[计算机视觉论文速递] 2018-05-16
导言
这篇文章有4篇论文速递信息,涉及单目图像深度估计、6-DoF跟踪、图像合成和动作捕捉等方向(含1篇CVPR 2018论文和1篇ICRA 2018论文)。
CVer
编辑: Amusi
校稿: Amusi
题外话(重磅福利)
关注CVer的童鞋应该都知道,CVer平台的特点是论文速递,旨在整理与计算机视觉/深度学习/机器学习方向相关的最新论文。近期有童鞋反映,看了论文,脑中存在点印象,需要去CVer公众号上再翻阅再查找,有时候还会找不到。包括Amusi自己在内,也经常遇到这类问题(自己整理,自己都会忘记出处)。
为了解决这个问题,Amusi想到了实(zhuang)用(bi) 神器GitHub,所以Amusi将日常整理的论文都会同步发布到 daily-paper-computer-vision 上。名字有点露骨,还请见谅。喜欢的童鞋,欢迎star、fork和pull。直接点击“阅读全文”即可访问daily-paper-computer-vision。
link: https://github.com/amusi/daily-paper-computer-vision
Depth Estimation
2018 arXiv
《Dual CNN Models for Unsupervised Monocular Depth Estimation》
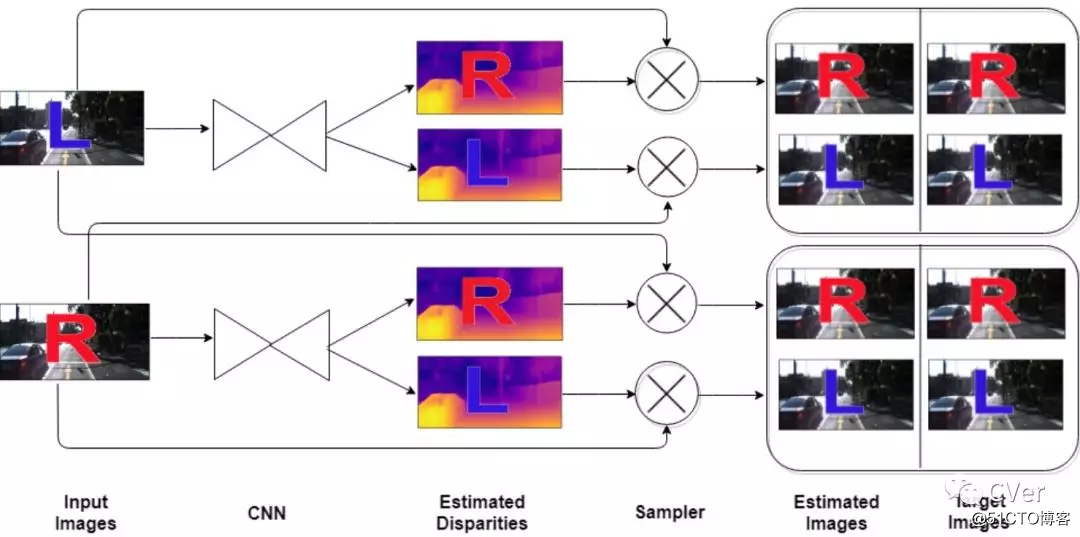

