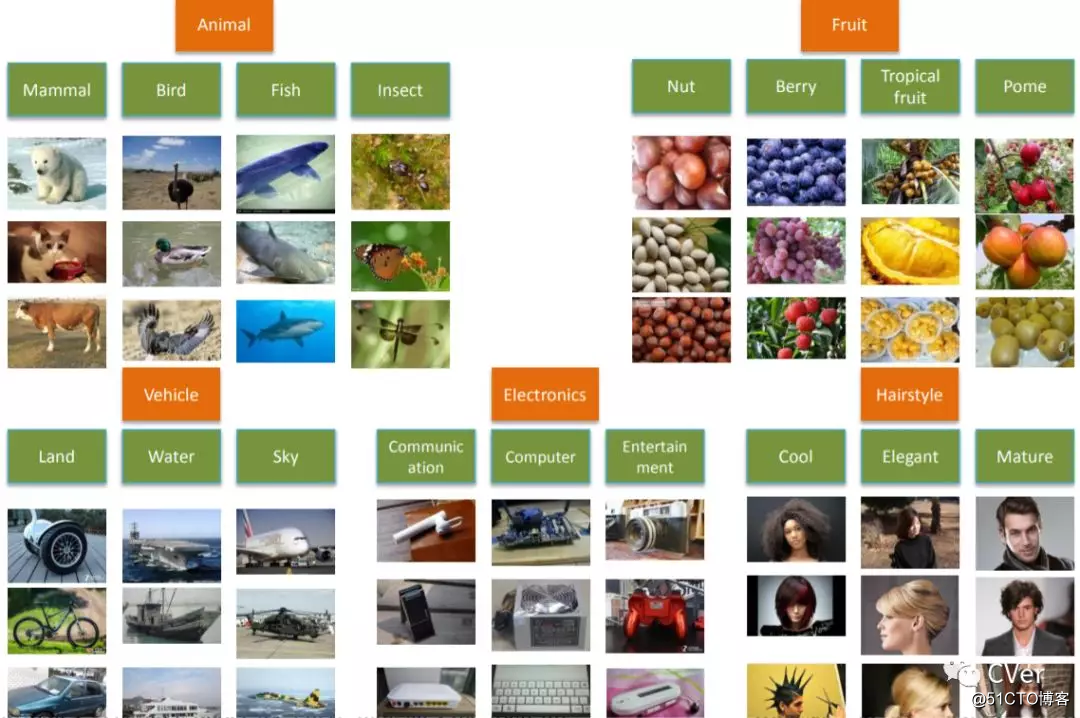
Abstract:Zero-Shot Learning (ZSL) has attracted huge research attention over the past few years; it aims to learn the new concepts that have never been seen before. In classical ZSL algorithms, attributes are introduced as the intermediate semantic representation to realize the knowledge transfer from seen classes to unseen classes. Previous ZSL algorithms are tested on several benchmark datasets annotated with attributes. However, these datasets are defective in terms of the image distribution and attribute diversity. In addition, we argue that the "co-occurrence bias problem" of existing datasets, which is caused by the biased co-occurrence of objects, significantly hinders models from correctly learning the concept. To overcome these problems, we propose a Large-scale Attribute Dataset (LAD). Our dataset has 78,017 images of 5 super-classes, 230 classes. The image number of LAD is larger than the sum of the four most popular attribute datasets. 359 attributes of visual, semantic and subjective properties are defined and annotated in instance-level. We analyze our dataset by conducting both supervised learning and zero-shot learning tasks. Seven state-of-the-art ZSL algorithms are tested on this new dataset. The experimental results reveal the challenge of implementing zero-shot learning on our dataset.
arXiv:https://arxiv.org/abs/1804.04314
注:这里搬原文很舒服,里面英文单词看着容易理解(绝不是俺偷懒)
Home Actions数据集
[4]《STAIR Actions: A Video Dataset of Everyday Home Actions》

Abstact:介绍一种新的用于人类行为识别的大型视频数据集,称为STAIR Actions。 STAIR行动包含100个类别的行为标签,代表细致的日常家庭行为,因此它可以应用于各种家庭任务的研究,如护理,关怀和安全。 在STAIR操作中,每个视频都有一个动作标签。 此外,对于每个行动类别,大约有1,000个视频是从YouTube获得的或由众包工作者制作的。 每个视频的持续时间大多是五到六秒。 视频总数为102,462。 我们解释了我们如何构建STAIR操作并显示STAIR操作与现有数据集进行人类操作识别相比较的特点。 三种主要动作识别模型的实验表明,STAIR Actions可以训练大型模型并获得良好的性能。
