[计算机视觉论文速递] 2018-05-19
导言
这篇文章有4篇论文速递信息,涉及人脸识别(综述)、人脸检测、3D 目标检测和姿态估计和目标检测等方向(含2篇CVPR 2018)。
CVer
编辑: Amusi
校稿: Amusi
前戏
Amusi 将日常整理的论文都会同步发布到 daily-paper-computer-vision 上。名字有点露骨,还请见谅。喜欢的童鞋,欢迎star、fork和pull。
直接点击“阅读全文”即可访问daily-paper-computer-vision。
link: https://github.com/amusi/daily-paper-computer-vision
Face
《Deep Face Recognition: A Survey》
2018 arXiv
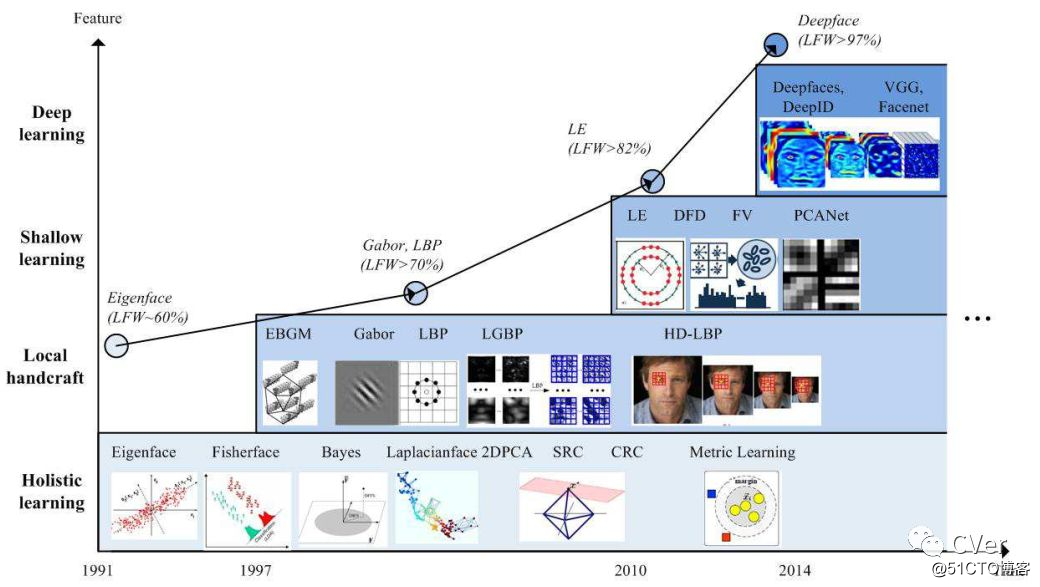
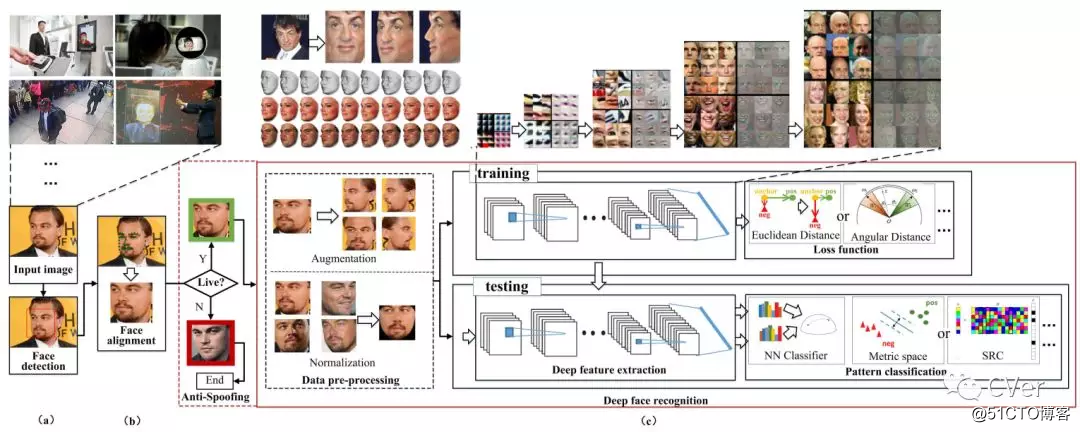
Abstract:在图形处理单元(GPU)、大量待标注数据和更高级算法的驱动下,深度学习使得计算机视觉领域受到了极大的冲击,并且使包括人脸识别(FR)在内的实际应用受益匪浅。Deep FR 方法利用深层网络学习更多的不同(discriminative)表征,显著地改善现有技术并超越人类表现(97.53%)。在本文中,我们提供深度FR方法的全面调查,包括数据,算法和场景。首先,我们总结了常用的训练和测试数据集。然后,数据预处理方法分为两类:“一对多增强”和“多对一标准化”。其次,对于算法,我们总结了现有技术方法中使用的不同网络架构和损失函数。第三,我们回顾了深度FR中的几个场景,比如视频FR,3D FR和不同年龄段(Cross-Age) FR。最后,强调了当前方法的一些潜在缺陷和几个未来方向。
arXiv:https://arxiv.org/abs/1804.06655
注:综述性文章,实属好评!