Abstract:立体视觉中的深度估计问题已经取得了很多进展。虽然通过利用监督深度学习的深度估计来观察到非常令人满意的表现。这种方法需要大量的标定好的真实数据(ground truth)以及深度图,这些图准备非常费时费力,并且很多时候在实际情况下不可用。因此,无监督深度估计是利用双目立体图像摆脱深度图ground truth的最新方法。在无监督深度计算中,通过基于极线几何约束(epipolar geometry constraints)以图像重构损失对CNN进行训练来生成视差图像。需要解决使用CNN的有效方法以及调查该问题的更好的损失(loss)。在本文中,提出了一种基于双重(dual)CNN的模型,用于无监督深度估计,每个视图具有6个损失(DNM6)和单个CNN,以生成相应的视差图。所提出的双CNN模型也通过利用交叉差异扩大了12个损失(DNM12)。所提出的DNM6和DNM12模型在KITTI驾驶和Cityscapes城市数据库上进行了试验,并与最近最先进的无监督深度估计结果进行了比较。
arXiv:https://arxiv.org/abs/1804.06324
github:
注:无监督学习,厉害了!
6-DoF Tracking
2018 arXiv
《Egocentric 6-DoF Tracking of Small Handheld Objects》
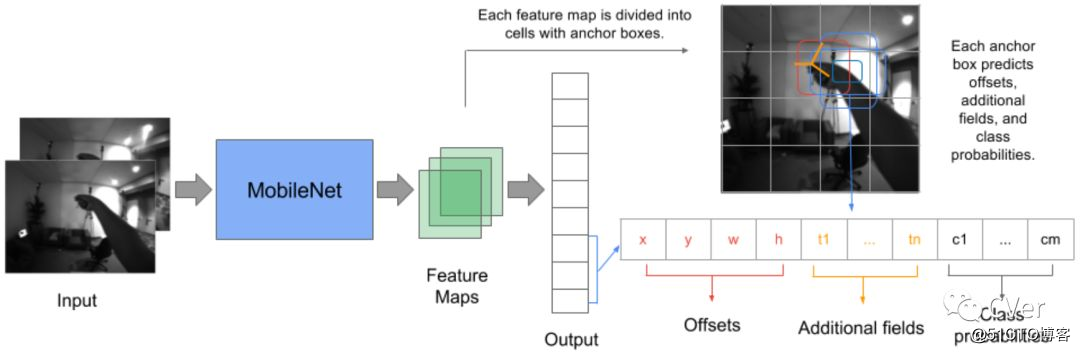

Abstract:虚拟和增强现实技术在过去几年中有了显著性增长。这种系统的关键部分是能够在3D空间中跟踪头戴式显示器和控制器的姿态。我们从自我中心相机(egocentric camera perspectives)的角度解决了手持式控制器高效的6-DoF跟踪问题。我们收集了HMD控制器数据集,该数据集由超过540,000个立体图像对组成,标记有手持控制器的完整6-DoF姿态 我们提出的SSD-AF-Stereo3D模型在3D关键点预测中实现33.5毫米的平均平均误差,并与控制器上的IMU传感器结合使用,以实现6-DoF跟踪。我们还介绍了基于模型的完整6-DoF跟踪方法的结果。 我们的所有型号都受到实时移动CPU inference的严格限制。
arXiv:https://arxiv.org/abs/1804.05870
Image Synthesis
《Geometry-aware Deep Network for Single-Image Novel View Synthesis》
CVPR 2018
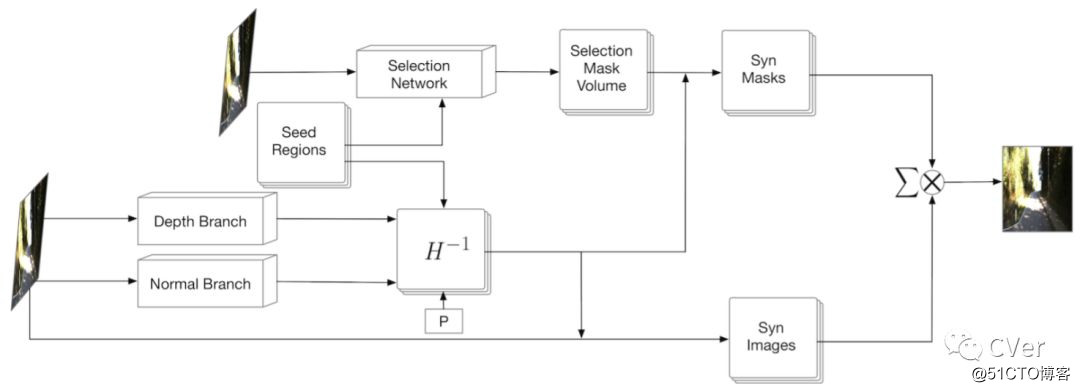

Abstract:本文从单个图像解决了新颖视图合成的问题。特别是,我们针对的是具有丰富几何结构的真实场景,这是一个具有挑战性的任务,因为这些场景的外观变化很大,并且缺乏简单的3D模型来表示它们。现代的,基于学习的方法主要集中于外观来合成新颖的视图,因此倾向于产生与底层场景结构不一致的预测。相反,在本文中,我们建议利用场景的三维几何来合成一种新颖的视图。具体而言,我们通过固定数量的平面逼近真实世界的场景,并学习预测一组单应性(homographies)及其相应的区域蒙版/掩膜(masks),以将输入图像转换为新颖视图。为此,我们开发了一个新的区域感知型几何变换网络(region-aware geometric transform network),在一个通用框架中执行这些多任务。我们在户外KITTI和室内ScanNet数据集上的结果证明了我们网络在生成场景几何的高质量合成视图方面的有效性,从而超越了最先进的方法。
arXiv:https://arxiv.org/abs/1804.06008
Motion Capture
ICRA 2018
《Human Motion Capture Using a Drone》