arXiv:https://arxiv.org/abs/1804.04326
datasets:https://actions.stair.center/
注:NB且新奇的数据集
GAN
[5]《MelanoGANs: High Resolution Skin Lesion Synthesis with GANs》
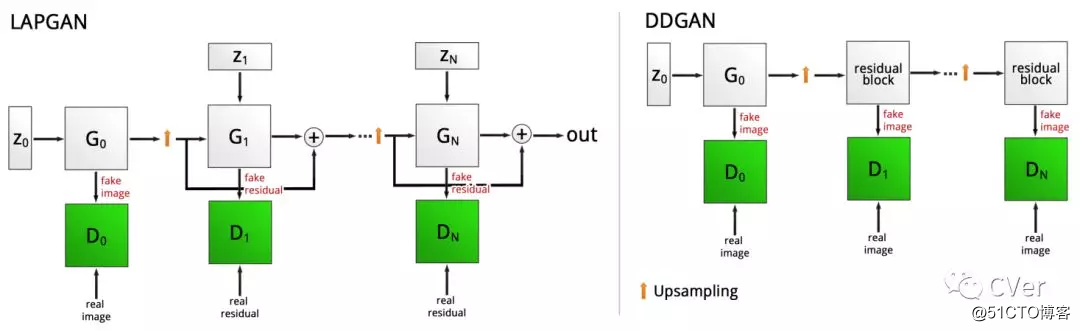
Abstract:生成对抗网络(GANs)已成功用于合成逼真的人脸图像,风景甚至医学图像。不幸的是,它们通常需要大量的训练数据集,而这些数据集在医学领域通常很少见,而且据我们所知,GAN仅以相当低的分辨率应用于医学图像合成。然而,许多最先进的机器学习模型都使用高分辨率数据,因为这些数据具有不可或缺的重要信息。在这项工作中,我们尝试使用GANs生成逼真的高分辨率皮肤损伤图像,仅使用2000个样本的小型训练数据集。数据的性质使我们可以直接比较生成的样本和真实数据集的图像统计数据。我们在数量和质量上比较了DCGAN和LAPGAN等最先进的GAN体系结构,并对后者进行了256x256px分辨率图像生成任务的修改。我们的调查显示,我们可以用所有模型逼近真实的数据分布,但是在视觉上评估样本真实性,多样性和工件时,我们注意到主要差异。在一组关于皮肤损伤分类的用例实验中,我们进一步表明,我们可以借助合成的高分辨率黑素瘤样本成功解决严重的类失衡问题。
arXiv:https://arxiv.org/abs/1804.04338
人员计数
[6]《Benchmark data and method for real-time people counting in cluttered scenes using depth sensors》
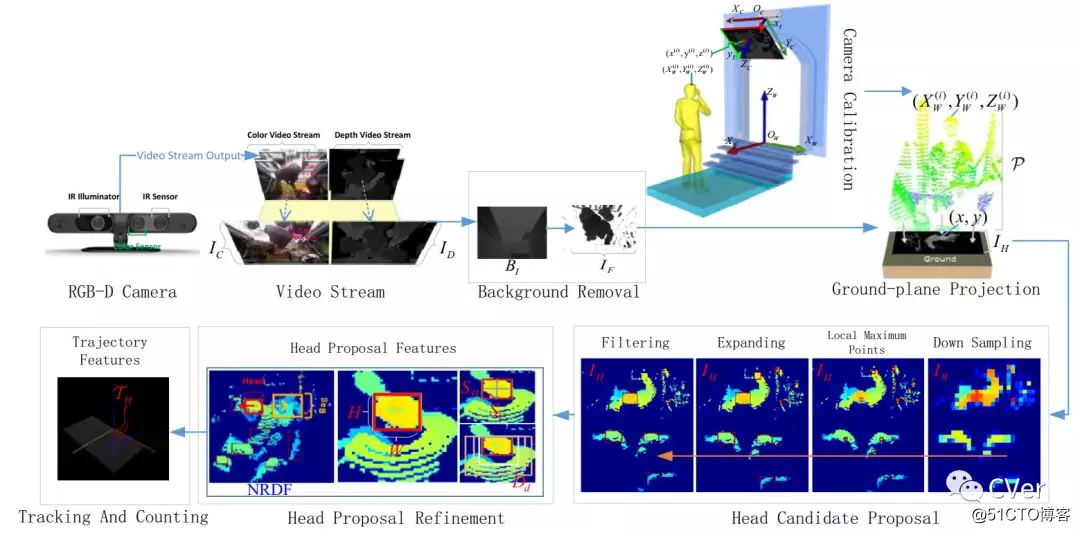
Abstract:实时自动统计人员在安全,安全和物流方面有着广泛的应用。然而,目前还没有针对这个问题的基准方法的大规模公共数据集。为填补这一空白,我们推出了第一个真实世界的RGB-D人数统计数据集(PCDS),其中包含正常和混乱条件下在公交车入口处录制的4,500多个视频。我们还提出了一种有效的方法,可以单独使用深度视频来计算真实世界混乱场景中的人物。所提出的方法从深度视频帧计算点云,并将其重新投影到地平面上以对深度信息进行归一化。分析得到的深度图像以识别潜在的人头。使用3D人体模型对人体头部提议进行了精心设计。跟踪连续视频流的每个帧中的提议以追踪它们的轨迹。轨迹再次被改进以确定可靠的计数。人们最终通过累积离开现场的头部轨迹来计数。为了实现有效的头部和轨迹识别,我们还提出了两种不同的复合特征。对PCDS进行全面评估表明,我们的整体技术能够在1.7 GHz处理器上以45 fps的高精度对凌乱场景中的人员进行计数。

- [计算机视觉论文速递] 2018-05-08
- [计算机视觉论文速递] 2018-05-10
- 2019计算机视觉论文精选速递(2019/1/23-2018/1/28)
- [计算机视觉论文速递] 2018-05-16
- [计算机视觉论文速递] 2018-05-19
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- 计算机视觉领域经典论文源码大全
- 图像处理和计算机视觉中的经典论文
- 为什么不去读顶级会议上的论文?适应于机器学习、计算机视觉和人工智能
- [ZZ]计算机视觉、机器学习相关领域论文和源代码大集合
- 可下载计算机视觉顶级论文的网址
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- 计算机视觉、机器学习相关领域论文和源代码大集合
- 计算机视觉会议论文入口Computer Vision Foundation open access
- 图像处理与计算机视觉基础相关领域的经典书籍以及论文
- 计算机视觉、机器学习相关领域论文和源代码
- 计算机视觉、机器学习相关领域论文和源代码大集合【转载】
- 21世纪初最有影响力的20篇计算机视觉期刊论文
- 超越ImageNet?李飞飞力赞高徒的视频描述研究入选计算机视觉最前沿的十大论文
- 计算机视觉、机器学习相关领域论文和源代码大集合