《SFace: An Efficient Network for Face Detection in Large Scale Variations》
2018 arXiv

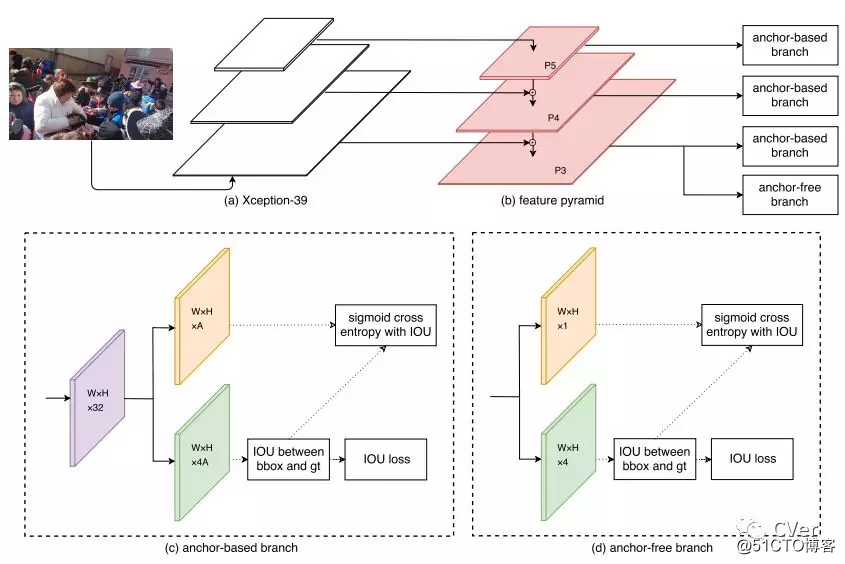
Abstract:人脸检测是许多应用程序(如人脸识别)的基础研究主题。特别是最近卷积神经网络的发展取得了令人印象深刻的进展。然而,广泛存在于高分辨率图像/视频中的大范围变化的问题在文献中尚未得到很好的解决。在本文中,我们提出了一种名为SFace的新算法,它有效地集成了基于 Anchor 的方法和无 Anchor 方法来解决尺度(scale)问题。还引入了称为4K-Face的新数据集来评估具有极大尺度变化的人脸检测的性能。SFace架构在新的4K-Face基准测试中显示出可喜的成果。 此外,我们的方法可以以每秒50帧(fps)的速度运行,标准WIDER FACE数据集的准确率为80%AP,其速度比现有算法高出近一个数量级,同时达到了比较性能。
arXiv:https://arxiv.org/abs/1804.06559
3D Object Detection and Pose Estimation
《Falling Things: A Synthetic Dataset for 3D Object Detection and Pose Estimation》
CVPR 2018 Workshop on Real World Challenges and New Benchmarks for Deep Learning in Robotic Vision


Abstarct:本文提出了一个名为Falling Things(FAT)的新数据集,用于推进机器人技术环境下的物体检测(Object Detectiion)和3D姿态估计的最新技术。通过对复杂构图和高图形质量的对象模型和背景进行综合组合,我们能够为所有图像中的所有对象生成具有精确三维姿态标注的照片真实感图像。我们的数据集包含来自YCB数据集的21个家庭对象的60k注释照片。对于每个图像,我们为所有对象提供3D姿势,每像素类分割以及2D / 3D边界框坐标。为了便于测试不同的输入模式,我们提供单目和立体双目 RGB图像以及配准(registered)的密集深度图像。 我们详细描述了数据的生成过程和统计分析。
arXiv:https://arxiv.org/abs/1804.06534
datasets:http://research.nvidia.com/publication/2018-06_Falling-Things
Object Detection
《Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization》
CVPR 2018 Workshop on Autonomous Driving
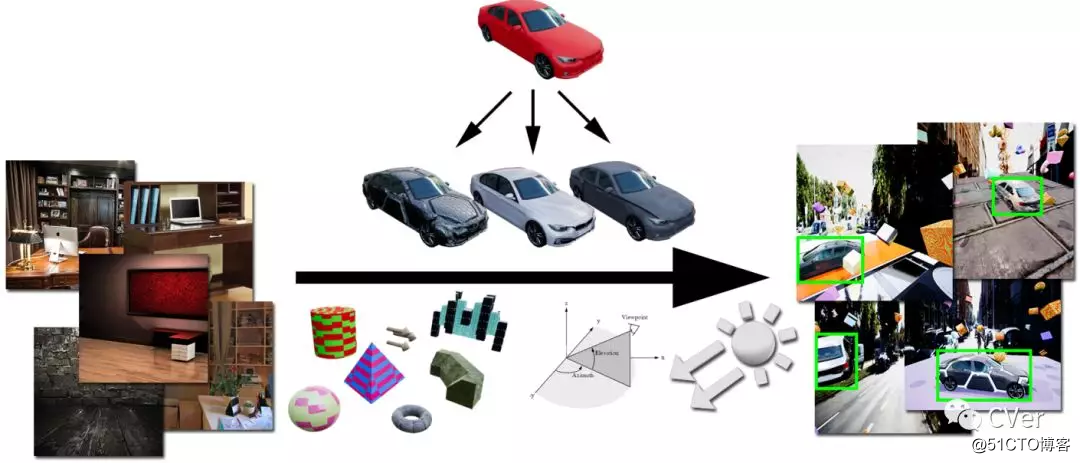

Abstract:我们提出了一种用于训练用于使用合成图像进行物体检测的深度神经网络的系统。为了解决真实世界数据的变化问题,系统依赖于域随机化技术(domain randomization),其中模拟器(simulator)的参数(例如照明,姿态,物体纹理等)以非现实的方式随机化,迫使神经网络学习感兴趣对象的基本特征。我们探索这些参数的重要性,表明可以仅使用非艺术性生成的合成数据生成具有引人注目的性能的网络。通过对实际数据进行额外的微调,网络比单独使用真实数据的性能更好。这个结果为使用低成本的合成数据训练神经网络提供了可能性,同时避免了收集大量手工标注的真实世界数据或生成高保真度合成世界(high-fidelity synthetic worlds)的需求 - 这两者都是许多应用的瓶颈。该方法在KITTI数据集上对汽车的边界框检测进行评估。

- 2019计算机视觉论文精选速递(2019/1/23-2018/1/28)
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- Paper之CVPR&ICCV&ECCV:2009年~2019年CVPR&ICCV&ECCV(国际计算机视觉与模式识别会议&国际计算机视觉大会&欧洲计算机视觉会议)历年最佳论文简介及其解读
- 计算机视觉领域经典论文源码大全
- 图像处理和计算机视觉中的经典论文
- 为什么不去读顶级会议上的论文?适应于机器学习、计算机视觉和人工智能
- [ZZ]计算机视觉、机器学习相关领域论文和源代码大集合
- 可下载计算机视觉顶级论文的网址
- 计算机视觉、机器学习相关领域论文和源代码大集合--持续更新
- 介绍几十篇我读过的顶会论文,大多数关于计算机视觉方向。
- 计算机视觉、机器学习相关领域论文和源代码大集合
- 计算机视觉会议论文入口Computer Vision Foundation open access
- 图像处理与计算机视觉基础相关领域的经典书籍以及论文
- 计算机视觉、机器学习相关领域论文和源代码
- 计算机视觉、机器学习相关领域论文和源代码大集合【转载】
- 21世纪初最有影响力的20篇计算机视觉期刊论文
- 超越ImageNet?李飞飞力赞高徒的视频描述研究入选计算机视觉最前沿的十大论文
- 计算机视觉、机器学习相关领域论文和源代码大集合
- 计算机视觉、机器学习相关领域论文和源代码大集合
- 图像处理和计算机视觉中的经典论文