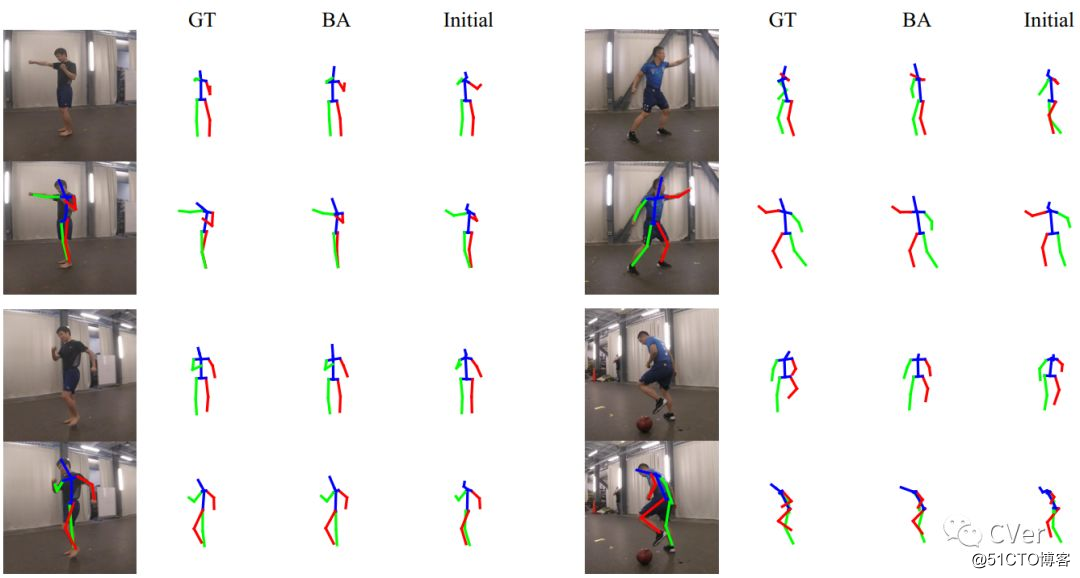
Abstract:目前的动作捕捉(MoCap)系统通常需要标记和多个校准摄像头,这些摄像头只能在受限环境中使用。在这项工作中,我们介绍了一款基于无人机的3D人体模型系统。该系统只需要具有自主飞行无人机和板载RGB相机,并可用于各种室内和室外环境。重建算法被开发用于从无人机记录的视频恢复全身运动。 我们认为,除了跟踪移动主体的能力之外,飞行无人机还提供快速变化的视点,这对于运动重建是有益的。 我们使用我们新的DroCap数据集评估拟议系统的准确性,并使用消费无人机在野外证明其适用。
arXiv:https://arxiv.org/abs/1804.06112
github:https://github.com/daniilidis-group/drocap
注:脑洞好大的研究,很cool

- [计算机视觉论文速递] 2018-05-19
- 2019计算机视觉论文精选速递(2019/1/23-2018/1/28)
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- 计算机视觉领域经典论文源码大全
- 图像处理和计算机视觉中的经典论文
- 为什么不去读顶级会议上的论文?适应于机器学习、计算机视觉和人工智能
- [ZZ]计算机视觉、机器学习相关领域论文和源代码大集合
- 可下载计算机视觉顶级论文的网址
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- 介绍几十篇我读过的顶会论文,大多数关于计算机视觉方向。
- 计算机视觉、机器学习相关领域论文和源代码大集合
- 计算机视觉会议论文入口Computer Vision Foundation open access
- 图像处理与计算机视觉基础相关领域的经典书籍以及论文
- 计算机视觉、机器学习相关领域论文和源代码
- 计算机视觉、机器学习相关领域论文和源代码大集合【转载】
- 21世纪初最有影响力的20篇计算机视觉期刊论文
- 超越ImageNet?李飞飞力赞高徒的视频描述研究入选计算机视觉最前沿的十大论文
- 计算机视觉、机器学习相关领域论文和源代码大集合
- 计算机视觉、机器学习相关领域论文和源代码大集合
- 图像处理和计算机视觉中的经典论文